

Florence-2: Vision Model for Diverse AI Applications


Table of Contents
- Introduction
- Overview of Florence-2
- Key Features of Florence-2: Unifying Vision and Language
- Architecture and Design
- Performance and Evaluation
- Applications and Use Cases
- Integration of Florence-2 in Labellerr
- Conclusion
- FAQ
Introduction
Introducing Florence-2, a groundbreaking vision model that will revolutionize diverse AI applications.
Traditionally, computer vision relied on specialized models trained for singular tasks, like image classification or object detection. This meant a new model was needed for each specific application.
However, the future of vision is leaning towards multi-modal models, like Florence-2. These AI models excel at processing information from multiple modalities, most commonly combining visual data (images, videos) with textual information (descriptions, captions).
This fusion of sight and language allows them to perform a broader range of tasks and achieve superior performance compared to their single-minded predecessors.
Overview of Florence-2
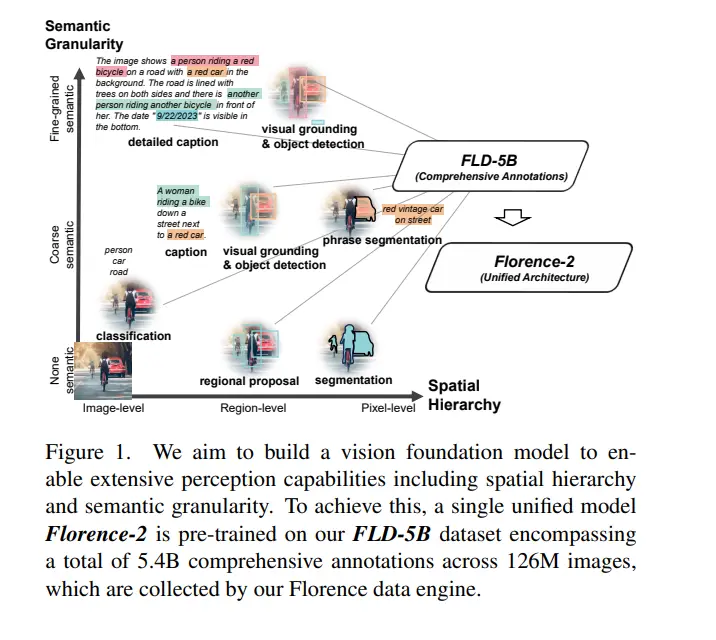
Florence-2, developed by Microsoft, is a groundbreaking model in the field of computer vision and artificial intelligence (AI). This model represents a significant leap in the ability to understand and interpret visual data, achieving a high level of performance across a wide range of tasks. Florence-2 is built on a robust architecture designed to handle the complexities of vision and vision-language tasks, enabling it to process and analyze images with remarkable accuracy and efficiency.
The primary purpose of Florence-2 is to serve as a versatile and powerful tool for various vision-related applications. By leveraging advanced machine learning techniques and an extensive dataset, Florence-2 can perform tasks such as image captioning, object detection, grounding, and segmentation. This flexibility makes it a valuable asset for numerous industries, including healthcare, automotive, retail, and more.
Florence-2's significance in the realm of computer vision and AI cannot be overstated. It represents the convergence of state-of-the-art technology and innovative research, pushing the boundaries of what is possible in visual data processing. With its ability to understand and interpret images at a granular level, Florence-2 sets a new benchmark for performance and versatility in computer vision models.
Key Features of Florence-2: Unifying Vision and Language
Let's delve into the technical aspects that empower its versatility. Here, we'll explore three key features that differentiate Florence-2 from traditional vision models:
1. Unified Representation with Text-based Prompts:
- Unlike conventional models trained for specific tasks, Florence-2 adopts a unified representation. This means it internally encodes visual information in a way that's agnostic to the final task. Imagine a universal language for describing images. Florence-2 strives for that, capturing the essence of an image in a way that can be interpreted for various purposes.
