

VRP-SAM: Image Segmentation With Visual Reference Prompts


Table of Contents
- Introduction
- What is VRP-SAM?
- Architecture of VRP-SAM
- Meta-Learning Strategy in VRP-SAM
- Performance and Evaluation
- Applications and Use Cases
- Advantages Over SAM
- Conclusion
- FAQ
Introduction
The Segment Anything Model (SAM) has emerged as a powerful tool in the field of image segmentation. In essence, image segmentation refers to the process of partitioning an image into distinct regions that correspond to specific objects or features. SAM excels at this task, offering a versatile approach to segmenting a wide range of objects within images.
What is VRP-SAM?

VRP-SAM (Visual Reference Prompt-Segment Anything Model) is an advanced extension of the Segment Anything Model (SAM).
While SAM revolutionized the field of image segmentation with its universal and interactive approach, VRP-SAM takes it a step further by integrating Visual Reference Prompts (VRPs) to significantly enhance segmentation performance, especially in complex scenarios.
VRP-SAM introduces the concept of Visual Reference Prompts, which are annotated reference images that guide the segmentation process.
These reference images provide semantic context and detailed information about the target objects, allowing VRP-SAM to perform more accurate and efficient segmentation.
Formats of Visual Reference Prompts: VRPs can be provided in various annotation formats, making the model highly adaptable and user-friendly.
Point: Specific locations on the object.
Box: Bounding boxes around the object.
Scribble: Rough scribbles indicating the object’s boundaries.
Mask: Detailed masks outlining the object.
Architecture of VRP-SAM
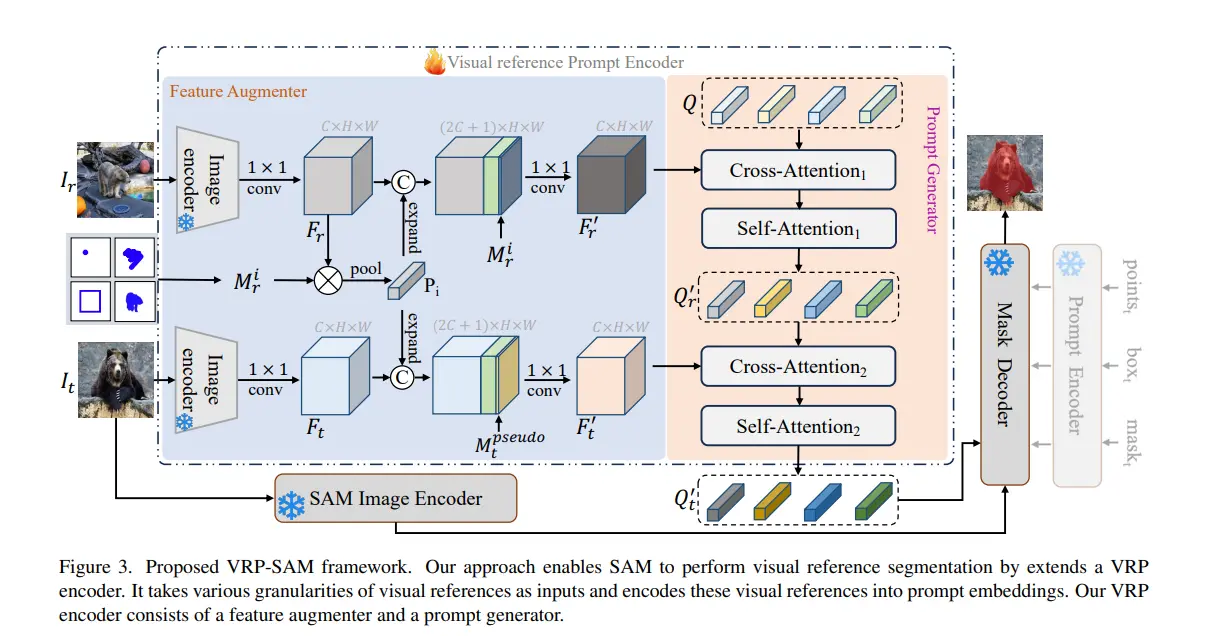
VRP-SAM (Visual Reference Prompt-Segment Anything Model) has a sophisticated architecture designed to integrate Visual Reference Prompts (VRPs) effectively. This section delves into the key components of the architecture: the Visual Reference Prompt (VRP) encoder, image encoder, prompt encoder, and mask decoder.
1. Visual Reference Prompt (VRP) Encoder: The VRP encoder is a novel addition to the architecture that plays a crucial role in enhancing segmentation performance.
It is designed to process annotated reference images and encode them into a semantic space that aligns with the target images. This encoding allows the model to utilize the semantic similarities between reference and target images, providing valuable contextual information for segmentation.
