

Vision Transformers For Object Detection: A Complete Guide
Learn how ViT object detection models outperform traditional architectures by leveraging hierarchical layers. Discover the benefits of vision transformers in image segmentation and object recognition with detailed steps for fine-tuning and implementation


Vision transformers (ViTs) have revolutionized many areas of computer vision, but there's one domain where they’ve struggled—object detection.
While ViTs excel in tasks like image classification, they encounter challenges when detecting objects of varying sizes.
This is where convolutional neural networks (CNNs) have traditionally had the upper hand, thanks to their hierarchical structure that naturally supports multi-scale feature extraction.
CNNs generate representations at different scales within an image, making them ideal for detecting objects of diverse sizes.
Recognizing this advantage, researchers have adapted transformers for object detection by integrating similar hierarchical features.
Many ViT variations now incorporate a backbone that supports detection-specific components like heads or necks.
Another, more straightforward approach is to add hierarchical layers at the end of a standard ViT backbone, allowing models to leverage pretrained ViTs without a complete network overhaul, even if they weren’t originally designed for object detection.
In this blog, we’ll walk through the process of building a custom Vision Transformer model and fine-tuning it on specific data.
Our primary goal is to explore the pipeline and understand the code structure needed to implement it effectively.
You can refer here for a quick recap of what ViTs are.
Table of Contents
About Dataset
The Caltech-101 dataset stands as a popular resource for tasks related to object detection. It comprises approximately 9,000 images representing 101 distinct object categories.

Figure: Sample Images from Caltech Dataset
These categories were thoughtfully chosen to include a broad range of real-world objects, ensuring that the dataset poses a significant challenge for object recognition algorithms. Here are some of its key characteristics:
- It consists of roughly 9,000 color images distributed across 101 different categories.
- The categories cover a diverse array of objects, including animals, vehicles, household items, and people.
- The number of images per category varies, typically from about 40 to 800.
- The images exhibit varying sizes, though most are of medium resolution.
The Caltech-101 dataset holds a prominent place in the machine-learning community and is extensively used for training and evaluating object recognition models.
It's worth noting that Caltech-101 does not come pre-divided into formal training and testing sets, unlike some datasets.
Users often tailor their own splits based on their specific requirements. Nevertheless, a common approach involves using a random subset of images for training (e.g., around 30 images per category) and reserving the remaining images for testing purposes.
Hands-on Tutorial
Before going on to the code, we look at this blog's prerequisites.
Pre-requisites
To proceed further, one should be familiar with:
- Python: All the below code will be written using Python.
- Pytorch: PyTorch, founded on the Torch library, is a machine learning framework utilized for tasks like computer vision and natural language processing.
- Colab: Colab, short for Google Colaboratory, is a free cloud-based platform that provides access to GPUs and allows collaborative coding in Python.
Tutorial
This blog requires TensorFlow 2.4 or higher and TensorFlow Addons, from which we import the AdamW optimizer.
pip install -U tensorflow-addonsWe then begin by importing the required libraries.
# Import NumPy for numerical computations
import numpy as np
# Import TensorFlow, a popular machine learning framework
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# Import TensorFlow Addons, which provides additional functionality for TensorFlow
import tensorflow_addons as tfa
# Import Matplotlib for data visualization
import matplotlib.pyplot as plt
# Import NumPy again (Note: Importing libraries twice is not necessary)
import numpy as np
# Import OpenCV for computer vision tasks
import cv2
# Import the os module for interacting with the operating system
import os
# Import SciPy's .mat file reader for handling MATLAB data files
import scipy.io
# Import shutil for file operations (e.g., copying, moving, deleting files)
import shutil
We then prepare our dataset. For this, we first have to download the data which is then followed by scaling it and preparing this in right format.
