

SegGPT: Contextual Segmentation To Generate Labeled Images At Scale


Table of Contents
- Introduction
- What is SegGPT?
- SegGPT Model Architecture
- Inference and Performance
- Applications of SegGPT
- AI-Assisted Labeling with SegGPT
- Leveraging SegGPT in Labellerr
- Conclusion
- FAQ
Introduction
In the field of computer vision, one of the most challenging and essential tasks is image segmentation. This task involves dividing an image into meaningful segments, typically to locate objects and boundaries (lines, curves, etc.). Unlike classification tasks that assign a single label to an entire image, segmentation assigns a label to each pixel, providing a much more granular understanding of the visual content.
What is Image Segmentation?
Image segmentation is a process in computer vision that partitions an image into multiple segments or regions, each of which corresponds to a specific object or part of an object. The goal is to simplify or change the representation of an image into something more meaningful and easier to analyze.
Types of Segmentation:
- Semantic Segmentation: Assign a class label to each pixel in the image. All pixels belonging to a particular object class (e.g., all cars) receive the same label.
- Instance Segmentation: Extends semantic segmentation by identifying individual instances of objects. Each car in an image, for example, would be assigned a unique identifier.
- Panoptic Segmentation: Combines both semantic and instance segmentation, providing a comprehensive view by labeling each pixel with both a class and an instance identifier.
Limitations of Traditional Segmentation Models
Traditional segmentation models are often highly specialized and trained to perform a specific type of segmentation task (e.g., only semantic segmentation or only instance segmentation). These models typically face several limitations:
- Task-Specific Training: They require separate training for each segmentation task, necessitating a large amount of annotated data for each specific application.
- Limited Generalization: Traditional models struggle to generalize across different domains or tasks without significant retraining and fine-tuning.
- Inflexibility: Adapting these models to new tasks or datasets usually involves considerable modifications and retraining efforts.
What is SegGPT?
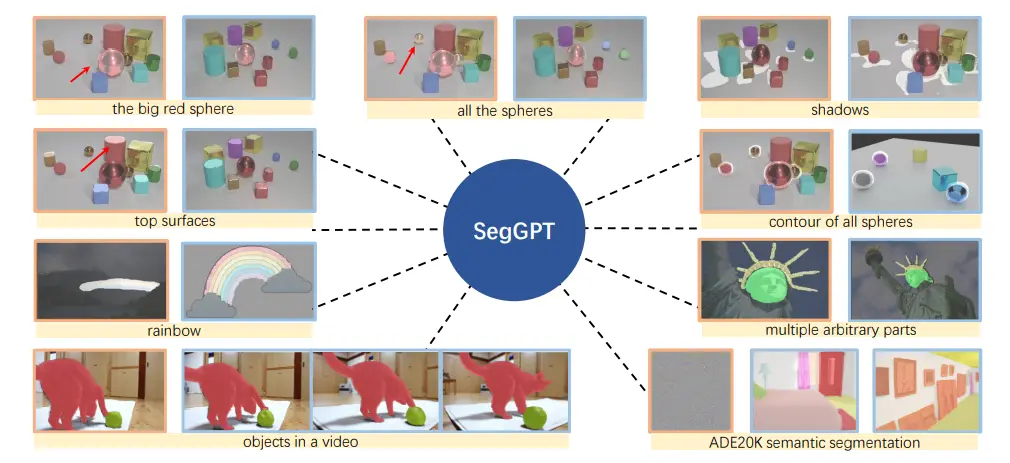
SegGPT is a groundbreaking model designed to unify a multitude of image segmentation tasks within a single, coherent framework. It stands for "Segmentation Generative Pre-trained Transformer," and it leverages the powerful architecture of the Vision Transformer (ViT) to handle various segmentation challenges.
The primary objective of SegGPT is to provide a versatile and robust solution for segmentation that can adapt to different tasks without needing extensive task-specific training or fine-tuning.
Key Features of SegGPT
SegGPT introduces several innovative features that set it apart from traditional segmentation models. Here are the key features:
In-Context Learning:
In-context learning refers to the model's ability to understand and perform tasks by referencing contextual information provided during inference. Instead of relying solely on pre-defined rules or mappings, SegGPT uses context to guide its segmentation decisions.