2. Image Encoder: The image encoder is responsible for extracting deep features from both the reference and target images. VRP-SAM uses a Vision Transformer (ViT) for this purpose. The ViT is chosen for its ability to capture rich and relevant information from images, which is crucial for accurate segmentation. The extracted features serve as the foundation for the subsequent stages of the segmentation process.
3. Prompt Encoder: The prompt encoder generates embeddings from user-provided annotations, such as points, bounding boxes, scribbles, and masks. These annotations serve as prompts that guide the segmentation process.
The prompt encoder translates these annotations into a format that the model can use to influence the segmentation, ensuring that the model’s output aligns with the user’s intent.
4. Mask Decoder: The mask decoder is the final component that produces the segmentation masks. It integrates the image features extracted by the image encoder and the prompt embeddings generated by the prompt encoder. The mask decoder processes this combined information to generate high-quality segmentation masks that accurately delineate the objects in the target images.
Meta-Learning Strategy
To further enhance its performance, VRP-SAM employs a meta-learning strategy. This strategy is designed to improve the model's generalization capabilities, enabling it to handle a wide range of objects and scenarios, including those it has not encountered during training.
1. Prototype Extraction: The meta-learning strategy begins with the extraction of prototypes from the annotated reference images. Prototypes are representative features that encapsulate the essential characteristics of the target objects.
These prototypes are extracted using the VRP encoder and serve as a summary of the objects' key attributes.
2. Interaction with Target Images: Once the prototypes are extracted, the model uses learnable queries to interact with the target images. These queries are designed to retrieve relevant information from the target images based on the prototypes.
This interaction helps the model generate prompt embeddings that are tailored to the specific context of the target images.
3. Generating Prompt Embeddings: The learnable queries and the interaction with the target images result in the generation of prompt embeddings. These embeddings capture the semantic relationship between the reference and target images, providing a rich source of information for the segmentation process.
The prompt embeddings are then used by the mask decoder to guide the generation of segmentation masks.
4. Improved Generalization: The meta-learning strategy significantly enhances the model's ability to generalize to unseen objects and domains. By leveraging the semantic similarities between reference and target images, VRP-SAM can effectively handle objects it has not seen during training.
This capability is particularly valuable in cross-domain applications, where the model may encounter a diverse array of objects and scenarios.
5. Efficient Segmentation: The use of VRPs and the meta-learning strategy also contribute to the efficiency of the segmentation process.
The model can quickly adapt to new objects and scenes by leveraging the information provided by the reference images, reducing the need for extensive user input.
This efficiency is especially important in scenarios involving numerous or complex objects, where traditional segmentation methods may struggle.
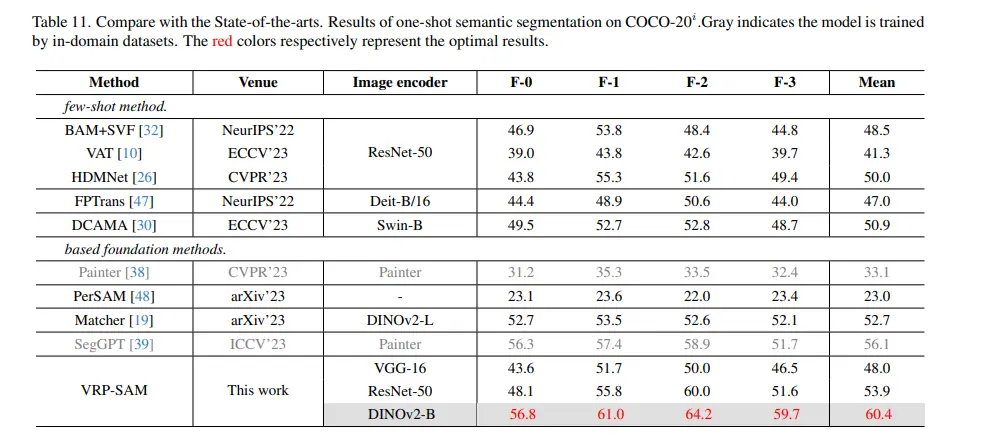
6. Performance Evaluation: The effectiveness of VRP-SAM's architecture and meta-learning strategy is validated through rigorous evaluation of various datasets, such as Pascal-5i and COCO-20i.
The empirical results demonstrate that VRP-SAM achieves state-of-the-art performance in visual reference segmentation, excelling in both accuracy and efficiency.
Performance and Evaluation
VRP-SAM's effectiveness has been thoroughly evaluated using established benchmark datasets to assess its segmentation performance and generalization capabilities.
Datasets
The evaluation primarily focused on two widely used datasets for image segmentation tasks:
Pascal VOC (PASCAL): This dataset is a popular benchmark containing a diverse collection of images with annotations for various object categories. It serves as a reliable test for a model's ability to handle a wide range of object types.
