

A Detailed Guide- Parkinson's Disease Identification Model

Table of Contents
Introduction
Early detection of Parkinson's disease, a neuro degenerative condition, presents major obstacles. Biomedical measurements connected to voice provide a possible non-invasive diagnostic approach. In this work, we use a Support Vector Machine (SVM) model—which is well-known for its effectiveness in classifying large, complicated datasets—to identify patterns in a dataset that includes different speech measurements from people who have Parkinson's disease and those who do not.
The SVM is the best option for this binary classification task because of its adaptability, sensitivity to feature scaling, and capacity to handle high-dimensional spaces. The following investigation illustrates the possibilities for machine learning to assist in the early detection of Parkinson's disease by exploring data analysis, preprocessing procedures, SVM model training, and prediction system construction.
This tutorial is for ML researchers, Product Managers,Healthcare Professionals, Data Scientist and Patients and Caregivers who want to build a Parkinson's disease detection model.
About Dataset
The dataset comprises biomedical voice measurements from 31 individuals, 23 of whom have Parkinson's disease (PD). Each row corresponds to one of 195 voice recordings, with each column representing a specific voice measure. The primary objective is to distinguish between healthy individuals (status 0) and those with PD (status 1).
The dataset is provided in ASCII CSV format, and the first column contains the name and recording number of the subject. Notably, there are approximately six recordings per patient.
The attribute information includes various measures related to vocal fundamental frequency (MDVP:Fo(Hz), MDVP:Fhi(Hz), MDVP:Flo(Hz)), several measures of variation in fundamental frequency (MDVP:Jitter, MDVP:RAP, MDVP:PPQ, Jitter:DDP), measures of variation in amplitude (MDVP:Shimmer, Shimmer:APQ3, Shimmer:APQ5, Shimmer:DDA), two measures of the ratio of noise to tonal components in the voice (NHR, HNR), and various nonlinear complexity measures (RPDE, D2, DFA).
The dataset aims to contribute to the discrimination between healthy and PD individuals, with potential applications in telemonitoring of Parkinson's disease.
Hands-on Tutorial
Here are steps that we'll follow to build our model from scratch.
Outline
1.Importing Dependencies
2.Data Collection and Analysis
3.Data Preprocessing
4.Training the Model
5.Model Evaluation
6.Prediction
7.Testing
1.Importing Dependencies
In this section, essential libraries are imported to facilitate various tasks throughout the machine learning process. NumPy and Pandas are fundamental for numerical operations and data manipulation, respectively. train_test_split is crucial for dividing the dataset into training and testing sets. StandardScaler is employed for standardizing the features, ensuring they are on a consistent scale. svm introduces the Support Vector Machine module, and accuracy_score will be utilized to assess the model's accuracy.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn import svm
from sklearn.metrics import accuracy_score
2.Data Collection and Analysis
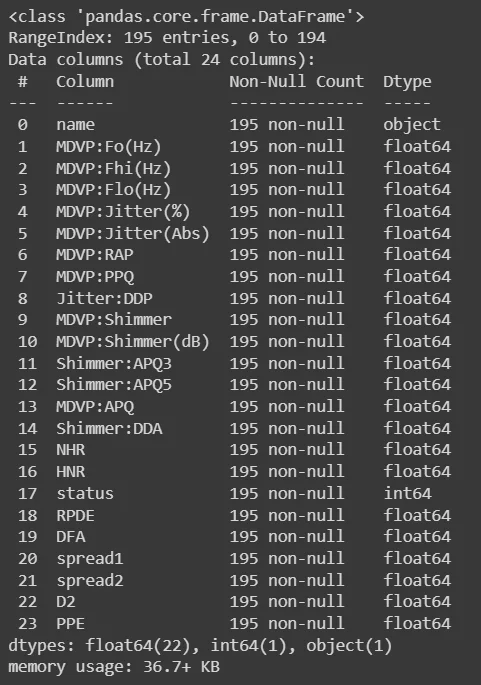
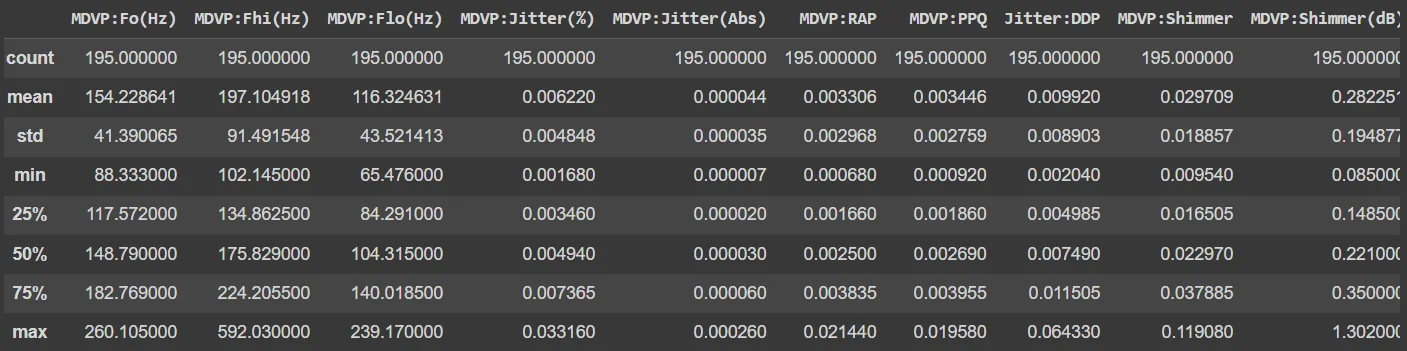
This section involves loading the dataset into a Pandas dataframe for structured analysis. The head() function displays the initial rows, offering a snapshot of the dataset. The shape attribute provides the dataset's dimensions, while info() furnishes details about data types and null values. describe() generates statistical summaries of the dataset. Additionally, the distribution of the target variable ('status') is inspected using value_counts(), and the mean values for different classes are computed through groupby('status').mean().
#loading the data from csv file to a pandas dataframe
parkinsons_data = pd.read_csv('/content/parkinsons dataset.csv')
#printing the first 5 rows of the datframe
parkinsons_data.head()
#no of rows and column in the dataframe
parkinsons_data.shape