This approach allows SegGPT to adapt to new segmentation tasks on the fly, making it highly flexible and capable of handling diverse applications without the need for extensive retraining.
Random Color Mapping:
Traditional segmentation models often depend on fixed color mappings for different classes or segments. SegGPT, however, employs a random color mapping scheme during training.
This randomization enhances the model's generalization capabilities by preventing it from overfitting to specific color patterns. As a result, SegGPT can effectively segment images even when presented with unfamiliar color distributions.
Unified Framework:
SegGPT is designed to integrate various segmentation tasks into a single model. It can handle semantic segmentation, instance segmentation, panoptic segmentation, and more within the same architecture.
This unified framework simplifies the deployment and maintenance of segmentation models, as there is no need to develop and manage multiple task-specific models.
Context Ensemble Strategies:
To improve segmentation accuracy, SegGPT employs context ensemble strategies, which combine spatial and feature information from multiple examples during inference.
This ensemble approach leverages the strengths of different examples, resulting in more accurate and reliable segmentation outcomes, particularly in complex or ambiguous scenarios.
Versatile Data Integration:
SegGPT can incorporate a wide range of segmentation data, including part, semantic, instance, panoptic, person, medical, and aerial images.
This versatility ensures that SegGPT can be applied to various fields and applications, from medical imaging to autonomous driving, without requiring significant modifications to the model architecture.
Robust Performance:
SegGPT has been evaluated on a diverse set of tasks and datasets, demonstrating its strong performance in both in-domain and out-of-domain settings.
The model's robustness makes it a reliable choice for real-world applications where the nature of the data may vary significantly.
Model Architecture
Backbone: Vision Transformer (ViT)
Vision Transformer (ViT) serves as the backbone of SegGPT, providing the fundamental architecture on which the model is built. The ViT has revolutionized computer vision tasks by leveraging the power of transformers, which were initially developed for natural language processing. Here's an overview of how ViT functions and its role in SegGPT:
Self-Attention Mechanism:
- ViT uses self-attention mechanisms to capture long-range dependencies in the input image. This allows the model to understand relationships between different parts of the image, enabling more accurate segmentation.
Patch-Based Processing:
- Unlike traditional convolutional neural networks (CNNs) that process images pixel by pixel, ViT divides the input image into a sequence of patches. Each patch is treated as a token, similar to words in a sentence for NLP models.
Transformer Layers:
- These patches are then fed into multiple transformer layers, where self-attention and feed-forward networks process them. This enables the model to learn complex patterns and representations within the image.
Advantages of Segmentation:
- The ability to capture global context through self-attention makes ViT particularly well-suited for segmentation tasks, where understanding the relationship between different regions of an image is crucial.
By using ViT as the backbone, SegGPT benefits from the advanced capabilities of transformers, achieving high performance across various segmentation tasks.
Training Process
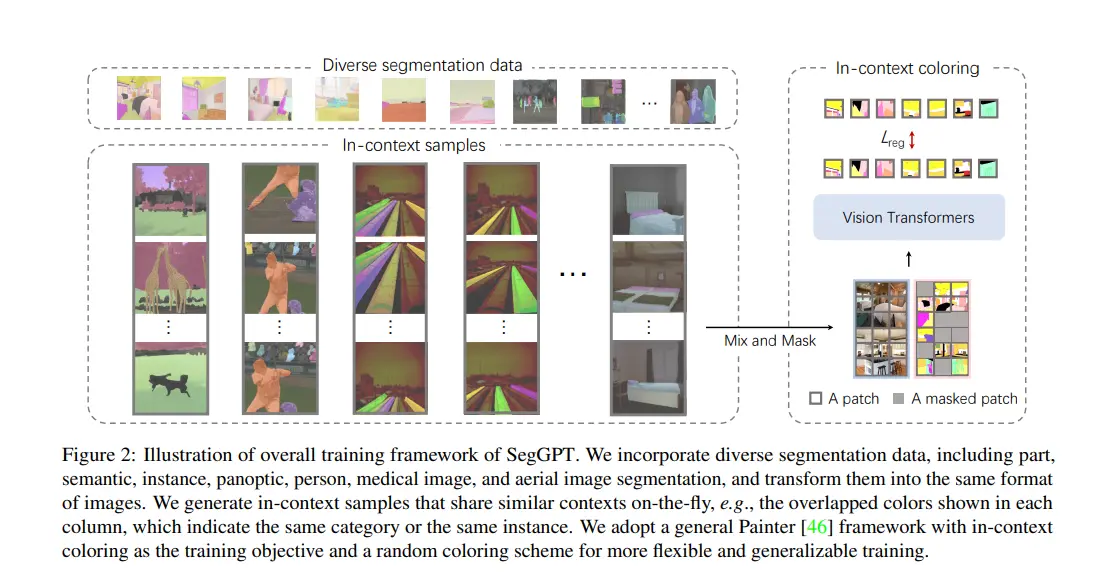
Data Integration