COCO (Common Objects in Context): COCO is another extensive dataset featuring a rich collection of images with complex scenes and numerous objects. It provides a challenging test for segmentation models, especially when dealing with intricate relationships between objects and cluttered backgrounds.
Results
VRP-SAM has demonstrated remarkable performance in visual reference segmentation tasks across both the PASCAL VOC and COCO datasets. Here are some key takeaways from the evaluation:
State-of-the-Art Performance: VRP-SAM achieved state-of-the-art results in visual reference segmentation. This signifies its ability to outperform existing methods when segmenting objects based on visual and textual cues.
Strong Generalization Capabilities: The meta-learning strategy employed by VRP-SAM played a crucial role in its success. VRP-SAM exhibited strong generalization capabilities, allowing it to segment unseen objects and perform well in cross-domain scenarios where the training and test data might differ in visual styles or contexts.
Rapid Segmentation: VRP-SAM is efficient in processing a large number of images for segmentation tasks. This makes it suitable for real-world applications where processing speed is a critical factor.
These results highlight the effectiveness of VRP-SAM in overcoming the limitations of traditional SAM. By incorporating visual references and leveraging meta-learning, VRP-SAM delivers superior segmentation performance, particularly when dealing with complex scenes and numerous images.
Applications and Use Cases
VRP-SAM's capabilities open doors to various applications in fields that heavily rely on image segmentation tasks. Here's a glimpse into its potential real-world uses:
Medical Imaging: VRP-SAM can be instrumental in medical image analysis. By providing reference images of specific anatomical structures, doctors can leverage VRP-SAM to segment tumors, organs, or other regions of interest within medical scans with improved accuracy. This can lead to more informed diagnoses and treatment plans.
Autonomous Driving: VRP-SAM can play a role in enhancing the performance of autonomous vehicles. By incorporating visual references to specific objects like traffic signs or pedestrians, VRP-SAM can assist self-driving cars in segmenting these objects more accurately within the driving environment. This can contribute to safer and more reliable autonomous navigation.
Image Editing: VRP-SAM can be integrated into image editing tools. Users could leverage visual references to easily select specific objects or regions within an image for editing purposes. This can significantly improve the efficiency and precision of image editing workflows.
Content Creation: VRP-SAM holds promise for content creation tools. Artists and designers could utilize visual references to segment specific objects within images for manipulation or composition. This can streamline the process of creating visually compelling content.
Advantages Over SAM

VRP-SAM offers several advantages over the original SAM, particularly in terms of efficiency and accuracy for segmentation tasks:
Enhanced Performance with Complex Scenes: VRP-SAM's ability to handle visual references allows for more precise segmentation within intricate scenes with numerous objects. SAM might struggle in such scenarios, while VRP-SAM tackles them effectively.
Improved Generalization: The meta-learning strategy employed by VRP-SAM equips it to adapt to new and unseen scenarios. This is a significant improvement over SAM, which might require retraining for specific tasks not encountered during initial training.
Greater Flexibility: VRP-SAM allows for more flexibility in guiding the segmentation process. Users can provide diverse visual references, catering to various object types and segmentation goals. This surpasses SAM's reliance solely on textual descriptions.
Faster Processing for Large Datasets: VRP-SAM demonstrates efficient processing capabilities when dealing with numerous images. This makes it suitable for large-scale segmentation tasks compared to SAM, which might encounter limitations when handling extensive datasets.
