

ViTMatte: A Leap Forward in Image Matting with Vision Transformers


Table of Contents
- Introduction
- About VitMatte
- Overall Architecture
- Performance and Evaluation
- Conclusion
- Frequently Asked Questions
Introduction
Vision Transformers (ViTs) have recently demonstrated impressive capabilities in various computer vision tasks, owing to their robust modeling prowess and extensive pretraining. However, the challenge of image matting has remained unconquered by ViTs.
The hypothesis is that ViTs could also enhance the performance of image matting. A novel ViT-based matting system, ViTMatte, has been introduced to address this hypothesis. This approach incorporates two main components:
- A combination of a hybrid attention mechanism and a convolutional "neck" is employed to assist ViTs in achieving a remarkable balance between performance and computational efficiency when tackling matting tasks.
- A "detail capture module" is also introduced, comprising straightforward and lightweight convolutional operations. This module serves to supplement the intricate information necessary for image matting.
To their knowledge, ViTMatte is pioneering in leveraging ViTs for image matting with a streamlined adaptation. ViTMatte inherits numerous advantageous features from ViTs, including a diverse array of pretraining strategies, a simplified architectural design, and adaptable inference techniques.
ViTMatte is evaluated on the widely recognized benchmark datasets Composition1k and Distinctions-646, which are commonly used to assess image matting techniques.
The results attained demonstrate that ViTMatte achieves state-of-the-art performance, surpassing previous matting methodologies by a substantial margin.
In this blog, we aim to discuss image matting and a new SOTA foundation model, ViTMatte.

Figure: Image Matting
Image Matting
Image matting is crucial for precisely determining the foreground/background within images and video content. This technique holds significant importance in the realm of image and video editing, especially in the context of film production, where it is employed to craft visual effects
When provided with an image I, our objective is to generate a matte comprising transparency values (α) at each pixel, where αi falls within the range [0, 1].
This matte allows us to decompose the color value Ii at each pixel into a combination of two components: one originating from a foreground color Fi and the other from a background color Bi. Subsequently, by combining these components, we reconstruct the color values for each pixel in our original image.
Ii = αiFi + (1 − αi)Bi
About VitMatte
In the discussion of ViTMatte and its comparison to other applications of plain vision transformers, the existing applications utilize a straightforward feature pyramid developed by ViTDet.
In contrast, a distinct adaptation approach is introduced, particularly tailored for image matting, known as ViTMatte. This approach involves the utilization of basic convolutional layers to extract intricate details from the image, with the feature map generated by plain vision transformers being employed just once.

Figure: ViTMatte Pipeline
Concepts Related to VitMatte
To enhance clarity, we explain the concepts of "trimap" in image matting and "plain vision transformers."
Trimap in Image Matting
In natural image matting, trimaps serve as essential priors for distinguishing between foreground and background regions. A trimap is a manually labeled hint map used in image matting.
As depicted in the above figure, users outline the foreground and background in an image, leaving the matting algorithm to compute the transparency (often called alpha) values exclusively in the remaining unknown regions.
Trimap has been a widely used hint in natural image matting for a substantial period, both in traditional methods and in deep learning.
In the context of ViTMatte, we utilize trimaps in the form of grayscale images, denoted as T ∈ RH×W×1, where T(x,y) takes on the values:
- 0 for (x, y) in the background.
- 1 for (x, y) in the foreground.
- 0.5 for (x, y) in the unknown regions.
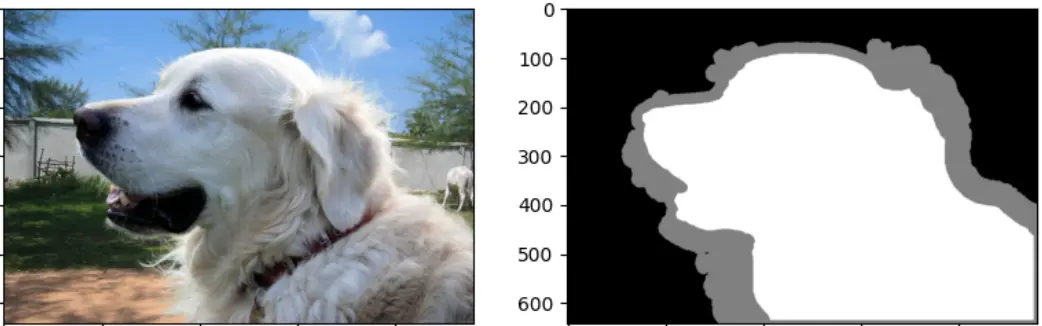
Figure: Image and Trimap
Plain Vision Transformers
When referring to plain vision transformers, we specifically mean the architectural model proposed by Dosovitskiy et al., distinct from other variants designed for vision tasks.