One of the standout features of SegGPT is its ability to incorporate diverse segmentation data, making it a versatile model capable of handling a wide range of segmentation tasks. This diversity includes part segmentation, semantic segmentation, instance segmentation, panoptic segmentation, as well as specialized domains such as person, medical, and aerial image segmentation. Here’s how SegGPT achieves comprehensive data integration:
Unified Dataset Preparation:
- SegGPT integrates various segmentation datasets into a unified format. Each dataset contains images and their corresponding segmentation labels, which may vary widely in terms of the type of objects, the level of detail required, and the nature of the segmentation task.
Standardized Input Representation:
- Regardless of the segmentation type, all input images are standardized into a common representation format suitable for the Vision Transformer (ViT) backbone. This involves resizing images to a consistent size and dividing them into fixed-size patches, which are then processed by the model.
Task-Agnostic Training:
- By treating all segmentation tasks within a unified framework, SegGPT does not require separate models or training procedures for different types of segmentation. This task-agnostic approach simplifies the training process and makes the model more flexible.
Diverse Domains:
- Part Segmentation: Identifying and labeling different parts of an object (e.g., car parts, human body parts).
- Semantic Segmentation: Assigning class labels to each pixel in the image based on object categories (e.g., road, building, sky).
- Instance Segmentation: Differentiating between individual instances of objects within the same category (e.g., multiple cars in an image).
- Panoptic Segmentation: Combining both semantic and instance segmentation to provide a comprehensive view of the scene.
- Specialized Segmentation: Handling specific domains like medical imaging (e.g., segmenting tumors in MRI scans) and aerial images (e.g., identifying buildings and roads in satellite images).
By integrating such diverse datasets, SegGPT can generalize well across different segmentation challenges, providing a robust solution for various applications.
In-Context Coloring
A key innovation in SegGPT’s training process is the use of in-context coloring, which involves a random coloring scheme. This technique enhances the model’s ability to generalize across different tasks and domains. Here’s a detailed explanation of how in-context coloring works and its benefits:
Random Color Mapping:
- During training, SegGPT assigns random colors to different segments within an image. Unlike traditional models that use fixed color mappings for specific classes or objects, SegGPT’s color assignments change every time the model sees the image.
Learning to Generalize:
- The model’s task is to learn the underlying patterns and relationships between different segments, rather than memorizing specific color mappings. By constantly changing the colors, SegGPT is forced to rely on the contextual information and spatial relationships within the image to perform segmentation.
Enhanced Robustness:
- This approach prevents the model from overfitting to particular color patterns seen during training. As a result, SegGPT becomes more robust and capable of handling new, unseen data where the color distributions may differ significantly from the training set.
Contextual Understanding:
- In-context coloring encourages the model to develop a deeper understanding of the image structure and the relationships between different segments. This improved contextual understanding is critical for accurately segmenting complex and diverse images.