- To leverage this unified representation, Florence-2 utilizes text-based prompts. These prompts act as instructions, guiding the model towards the desired task. For instance, a prompt like "find all the dogs in the image" instructs Florence-2 to utilize its knowledge of the "dog" concept within its unified representation to identify and potentially highlight canines in the image.
2. Multi-task Learning for Enhanced Performance:
- Florence-2 achieves its versatility through a training approach known as multi-task learning. During training, it's exposed to a variety of tasks simultaneously, including image captioning, object detection, visual grounding (linking image regions to textual descriptions), and segmentation (dividing the image into regions based on content).
- By tackling these diverse tasks concurrently, Florence-2 learns a richer and more nuanced understanding of visual data. This cross-pollination of knowledge strengthens its core representation, enabling it to excel in various vision and vision-language domains even with just text-based prompts.
3. FLD-5B Dataset: The Power of Rich Annotations:
- The success of Florence-2 hinges on the FLD-5B dataset, a massive collection of 126 million images accompanied by a staggering 5.4 billion annotations. These annotations come in various forms, including captions, bounding boxes for object detection, and pixel-level labels for segmentation.
- The sheer volume and diversity of the FLD-5B dataset provide Florence-2 with a comprehensive understanding of the relationship between visual data and its textual descriptions. This rich training ground empowers the model to learn the intricacies of visual concepts and translate them into various outputs based on prompts.
Architecture and Design
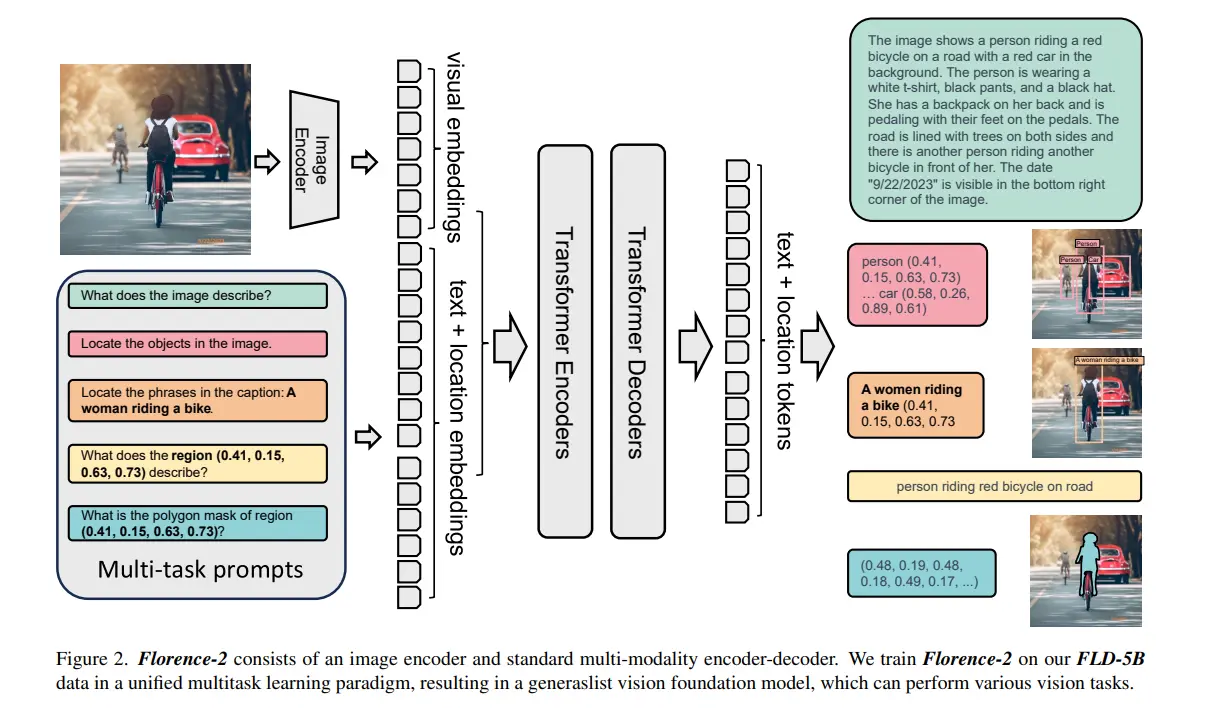
Sequence-to-Sequence Structure
The Florence-2 model employs a sophisticated sequence-to-sequence architecture that is central to its ability to handle diverse vision and vision-language tasks. This architecture consists of two main components: the image encoder and the multi-modality encoder-decoder.