This non-hierarchical architecture provides an output with the same size as the input image. Given an input image x ∈ RH×W×C, where (H, W) represents the image resolution and C is the number of channels, ViT converts it into a sequence of image tokens xp0 ∈ RN×(P^2×C) through a linear patch embedding layer.
Here, P denotes the patch size, and N = HW/P^2 denotes the count of image tokens. Vision transformers then process this image sequence.
A transformer layer consists of multi-head self-attention (MHSA) and MLP blocks, with residual connections and LayerNorm (LN) applied. The below equations illustrate a single layer of a vision transformer:
x'pl = MHSA(LN(xpl)) + xpl
xpl+1 = MLP(LN(x'pl)) + x'pl
In the context of a plain vision transformer, this generates a sequence of image tokens xp1, ..., xpL, where L represents the number of layers in the vision transformer. Typically, the final feature xpL is used as the output of the plain vision transformer.
Overall Architecture
The figure below illustrates the proposed ViTMatte system, an efficient image matting solution built on plain vision transformers.
The system takes as input an RGB image X, represented as X ∈ RH×W×3, along with its corresponding trimap T, denoted as T ∈ RH×W×1, which are concatenated channel-wise and fed into ViTMatte.
ViTMatte operates by extracting multi-level features using plain vision transformers and a detail capture module.
The plain vision transformer serves as the foundational feature extractor, producing a single feature map with a stride of 16. In addition, the detail capture module incorporates a series of convolutional layers, enabling the capture and integration of intricate details essential for image matting.
Notably, the design approach avoids the use of specialized techniques and instead relies on the upsampling and fusion of features at various scales to predict the final alpha matte, denoted as α ∈ RH×W×1.
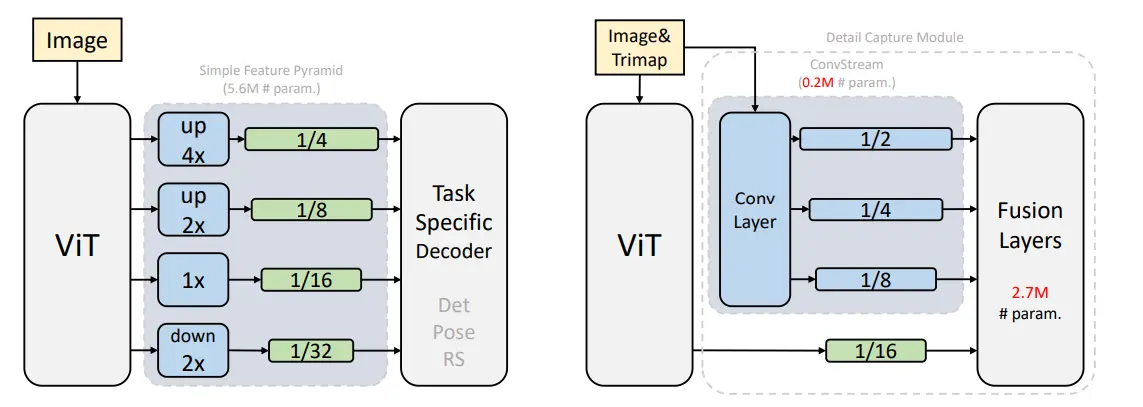
Figure: Comparison of Previous SOTA vs ViT architecture
Potential Applications
Picture matting finds applications across multiple industries, including entertainment, advertising, and e-commerce. In the realm of entertainment, especially in creating special effects and compositing for films and television productions, image matting is a pivotal tool.
Its primary function is to seamlessly integrate characters or objects into new backgrounds, contributing to the generation of authentic and believable visual effects.
The advertising and e-commerce sectors also heavily rely on image matting. By eliminating the background and achieving a refined, polished appearance, picture matting enhances the visual appeal of products in various industries.
For example, it is commonly employed to strip away backgrounds from clothing images, creating transparent product versions that can be superimposed onto diverse backgrounds for effective product promotion in online retail.
In the film and television industries, picture matting plays a vital role in compositing and special effects. It is extensively utilized to produce convincing visual effects, such as substituting a genuine background for a green screen or relocating an object to a new setting.