# Import NumPy for numerical computations
import numpy as np
# Import TensorFlow, a popular machine learning framework
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# Import TensorFlow Addons, which provides additional functionality for TensorFlow
import tensorflow_addons as tfa
# Import Matplotlib for data visualization
import matplotlib.pyplot as plt
# Import NumPy again (Note: Importing libraries twice is not necessary)
import numpy as np
# Import OpenCV for computer vision tasks
import cv2
# Import the os module for interacting with the operating system
import os
# Import SciPy's .mat file reader for handling MATLAB data files
import scipy.io
# Import shutil for file operations (e.g., copying, moving, deleting files)
import shutil
We then begin preparing our model. For this, we write code to develop a multilayer perceptron (MLP) by referring to the Keras example titled "Image classification with Vision Transformer."
def mlp(x, hidden_units, dropout_rate):
# Iterate through the list of hidden units
for units in hidden_units:
# Apply a Dense layer with the GELU activation function
x = layers.Dense(units, activation=tf.nn.gelu)(x)
# Apply a Dropout layer with a specified dropout rate
x = layers.Dropout(dropout_rate)(x)
# Return the final output after processing through the MLP
return x
Now, we know that transformer architecture generally requires positional embeddings along with an input token. In the case of nlp, it is much simpler as we have a position as an index of each word.
In the case of images, we tend to have image patches.
class Patches(layers.Layer):
def __init__(self, patch_size):
super().__init__()
self.patch_size = patch_size
# Override the 'get_config' function to ensure model saving compatibility
def get_config(self):
config = super().get_config().copy()
config.update(
{
"patch_size": patch_size,
}
)
return config
def call(self, images):
# Get the batch size of the input images
batch_size = tf.shape(images)[0]
# Extract image patches using TensorFlow's 'extract_patches' function
patches = tf.image.extract_patches(
images=images,
sizes=[1, self.patch_size, self.patch_size, 1],
strides=[1, self.patch_size, self.patch_size, 1],
rates=[1, 1, 1, 1],
padding="VALID",
)
# Reshape the patches to have the shape [batch_size, num_patches,
patch_size * patch_size * channels]
return tf.reshape(patches, [batch_size, -1, patches.shape[-1]])Now, for better understanding, we visualize these image patches.
# Define the size of the patches to be extracted from the input images
patch_size = 32
# Display the original image
plt.figure(figsize=(4, 4))
plt.imshow(x_train[0].astype("uint8")) # Display the first training image
plt.axis("off") # Turn off axis labels and ticks
# Extract patches from the image using the 'Patches' layer
patches = Patches(patch_size)(tf.convert_to_tensor([x_train[0]]))
# Print information about the image and patch sizes
print(f"Image size: {image_size} X {image_size}")
print(f"Patch size: {patch_size} X {patch_size}")
print(f"{patches.shape[1]} patches per image \n{patches.shape[-1]} elements per patch")
# Calculate the number of patches to be displayed in each row and column
n = int(np.sqrt(patches.shape[1]))
# Create a new figure for displaying the extracted patches
plt.figure(figsize=(4, 4))
# Iterate through and display each patch
for i, patch in enumerate(patches[0]):
ax = plt.subplot(n, n, i + 1) # Create a subplot
patch_img = tf.reshape(patch, (patch_size, patch_size, 3))
# Reshape the patch to image dimensions
plt.imshow(patch_img.numpy().astype("uint8")) # Display the patch as an image
plt.axis("off") # Turn off axis labels and ticks for the patch
Next, we form the Patch Encoder layer. The PatchEncoder layer performs a linear transformation on each patch, mapping it to a vector of dimensionality specified by "projection_dim."
Additionally, it introduces a position embedding that can be adjusted through training to the resulting vector.
class PatchEncoder(layers.Layer):
def __init__(self, num_patches, projection_dim):
super().__init__()
self.num_patches = num_patches
# Initialize a Dense layer for projection
self.projection = layers.Dense(units=projection_dim)
# Initialize an Embedding layer for position embeddings
self.position_embedding = layers.Embedding(
input_dim=num_patches, output_dim=projection_dim
)
# Override the 'get_config' function to ensure model saving compatibility
def get_config(self):
config = super().get_config().copy()
config.update(
{
"num_patches": num_patches,
"projection_dim": projection_dim,
}
)
return config
def call(self, patch):
# Create positions for the patches
positions = tf.range(start=0, limit=self.num_patches, delta=1)
# Perform projection and add position embeddings to the patches
encoded = self.projection(patch) + self.position_embedding(positions)
# Return the encoded patches
return encoded
Now, we form our ViT Model. Within the ViT model, there are several Transformer blocks. The MultiHeadAttention layer plays a vital role in performing self-attention on the sequence of image patches.