Image Encoder
The image encoder is responsible for converting raw image data into a sequence of meaningful representations. It processes input images by dividing them into smaller patches, which are then embedded into high-dimensional vectors. These vectors capture essential features of the image, such as color, texture, and shape.
Florence-2 leverages a vision transformer (ViT) as its image encoder. The ViT architecture divides the image into fixed-size patches, typically 16x16 pixels, and treats each patch as a token. These tokens are then linearly embedded and passed through multiple transformer layers. Each layer consists of self-attention mechanisms and feed-forward neural networks that allow the model to capture both local and global dependencies within the image.
The output of the image encoder is a sequence of feature vectors that represent the visual content of the image. This sequence serves as the input to the next stage of the architecture: the multi-modality encoder-decoder.
Multi-Modality Encoder-Decoder
The multi-modality encoder-decoder is designed to process and integrate information from both visual and textual inputs. It consists of two main parts: the encoder, which processes the visual features, and the decoder, which generates the output based on the task-specific prompt.
- Encoder: The encoder takes the sequence of feature vectors from the image encoder and further processes them to capture more complex patterns and relationships. This is achieved through additional transformer layers that enhance the model's understanding of the visual content.
- Decoder: The decoder is responsible for generating the final output, whether it be text (e.g., captions), bounding boxes (e.g., object detection), or segmentation masks. It receives both the processed visual features and a task-specific prompt. The prompt is encoded as a sequence of tokens that provide instructions for the task at hand.
The decoder uses cross-attention mechanisms to align the visual features with the prompt tokens. This alignment allows the model to focus on relevant parts of the image based on the task requirements. The decoder then generates the output sequence, completing the sequence-to-sequence process.
Integration of Spatial Hierarchy and Semantic Granularity
Florence-2 excels in handling varying spatial details and semantic granularity, enabling it to interpret images from high-level concepts to fine-grained pixel specifics. This capability is achieved through the integration of spatial hierarchy and semantic granularity within the model's architecture.
Spatial Hierarchy
Spatial hierarchy refers to the model's ability to understand and represent visual information at different levels of spatial resolution. Florence-2's vision transformer-based image encoder plays a crucial role in this aspect. By dividing the image into patches and processing them through multiple transformer layers, the model captures both local details and global context.
- Local Details: The initial layers of the transformer focus on local details within each patch, capturing fine-grained features such as edges, textures, and small objects.
- Global Context: As the sequence of patches passes through deeper layers, the model begins to capture global context by aggregating information from multiple patches. This enables the model to understand the overall structure and layout of the image.
Semantic Granularity
Semantic granularity refers to the model's ability to distinguish and represent visual information at different levels of semantic abstraction, from broad categories to specific instances.
- High-Level Concepts: The model can recognize and categorize broad concepts such as "animal," "vehicle," or "building." This is crucial for tasks like image classification, where the goal is to identify the main subject of an image.
- Fine-Grained Specifics: Florence-2 can also identify fine-grained details, such as specific types of animals (e.g., "golden retriever"), or even pixel-level distinctions required for segmentation tasks. This level of detail is essential for applications that require precise localization and identification of objects within an image.
Combined Strengths
By combining spatial hierarchy and semantic granularity, Florence-2 is equipped to handle a wide range of tasks with varying levels of complexity. The model can seamlessly transition from understanding high-level concepts to focusing on fine-grained details, making it exceptionally versatile.
