

Accurate Object Localization using Unsupervised Learning in Data Annotation


Table of Contents
- Introduction
- Challenges of Unsupervised Object Localization
- FOUND Methodology
- Experimental Results
- Applications and Future Work
- Conclusion
- Frequently Asked Questions (FAQs)
Introduction
Object localization is a critical task in computer vision that involves identifying and delineating objects within an image or video. This capability is fundamental to a wide range of applications.
In self-driving cars, accurate object localization ensures that the vehicle can detect and respond to pedestrians, other vehicles, and obstacles, thereby enhancing safety and navigation.
In robotics, it allows machines to interact with their environment more effectively by recognizing and manipulating objects.
Furthermore, in fields like medical imaging, object localization helps in identifying specific anatomical structures or pathological regions, aiding in diagnosis and treatment planning.

The ability to accurately locate objects is also vital in surveillance systems, augmented reality, and numerous other technological domains.
Challenges of Unsupervised Object Localization
Despite its importance, object localization poses significant challenges, especially when performed in an unsupervised manner. The primary difficulty lies in the absence of labeled data.
Supervised learning techniques typically rely on large datasets with annotated objects to train models, but such data is expensive and time-consuming to obtain. Without labels, the model must infer object boundaries and identities from raw, unlabeled data, making the task inherently more complex.
Additionally, traditional methods often assume certain characteristics about objects, such as distinct edges or unique colors, which may not hold true in all scenarios. Objects in natural scenes can be occluded, vary widely in appearance, and blend into the background, complicating the localization process.
Overcoming these challenges requires innovative approaches that can effectively utilize available information to discern objects without explicit guidance.
FOUND Methodology
Self-Supervised Features
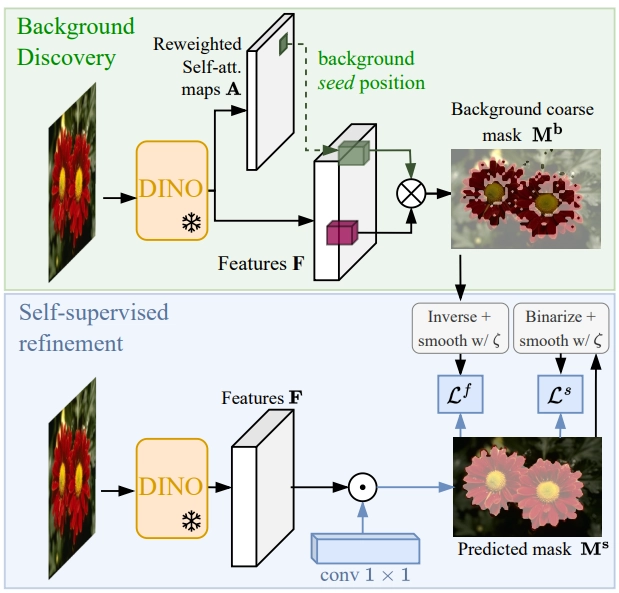
The foundation of the FOUND method lies in leveraging self-supervised Vision Transformers (ViTs) to identify background patches within an image. Self-supervised learning is a powerful technique that enables models to learn useful features from unlabeled data by defining surrogate tasks.
ViTs are employed to extract dense visual features from images. These transformers use attention mechanisms to highlight various regions of an image based on their contextual importance.
By analyzing these attention maps, the FOUND method can differentiate between foreground and background regions, with the latter often receiving less attention.
This process allows the method to utilize the powerful representation learning capabilities of ViTs to accurately identify background patches without any manual annotations.
Background Seed Selection
The next crucial step in the FOUND method is the selection of a background seed. This seed serves as a reference point for identifying other background regions within the image.
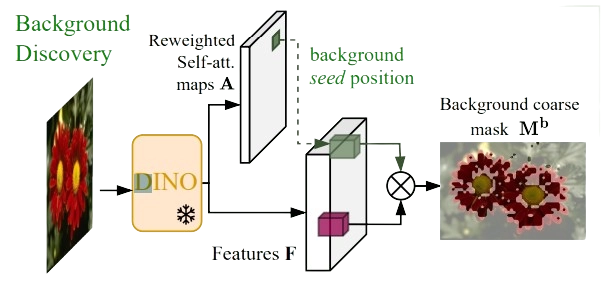
The process begins by examining the attention maps generated by the ViTs. The least attended patch—essentially the region of the image that the ViTs pay the least attention to—is selected as the background seed.
This is based on the assumption that less attention from the model correlates with background regions, as they typically lack the distinctive features and variations found in foreground objects. By starting with the least attended patch, the method ensures a reliable starting point for further background identification.
Reweighting Attention Heads
To enhance the separation between background and foreground patches, the FOUND method employs a reweighting scheme for the attention heads in the ViT. This involves adjusting the attention weights to emphasize the distinction between the identified background seed and the rest of the image.
By reweighting the attention heads, the model can amplify the features that are characteristic of the background while suppressing those associated with the foreground.
This reweighting process refines the initial identification of background patches, making the distinction between background and foreground more pronounced and accurate.
Mask Generation
The creation of background masks is a pivotal step in the FOUND method. Once the background seed is selected and the attention heads are reweighted, the method generates masks based on the similarity of other patches to the background seed.
Patches that exhibit high similarity to the background seed are marked as part of the background, while dissimilar patches are excluded. This process results in a coarse mask that delineates the background regions within the image.
These masks serve as a crucial intermediate output, providing a clear demarcation of background areas that can be further refined in subsequent steps.
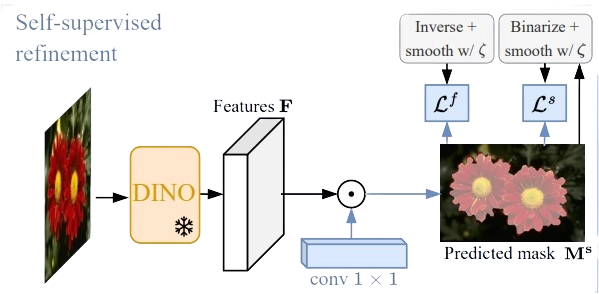
Refining Masks
Lightweight Segmentation Head
To refine the coarse masks generated in the previous step, the FOUND method introduces a lightweight segmentation head.