The results from both the encoded patches (through a skip connection) and the outputs of the self-attention layer are then normalized and passed into a multilayer perceptron (MLP).
The model ultimately produces a four-dimensional output, which signifies the object's bounding box coordinates.
def create_vit_object_detector(
input_shape,
patch_size,
num_patches,
projection_dim,
num_heads,
transformer_units,
transformer_layers,
mlp_head_units,
):
# Define the input layer for the model
inputs = layers.Input(shape=input_shape)
# Create patches from input images
patches = Patches(patch_size)(inputs)
# Encode the patches using the PatchEncoder layer
encoded_patches = PatchEncoder(num_patches, projection_dim)(patches)
# Create multiple layers of the Transformer block.
for _ in range(transformer_layers):
# Layer normalization 1
x1 = layers.LayerNormalization(epsilon=1e-6)(encoded_patches)
# Apply multi-head self-attention to the patches
attention_output = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=projection_dim, dropout=0.1
)(x1, x1)
# Skip connection 1
x2 = layers.Add()([attention_output, encoded_patches])
# Layer normalization 2
x3 = layers.LayerNormalization(epsilon=1e-6)(x2)
# Apply an MLP to the output
x3 = mlp(x3, hidden_units=transformer_units, dropout_rate=0.1)
# Skip connection 2
encoded_patches = layers.Add()([x3, x2])
# Create a [batch_size, projection_dim] tensor.
representation = layers.LayerNormalization(epsilon=1e-6)(encoded_patches)
representation = layers.Flatten()(representation)
representation = layers.Dropout(0.3)(representation)
# Add an additional MLP for feature extraction
features = mlp(representation, hidden_units=mlp_head_units, dropout_rate=0.3)
# Output layer with 4 neurons representing bounding box coordinates
bounding_box = layers.Dense(4)(features)
# Return the Keras model
return keras.Model(inputs=inputs, outputs=bounding_box)
Now, we train our model.
def run_experiment(model, learning_rate, weight_decay, batch_size, num_epochs):
# Define the optimizer with weight decay
optimizer = tfa.optimizers.AdamW(
learning_rate=learning_rate, weight_decay=weight_decay
)
# Compile the model using Mean Squared Error as the loss
model.compile(optimizer=optimizer, loss=keras.losses.MeanSquaredError())
# Set up a ModelCheckpoint to save the best model weights
checkpoint_filepath = "logs/"
checkpoint_callback = keras.callbacks.ModelCheckpoint(
checkpoint_filepath,
monitor="val_loss",
save_best_only=True,
save_weights_only=True,
)
# Train the model
history = model.fit(
x=x_train,
y=y_train,
batch_size=batch_size,
epochs=num_epochs,
validation_split=0.1,
callbacks=[
checkpoint_callback,
keras.callbacks.EarlyStopping(monitor="val_loss", patience=10),
],
)
return history
# Define input image shape and training hyperparameters
input_shape = (image_size, image_size, 3)
learning_rate = 0.001
weight_decay = 0.0001
batch_size = 32
num_epochs = 100
# Calculate the number of patches
num_patches = (image_size // patch_size) ** 2
# Define the dimensions and layers for the Vision Transformer (ViT) model
projection_dim = 64
num_heads = 4
transformer_units = [projection_dim * 2, projection_dim]
transformer_layers = 4
mlp_head_units = [2048, 1024, 512, 64, 32]
# Initialize a list to store training history
history = []
# Create a ViT-based object detection model
vit_object_detector = create_vit_object_detector(
input_shape,
patch_size,
num_patches,
projection_dim,
num_heads,
transformer_units,
transformer_layers,
mlp_head_units,
)
# Train the model and store the training history
history = run_experiment(
vit_object_detector, learning_rate, weight_decay, batch_size, num_epochs
)
Now when we have trained our model, we aim to evaluate it.