For example, in an object detection task, Florence-2 first identifies potential regions of interest at a high level and then refines its predictions by focusing on specific details within those regions. Similarly, in a segmentation task, the model can segment an image into meaningful parts while maintaining a coherent understanding of the overall scene.
Performance and Evaluation
Benchmark Results
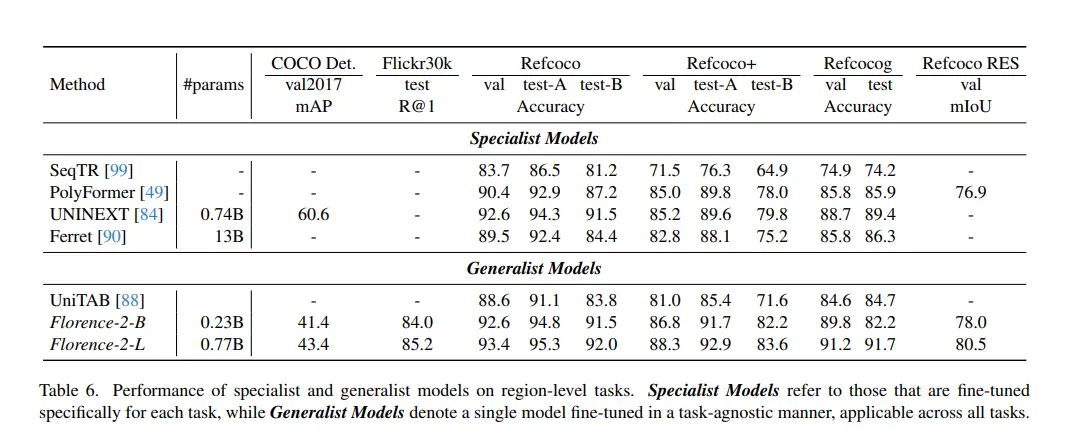
Florence-2's performance has been rigorously evaluated on several benchmark datasets, demonstrating its superior capabilities across a range of tasks. Here are some specific benchmark results and comparisons with other models:
Image Captioning
Florence-2 has achieved state-of-the-art results on image captioning benchmarks. For instance, on the COCO (Common Objects in Context) dataset, Florence-2 has outperformed existing models in generating accurate and descriptive captions for images. The model's ability to understand complex scenes and generate coherent descriptions has set a new standard in this task.
Object Detection
In object detection, Florence-2 has demonstrated exceptional performance on the COCO and Open Images datasets. The model's ability to accurately identify and locate objects within images, even in challenging conditions, highlights its robustness and precision. Comparisons with other leading models show that Florence-2 consistently achieves higher mean Average Precision (mAP) scores, indicating its superior detection capabilities.
Segmentation
Florence-2 has also excelled in segmentation tasks, which involve dividing an image into meaningful segments, such as separating foreground objects from the background. On benchmark datasets like PASCAL VOC and ADE20K, Florence-2 has achieved top-tier results, with higher Intersection over Union (IoU) scores compared to other models. This performance underscores the model's ability to understand fine-grained details and spatial hierarchies within images.
Zero-shot Learning
Florence-2's zero-shot learning capabilities have been evaluated on various benchmarks, demonstrating its ability to generalize across tasks. For instance, in zero-shot visual question answering (VQA) tasks, the model has shown a remarkable ability to understand and respond to questions about novel images, outperforming other zero-shot models in accuracy and coherence.
Summary of Benchmark Results
- Image Captioning (COCO): Florence-2 achieved higher BLEU and CIDEr scores than other state-of-the-art models.
- Object Detection (COCO, Open Images): Superior mAP scores, highlighting its precision in identifying and localizing objects.
- Segmentation (PASCAL VOC, ADE20K): Higher IoU scores, demonstrating its capability to handle fine-grained segmentation tasks.
- Zero-shot Learning: Outperformed other models in zero-shot VQA tasks, showcasing its generalization abilities.
These benchmark results confirm Florence-2's position as a leading model in the field of computer vision. Its state-of-the-art performance in zero-shot tasks and fine-tuning efficiency make it a powerful and versatile tool for a wide range of applications.