Integration of VRP-SAM in Labellerr
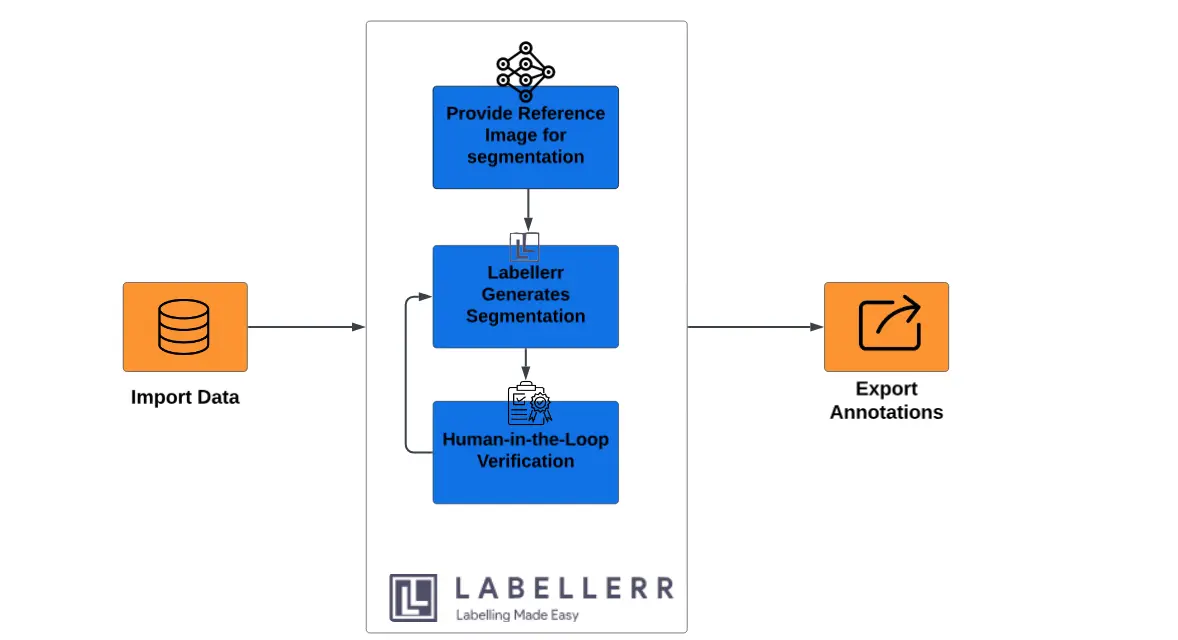
Labeller has taken a step forward in image segmentation by integrating VRP-SAM (Visual Reference Prompt Segmentation with SAM). This innovative approach leverages the power of the Segment Anything Model (SAM) and visual reference prompts to achieve efficient and accurate segmentation. VRP-SAM empowers SAM to understand specific objects based on annotated reference images, leading to more precise segmentation results.
Here’s how the VRP-SAM model functions within its workflow:
- Import Data: Users start by importing their dataset into the Labellerr platform.
- Provide Reference Image with Prompt: Users then provide annotated reference images along with specific annotation prompts. These reference images serve as visual guides for the segmentation task.
- Automatic Segmentation: Labeller's VRP-SAM technology utilizes the provided reference images to automatically segment objects within the dataset.
- Human-in-the-Loop Verification: Human annotators verify and refine the automated segmentations to ensure accuracy and quality.
- Final Dataset Output: The finalized annotated dataset, now accurately segmented and verified, is ready for further analysis or deployment in AI applications.
By combining VRP-SAM's automation with human expertise for verification and quality control, Labeller offers a powerful and efficient approach to image segmentation tasks. This integration streamlines the process, reduces manual effort, and enhances the overall accuracy of your segmentation project.
Conclusion
VRP-SAM represents a significant advancement in the field of image segmentation, building upon the foundational capabilities of SAM with the innovative integration of Visual Reference Prompts and a meta-learning strategy.
This enhancement allows VRP-SAM to address the limitations of its predecessor, providing superior accuracy and efficiency in segmenting complex and densely populated scenes.
From medical imaging to autonomous driving, and from image editing to agriculture and robotics, VRP-SAM offers significant improvements in efficiency and accuracy, making it a valuable tool in both research and practical applications.
As the demand for high-quality segmentation continues to grow, VRP-SAM stands out as a powerful solution that sets a new benchmark in the field, paving the way for future innovations and applications.
Frequently Asked Questions
1. What is VRP-SAM?
VRP-SAM stands for Visual Reference Prompt-Segment Anything Model. It is an advanced image segmentation model that extends the capabilities of the Segment Anything Model (SAM) by incorporating Visual Reference Prompts (VRPs) to improve segmentation accuracy and efficiency, particularly in complex scenes.
2. How does VRP-SAM differ from SAM?
VRP-SAM differs from SAM primarily through the integration of Visual Reference Prompts (VRPs).
While SAM relies on user-provided prompts for segmentation, VRP-SAM uses annotated reference images to provide additional context and semantic information, leading to better performance in complex and densely populated scenes.
VRP-SAM also employs a meta-learning strategy to enhance generalization to unseen objects and domains.
3. What are Visual Reference Prompts (VRPs)?
Visual Reference Prompts (VRPs) are annotated reference images that guide the segmentation process in VRP-SAM. These prompts can be provided in various formats, including points, bounding boxes, scribbles, and masks, which help the model accurately segment objects by leveraging semantic context from the reference images.
4. What are the key components of VRP-SAM’s architecture?
The key components of VRP-SAM’s architecture include the Visual Reference Prompt (VRP) encoder, image encoder, prompt encoder, and mask decoder. The VRP encoder processes reference images, the image encoder extracts features from both target and reference images, the prompt encoder generates embeddings from user annotations, and the mask decoder produces the final segmentation masks.
Reference:
1) VRP-SAM: SAM with Visual Reference Prompt(Paper).
2) VRP-SAM: SAM with Visual Reference Prompt(Github).

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