#getting more information about the dataset
parkinsons_data.info()
#we dont have any null values
#getting some statistical measures about the data
parkinsons_data.describe()
#distribution of target variable
parkinsons_data['status'].value_counts()
#1--->Parkinson's Positive
#0--->Healthy

#grouping the data based on target variable
parkinsons_data.groupby('status').mean()
3.Data Pre-processing
Data pre-processing is critical for preparing features and labels for model training. In this stage, unnecessary columns, such as 'name', are dropped. The dataset is then split into training and testing sets using train_test_split. Standardization, achieved through the StandardScaler, ensures uniformity in feature scales, preventing certain features from dominating the model training process.
#Data Pre-processing
#Separating the features and the target
X = parkinsons_data.drop(columns = ['name','status'],axis=1)
Y = parkinsons_data['status']
print(X)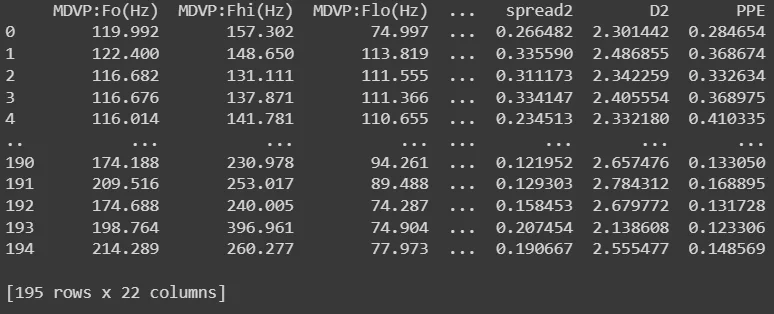
print(Y)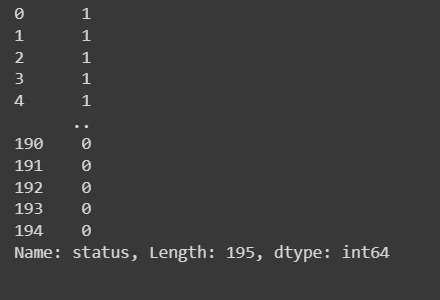
#Splitting the data to training data & test data
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.2,random_state=2)
print(X.shape, X_train.shape, X_test.shape)
#Data Standardization
scaler = StandardScaler()
scaler.fit(X_train)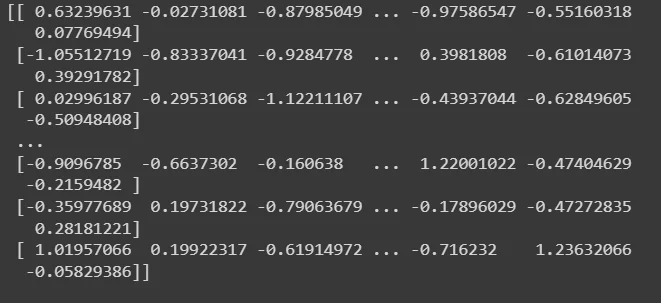
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
print(X_train)
Model Training
The code initializes a Support Vector Machine (SVM) model with a linear kernel using svm.SVC(kernel='linear'). The model is then trained on the standardized training data using fit(X_train, Y_train). SVM is a powerful algorithm for classification tasks, and the choice of a linear kernel implies an assumption that the data is linearly separable.
#Support Vector Machine Model
model = svm.SVC(kernel='linear')
#training the svm model with training data
model.fit(X_train, Y_train)
Model Evaluation
Model evaluation is crucial to understanding its performance. Predictions are made on both the training and test datasets using predict(), and the accuracy of these predictions is calculated using accuracy_score. Comparing predicted labels with true labels provides insights into how well the model generalizes to new, unseen data.
#accuracy score on training data
X_train_prediction = model.predict(X_train)
training_data_accuracy = accuracy_score(Y_train, X_train_prediction)
print('Accuracy score of training data : ', training_data_accuracy)
#accuracy score on test data
X_test_prediction = model.predict(X_test)
training_data_accuracy = accuracy_score(Y_test, X_test_prediction)
print('Accuracy score of test data : ', training_data_accuracy)