Applications and Use Cases

Florence-2's capabilities open up numerous real-world applications across various industries. Here are some potential scenarios where Florence-2 can be effectively utilized:
Healthcare
- Medical Imaging: Florence-2 can assist in analyzing medical images, such as X-rays, MRIs, and CT scans, to detect anomalies, diagnose conditions, and segment different anatomical structures. Its ability to process and interpret complex visual data can enhance diagnostic accuracy and support medical professionals.
- Telemedicine: In telemedicine applications, Florence-2 can provide real-time analysis of patient images, facilitating remote consultations and diagnoses.
Automotive
- Autonomous Vehicles: Florence-2's object detection and segmentation capabilities are crucial for autonomous driving systems. The model can accurately identify and track objects, such as pedestrians, vehicles, and road signs, ensuring safe and efficient navigation.
- Driver Assistance: For advanced driver-assistance systems (ADAS), Florence-2 can enhance features like lane-keeping assistance, collision avoidance, and parking assistance by providing precise visual analysis.
Retail
- Visual Search: Florence-2 can power visual search engines, enabling customers to find products by uploading images. The model can identify and match products based on visual similarities, enhancing the shopping experience.
- Inventory Management: In retail environments, Florence-2 can assist in managing inventory by analyzing images from surveillance cameras to track product placement, stock levels, and shelf organization.
Security and Surveillance
- Anomaly Detection: Florence-2 can analyze surveillance footage to detect unusual activities or anomalies, such as unauthorized access, suspicious behavior, or potential security threats. This capability is valuable for enhancing security in public spaces, airports, and critical infrastructure.
- Facial Recognition: The model's facial recognition capabilities can be used for access control, identity verification, and monitoring purposes.
Media and Entertainment
- Content Creation: Florence-2 can generate captions, descriptions, and summaries for images and videos, streamlining content creation for media and entertainment industries. It can also assist in creating visually coherent stories and graphics based on textual prompts.
- Augmented Reality (AR): In AR applications, Florence-2 can enhance user experiences by providing real-time analysis and interaction with the physical environment. It can recognize objects, provide contextual information, and integrate virtual elements seamlessly.
Environmental Monitoring
- Wildlife Conservation: Florence-2 can analyze images and videos from camera traps to monitor wildlife populations, track animal behavior, and detect poaching activities. This data is invaluable for conservation efforts and biodiversity research.
- Agriculture: In agriculture, Florence-2 can be used to monitor crop health, detect diseases, and assess soil conditions by analyzing images from drones or satellites. This information helps farmers make informed decisions and optimize agricultural practices.
Integration of Florence-2 in Labellerr
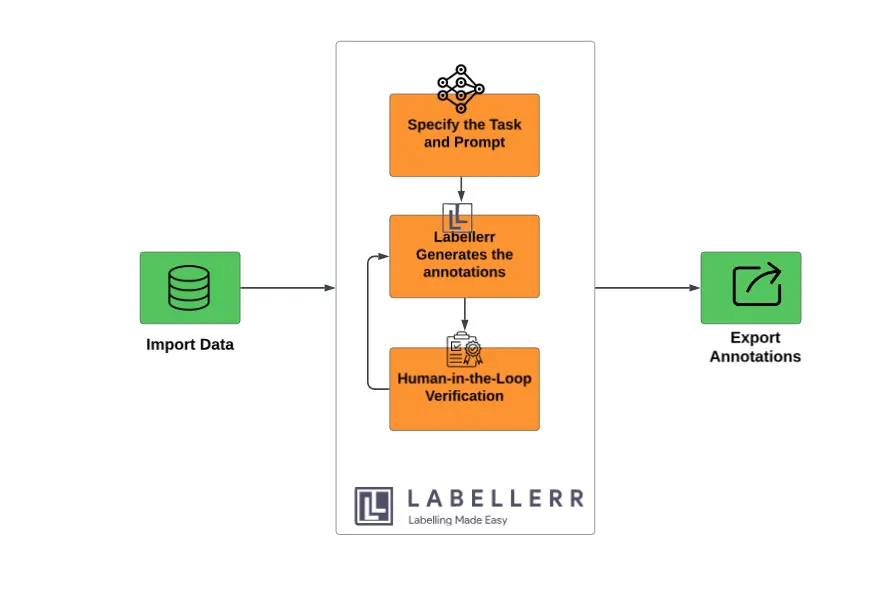
Labellerr has integrated Microsoft's Florence-2 model into its platform, bringing cutting-edge vision capabilities to users.