import matplotlib.patches as patches
# Save the ViT-based object detection model in the current path
vit_object_detector.save("vit_object_detector.h5", save_format="h5")
# Define a function to calculate Intersection over Union (IoU) for two bounding boxes
def bounding_box_intersection_over_union(box_predicted, box_truth):
# Get the (x, y) coordinates of the intersection of bounding boxes
top_x_intersect = max(box_predicted[0], box_truth[0])
top_y_intersect = max(box_predicted[1], box_truth[1])
bottom_x_intersect = min(box_predicted[2], box_truth[2])
bottom_y_intersect = min(box_predicted[3], box_truth[3])
# Calculate the area of the intersection bounding box
intersection_area = max(0, bottom_x_intersect - top_x_intersect + 1) * max(
0, bottom_y_intersect - top_y_intersect + 1
)
# Calculate the area of the prediction bounding box and ground-truth bounding box
box_predicted_area = (box_predicted[2] - box_predicted[0] + 1) * (
box_predicted[3] - box_predicted[1] + 1
)
box_truth_area = (box_truth[2] - box_truth[0] + 1) * (
box_truth[3] - box_truth[1] + 1
)
# Calculate Intersection over Union by taking the intersection area
# and dividing it by the sum of predicted bounding box and ground truth
# bounding box areas, subtracted by the intersection area
# Return IoU
return intersection_area / float(
box_predicted_area + box_truth_area - intersection_area
)
Below we write code for evaluation.
i, mean_iou = 0, 0 # Initialize variables to keep track of the index and mean IoU
# Compare results for 10 images in the test set
for input_image in x_test[:10]:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 15))
im = input_image
# Display the original image
ax1.imshow(im.astype("uint8"))
ax2.imshow(im.astype("uint8"))
# Resize the input image to the specified image size
input_image = cv2.resize(
input_image, (image_size, image_size), interpolation=cv2.INTER_AREA
)
input_image = np.expand_dims(input_image, axis=0)
# Make predictions using the ViT object detector
preds = vit_object_detector.predict(input_image)[0]
(h, w) = (im).shape[0:2]
# Extract bounding box coordinates from predictions
top_left_x, top_left_y = int(preds[0] * w), int(preds[1] * h)
bottom_right_x, bottom_right_y = int(preds[2] * w), int(preds[3] * h)
box_predicted = [top_left_x, top_left_y, bottom_right_x, bottom_right_y]
# Create a bounding box visualization
rect = patches.Rectangle(
(top_left_x, top_left_y),
bottom_right_x - top_left_x,
bottom_right_y - top_left_y,
facecolor="none",
edgecolor="red",
linewidth=1,
)
# Add the bounding box to the image
ax1.add_patch(rect)
ax1.set_xlabel(
"Predicted: "
+ str(top_left_x)
+ ", "
+ str(top_left_y)
+ ", "
+ str(bottom_right_x)
+ ", "
+ str(bottom_right_y)
)
# Extract ground truth bounding box coordinates
top_left_x, top_left_y = int(y_test[i][0] * w), int(y_test[i][1] * h)
bottom_right_x, bottom_right_y = int(y_test[i][2] * w), int(y_test[i][3] * h)
box_truth = top_left_x, top_left_y, bottom_right_x, bottom_right_y
# Calculate Intersection over Union (IoU) and update the mean IoU
mean_iou += bounding_box_intersection_over_union(box_predicted, box_truth)
# Create a bounding box visualization for ground truth
rect = patches.Rectangle(
(top_left_x, top_left_y),
bottom_right_x - top_left_x,
bottom_right_y - top_left_y,
facecolor="none",
edgecolor="red",
linewidth=1,
)
# Add the bounding box to the image
ax2.add_patch(rect)
ax2.set_xlabel(
"Target: "
+ str(top_left_x)
+ ", "
+ str(top_left_y)
+ ", "
+ str(bottom_right_x)
+ ", "
+ str(bottom_right_y)
+ "\n"
+ "IoU"
+ str(bounding_box_intersection_over_union(box_predicted, box_truth))
)
i = i + 1 # Increment the index
# Calculate and print the mean IoU for the 10 images
print("mean_iou: " + str(mean_iou / len(x_test[:10]))
# Show the images with bounding box visualizations
plt.show()
Output
Below, we can see that our model performs well, when compared to the true class or true coordinates in this case.