Inference and Performance
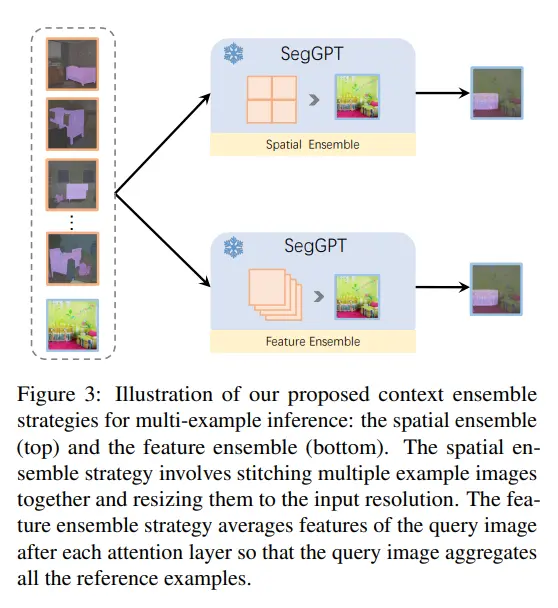
Context Ensemble Strategies
To further enhance its segmentation accuracy and robustness, SegGPT employs context ensemble strategies, which combine spatial and feature information from multiple examples during inference. These strategies help the model leverage the strengths of different examples, resulting in more precise and reliable segmentation outcomes. Here’s how these strategies work:
Spatial Ensemble:
- Description: In spatial ensemble, multiple example images with their segmentations are provided as context. The model processes each example independently and combines the results to produce the final segmentation.
- Benefit: This approach helps in capturing different spatial variations and patterns from the examples, improving the model’s ability to generalize and handle diverse input images.
Feature Ensemble:
- Description: Feature ensemble involves combining the feature representations of multiple examples during inference. The model aggregates these features to create a comprehensive understanding of the segmentation task.
- Benefit: By leveraging the combined feature representations, the model can better understand complex relationships and variations within the input image, leading to more accurate segmentation results.
Multi-Example Inference:
- Description: Both spatial and feature ensemble strategies are utilized in a multi-example inference setup. The model processes several examples simultaneously, using the aggregated spatial and feature information to produce the final segmentation.
- Benefit: This combined approach maximizes the use of available contextual information, resulting in superior segmentation performance, particularly in challenging scenarios with complex or ambiguous input images.
Applications of SegGPT

SegGPT, with its robust contextual segmentation capabilities, finds diverse applications across several domains, ranging from traditional text segmentation to more specialized tasks requiring a nuanced understanding of context.
Object Instance Segmentation: Beyond textual data, SegGPT can be adapted for object instance segmentation in images. By treating pixels as tokens and leveraging its contextual understanding, SegGPT can delineate boundaries between different objects within an image, facilitating tasks such as image segmentation and object detection in computer vision applications.
Video Object Segmentation: In video processing, SegGPT's ability to dynamically segment text can be extended to video frames. By analyzing temporal context and spatial relationships between frames, SegGPT can accurately segment and track objects or regions of interest over time, enhancing tasks such as video object segmentation and action recognition.
Specialized Use Cases like Medical Image Segmentation: In medical imaging, where precise segmentation of anatomical structures is critical, SegGPT's adaptability proves invaluable. By leveraging its contextual embeddings and ensemble strategies, SegGPT can segment medical images into regions corresponding to organs, tumors, or anomalies, aiding in diagnostic tasks and treatment planning.
AI-Assisted Labeling with SegGPT
Traditional image segmentation involves manually labeling each pixel in an image, a time-consuming and laborious process. AI-assisted labeling platforms like Labellerr aim to streamline this workflow by incorporating powerful models like SegGPT.
SegGPT's strength lies in its ability to learn from context. When paired with an AI-assisted labeling platform, the process transforms:
- Automatic Initial Segmentation: Users upload their images and define the segmentation task. SegGPT then takes center stage, leveraging its pre-trained knowledge to generate initial segmentation masks for each image. These masks act as a starting point, significantly reducing manual effort compared to labeling each pixel from scratch.
- Human-in-the-Loop Refinement: The platform doesn't stop at SegGPT's initial guess. Users can then review and refine the suggested masks using intuitive editing tools. This human oversight ensures the final annotations achieve the desired level of accuracy for specific projects.
By combining SegGPT's automation with human expertise, AI-assisted labeling platforms empower users to achieve high-quality segmentation results with greater speed and efficiency.