This integration leverages Florence-2's unified, prompt-based architecture, allowing Labellerr to offer advanced image captioning, object detection, segmentation, and more with minimal task-specific fine-tuning.
By embedding Florence-2, Labellerr enhances its ability to handle diverse and complex vision tasks, providing users with accurate, high-quality outputs across various applications. The seamless integration ensures that users can take full advantage of Florence-2's state-of-the-art performance within the Labellerr ecosystem.
Steps to Use Florence-2 in Labellerr
- Import Data: Upload images or visual datasets into the Labellerr platform.
- Specify Task and Prompt: Choose the task (e.g., image captioning, object detection, segmentation) and create a prompt to guide Florence-2 in processing the data.
- Generate Output: Labellerr uses the Florence-2 model to analyze the data and produce the required outputs.
- Human-in-the-Loop Verification and QA: Review and refine the generated results to ensure accuracy and quality.
- Export Data: Download the processed and verified data for use in your specific applications.
Conclusion
Florence-2 represents a significant advancement in the field of computer vision and AI, showcasing the power of unified, prompt-based architectures and multi-task learning.
The model's state-of-the-art performance in zero-shot tasks and its efficiency in fine-tuning for specific applications highlight its versatility and robustness. Florence-2 excels in various benchmarks, outperforming other models in tasks such as image captioning, object detection, and segmentation. These capabilities open up numerous real-world applications across diverse industries, including healthcare, automotive, retail, security, media, and environmental monitoring.
Florence-2's ability to generalize across tasks with minimal fine-tuning and its adaptability to new challenges make it a valuable tool for researchers, developers, and practitioners.
As AI continues to evolve, models like Florence-2 will play a crucial role in advancing the capabilities of computer vision, driving innovation, and enabling new applications that were previously unattainable. Florence-2 is not just a step forward in AI technology; it is a leap toward a more intelligent and perceptive world.
FAQs
1. What is the Florence-2 model?
Florence-2 is a state-of-the-art vision model developed by Microsoft, designed to handle a wide range of vision and vision-language tasks through a unified, prompt-based approach. It leverages a sequence-to-sequence architecture with an image encoder and a multi-modality encoder-decoder.
2. How does the Florence-2 model differ from previous vision models?
Unlike traditional vision models, Florence-2 uses a unified, prompt-based representation, allowing it to perform multiple tasks without extensive task-specific fine-tuning. Its architecture integrates spatial hierarchy and semantic granularity, enabling it to handle both high-level concepts and fine-grained details.
3. What tasks can Florence-2 handle?
Florence-2 is versatile and can perform various tasks, including image captioning, object detection, segmentation, visual question answering (VQA), and image generation. It excels in both zero-shot tasks and fine-tuning for specific applications.
4. What are zero-shot capabilities in Florence-2?
Zero-shot capabilities refer to the model's ability to perform tasks it has not been explicitly trained on, using its pre-existing knowledge and a well-crafted prompt. Florence-2 can generalize across tasks, making it highly adaptable and efficient.
5. How efficient is Florence-2 in fine-tuning for specific applications?
Florence-2 is highly efficient in fine-tuning due to its comprehensive pre-training on diverse data. Fine-tuning requires significantly less data and computational resources, allowing the model to quickly adapt to specific tasks while maintaining high performance.
Reference:
1) Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks(Paper).
2) Florence-2 (Hugging face).

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