Building a Predictive System
In the final section, a predictive system is constructed. An example input data point is created, converted to a numpy array, reshaped, and then standardized using the scaler fitted on the training data. The SVM model is then employed to predict whether the individual has Parkinson's Disease or not. The result is printed to the console, allowing for an interpretation of the model's prediction.
#Building a Predictive System
#input data of phon_R01_S06_6 which status is 1 ---> Parkinson disease
input_data =(162.56800,198.34600,77.63000,0.00502,0.00003,0.00280,
0.00253,0.00841,0.01791,0.16800,0.00793,0.01057,0.01799,
0.02380,0.01170,25.67800,0.427785,0.723797,-6.635729,
0.209866,1.957961,0.135242)
#changing input data to a numpy array
input_data_as_numpy_array = np.asarray(input_data)
#reshape the numpy array
input_data_reshaped = input_data_as_numpy_array.reshape(1,-1)
#standardizing the data
standard_data = scaler.transform(input_data_reshaped)
#prediction
prediction = model.predict(standard_data)
print(prediction)
if (prediction[0]==0):
print("The person does not have Parkinson's Disease")
else:
print("The person have Parkinson's Disease")

Conclusion
The use of a Support Vector Machine (SVM) opens up a promising new field in Parkinson disease identification. The ability of SVMs to distinguish between healthy and afflicted people based on voice measurements was made clear by this blog tour. The effects are felt in all facets of healthcare, from early patient identification to more efficient procedures for medical staff. In addition to demonstrating the potential of machine learning, this nexus of technology and healthcare opens the door for revolutionary developments in biomedical technologies. As we wrap up, the SVM-based model shows promise not only as a tool for precise forecasting but also as a driver for a time when technology will be a major factor in changing the face of disease detection and treatment.
Frequently Asked Questions
1.How can AI help with Parkinson's?
Within minutes, individuals suffering from Parkinson's disease can receive remote assistance in determining the intensity of their symptoms thanks to an artificial intelligence technology.
2.What technology is used to detect Parkinson's disease?
No particular lab or imaging test can identify Parkinson's disease (PD). However, several tests can be performed to confirm the diagnosis of Parkinson's disease (PD) or rule out other illnesses that can resemble the disease, such as blood testing, MRI brain imaging, and dopamine transporter scans (DaT scans).

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