Leveraging SegGPT in Labellerr
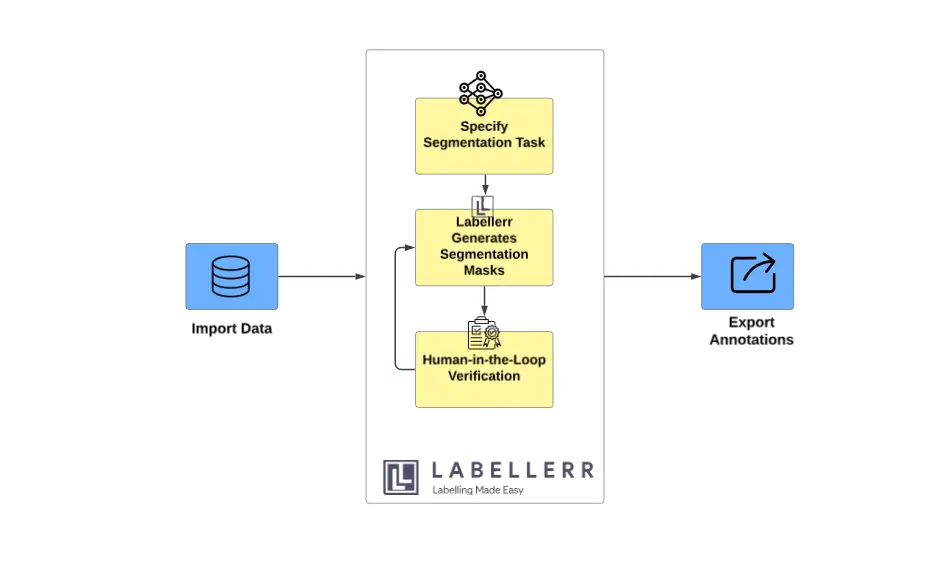
Labellerr platform takes image segmentation a step further by integrating SegGPT directly into its user workflow. This powerful integration empowers users to achieve high-quality segmentation results with greater ease and efficiency.
Here's how you can harness the power of SegGPT within Labellerr:
- Import your data: Begin by uploading your images or videos to the Labellerr platform.
- Specify segmentation needs: Clearly define your desired segmentation task. This could involve outlining objects, classifying image regions, or segmenting specific structures.
- SegGPT takes the lead: Labellerr leverages the pre-trained SegGPT model to automatically generate initial segmentation masks for your data. This significantly reduces manual effort compared to traditional annotation processes.
- Human-in-the-loop refinement: Following SegGPT's initial segmentation, Labellerr allows you to refine the results for optimal accuracy. This intuitive interface empowers you to make adjustments, ensuring the final annotations meet your specific requirements.
- Effortless export: Once satisfied with the annotations, Labellerr facilitates the seamless export of your data in the desired format, ready for further analysis or integration into your projects.
Conclusion
SegGPT represents a significant leap forward in image segmentation by offering a general-purpose solution that transcends the limitations of traditional models. Its core strengths lie in its ability to leverage diverse segmentation data, its in-context learning framework that promotes generalization, and its adaptability to new tasks without extensive retraining.
This versatility opens doors to a wide range of applications across various domains, from self-driving cars and medical imaging to robotics and aerial image analysis.
As research in SegGPT continues, we can expect further advancements in its efficiency, accuracy, and ability to handle even more complex segmentation tasks.
This model has the potential to become a foundational tool for computer vision applications, paving the way for a deeper understanding of the visual world and unlocking new possibilities in various fields.
FAQ
1. What is SegGPT?
SegGPT stands for Segmenting Everything In Context. It is an advanced model built on the transformer architecture, specifically designed to segment text and other data types based on contextual understanding rather than fixed rules or patterns.
2. How does SegGPT perform text segmentation differently from traditional methods?
Traditional text segmentation methods often rely on predefined rules or statistical patterns, which may not capture the nuanced context of language. SegGPT, on the other hand, uses contextual embeddings learned during training to dynamically identify segment boundaries based on the surrounding context of the text. This approach allows SegGPT to adapt its segmentation strategy to different writing styles, languages, and genres, resulting in more accurate and contextually relevant segmentations.
3. What are some practical applications of SegGPT?
SegGPT has a wide range of applications, including:
- Text Segmentation: Segmenting text into sentences, paragraphs, or clauses for tasks like summarization and sentiment analysis.
- Object Instance Segmentation: Applying segmentation principles to identify and delineate objects in images or videos.
- Medical Image Segmentation: Precisely identifying and segmenting anatomical structures in medical imaging for diagnostic and treatment purposes.
Reference
1) SegGPT: Segmenting Everything In Context(Paper).
2)SegGPT (HuggingFace).

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