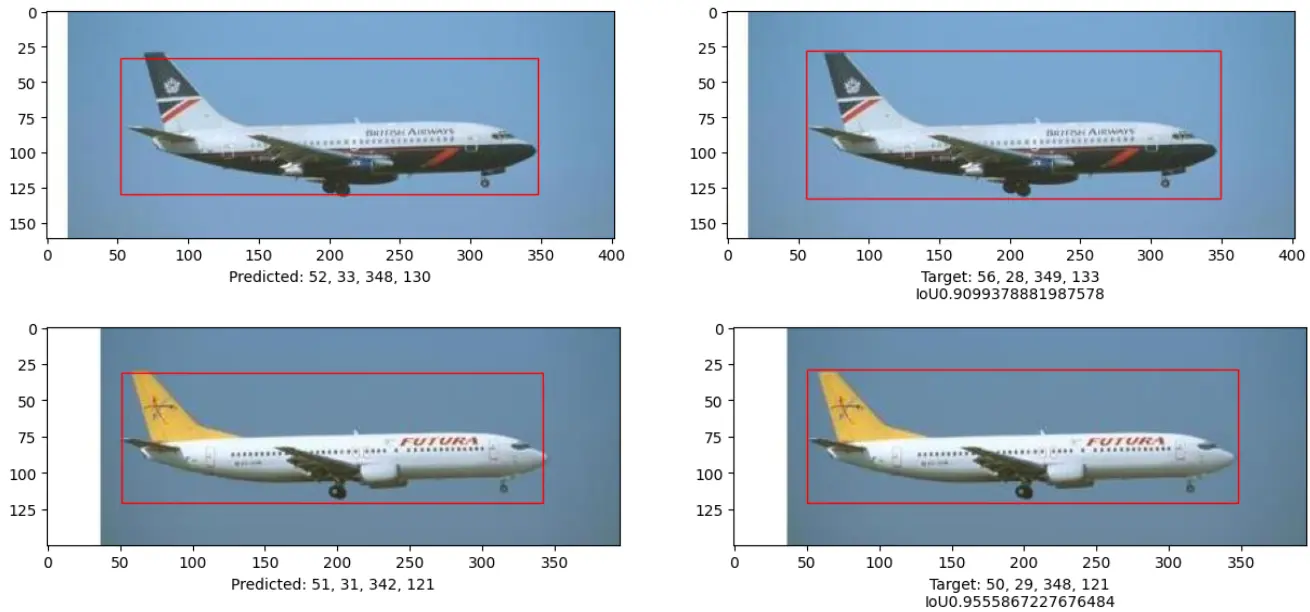
Figure: Output
Conclusion
In this guide, we explored how to adapt Vision Transformers for object detection, demonstrating effective techniques using the Caltech-101 dataset.
By implementing positional encodings and patch embeddings, we built a model that performed well in detecting objects and predicting bounding boxes.
To enhance your own projects, consider experimenting with hyperparameter tuning and data augmentation techniques.
For further insights on deep learning and object detection, check out related articles on our blog. Stay updated as we continue to refine these techniques and share new findings!
Frequently Asked Questions
1. What are vision Transformers?
Vision transformers find broad utility in prominent image recognition tasks like object detection, segmentation, image classification, and action recognition.
Furthermore, they are employed in generative modeling and multi-modal applications, encompassing visual grounding, answering visual questions, and solving visual reasoning problems.
2. What is object Detection?
Object detection, in the field of computer vision, involves identifying the presence and location of objects within images or video frames.
Typically, object detection methods make use of machine learning or deep learning approaches to yield significant outcomes.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