During post-production, image matting is a go-to technique for excluding unwanted characters or elements from a scene, contributing to the overall quality of the final product.
Performance and Evaluation
The quantitative outcomes for Composition-1k are presented in the table below. These metrics were exclusively assessed within the undisclosed regions of the trimap.
When compared to earlier approaches, the model in question surpasses all of them and attains a new state-of-the-art (SOTA) level of performance.
In table below, the comparison is drawn between the performance and parameter count of ViTMatte-S, ViTMatte, and preceding state-of-the-art methods. Notably, ViTMatte demonstrates superior performance despite having a smaller model size.
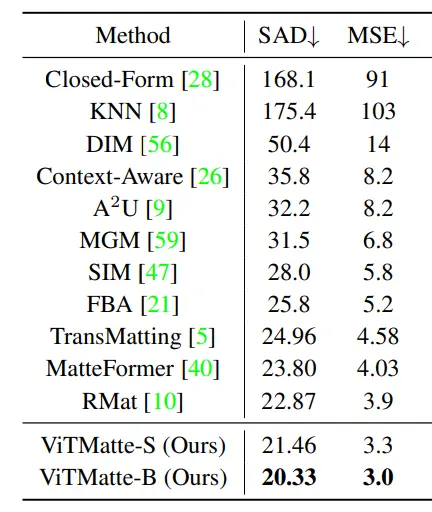
Figure: Comparison of Different Models on Composition-1k Dataset
Also, ViTMatte-S achieves superior outcomes compared to prior matting techniques while employing a reduced number of parameters.
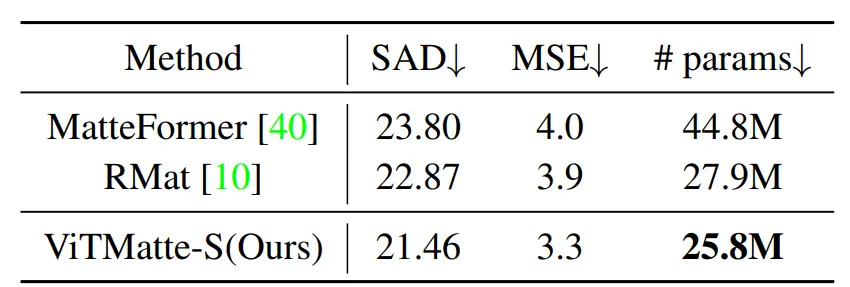
Figure: Comparison of the number of parameters
Conclusion
ViTMatte represents a groundbreaking approach in the world of image matting, harnessing the power of Vision Transformers (ViTs) to achieve state-of-the-art results. While ViTs have excelled in various computer vision tasks, image matting remained a challenging frontier until ViTMatte came into play.
This novel system incorporates a hybrid attention mechanism and a convolutional "neck" to strike a balance between performance and computational efficiency, effectively enhancing the capabilities of ViTs in image matting.
One key innovation of ViTMatte is its "detail capture module," a set of lightweight convolutional operations designed to extract intricate details vital for precise image matting.
The architecture efficiently leverages the features generated by plain vision transformers, ensuring that even fine-grained information is incorporated into the alpha matte. This holistic approach, along with the streamlined adaptation of ViTs, positions ViTMatte as a pioneering solution in the field.
ViTMatte's performance is rigorously evaluated on benchmark datasets, Composition1k and Distinctions-646, commonly used for image matting assessments. The results underscore its supremacy, surpassing previous matting techniques by a substantial margin.
Notably, ViTMatte achieves this superior performance while using fewer parameters, emphasizing its efficiency and effectiveness in the domain of image matting, with potential applications spanning entertainment, advertising, and e-commerce.
Frequently Asked Questions
1. What is Image Matting?
Image matting refers to precisely estimating the foreground element within images and videos. This technique holds significant importance in various applications, particularly within the domains of image and video editing, where it plays a pivotal role in tasks such as crafting visual effects in film production.
2. What are some applications of Image Matting?
Image matting finds its utility in a multitude of domains within image and video editing, encompassing tasks such as object segmentation, image composition, and the realm of virtual reality.
3. What is the Difference between Image Segmentation and Matting?
The distinction between segmentation and matting lies in their respective objectives. While image segmentation involves determining whether a pixel belongs to either the foreground or background, image matting takes it a step further by precisely estimating the pixel's opacity within the foreground.
From a technical perspective, image matting presents a greater challenge compared to image segmentation.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