This head is a single-layer convolutional model specifically designed to improve the precision of the background masks. Unlike traditional heavy segmentation models, this lightweight head is computationally efficient and can be trained quickly.
It takes the coarse masks as input and refines them by learning to better delineate the boundaries between background and foreground regions. The simplicity of the model ensures that it can be easily integrated into various systems and scaled to handle large datasets.
Self-Training Scheme
The refinement process in the FOUND method is further enhanced through a self-training scheme. This scheme involves iteratively using the coarse masks to train the lightweight segmentation head, which in turn produces more accurate masks.
The self-training process leverages the initial coarse masks as pseudo-labels, allowing the model to learn from the data without requiring manual annotations. This iterative approach improves the quality of the masks over time, as the model continuously fine-tunes its understanding of background and foreground regions.
The self-training scheme is advantageous over heavy segmentation backbones because it is more resource-efficient and can achieve high accuracy with fewer computational requirements.
This makes the FOUND method not only effective but also practical for real-world applications where computational resources may be limited.
Experimental Results
Datasets and Benchmarks
The evaluation of the FOUND method was conducted using several standard datasets and benchmarks, which are commonly used in the field of object localization and saliency detection.
Among these datasets, DUTS-TR is prominently featured. DUTS-TR, the training set of the DUTS dataset, is a large-scale dataset specifically designed for saliency detection tasks, containing a diverse array of images with complex scenes and various object types.
In addition to DUTS-TR, other datasets may include those used for generic object discovery and segmentation tasks, providing a comprehensive evaluation environment for the FOUND method.
The performance of FOUND was assessed using metrics such as precision, recall, F-measure, and intersection over union (IoU), which are standard benchmarks for evaluating the accuracy and robustness of object localization and segmentation models.
Performance Analysis
The FOUND method demonstrated impressive results across various tasks, particularly in unsupervised saliency detection and object discovery.
On the DUTS-TR dataset, FOUND achieved high precision and recall rates, indicating its ability to accurately identify and localize objects within complex scenes.

The method's innovative approach of focusing on background regions allowed it to effectively distinguish foreground objects, resulting in superior performance compared to traditional methods.
The F-measure, which balances precision and recall, was notably high for FOUND, showcasing its balanced accuracy.
Furthermore, the IoU scores indicated that the masks generated by FOUND closely matched the ground truth annotations, underscoring the method's precision in delineating object boundaries.
These results highlight the robustness and effectiveness of FOUND in handling various challenges inherent in unsupervised object localization.
Comparison with State-of-the-Art
When compared to other recent methods in the field, the FOUND method stands out in terms of both efficiency and accuracy. Traditional unsupervised object localization methods often struggle with the variability and complexity of natural scenes, leading to lower precision and recall rates.
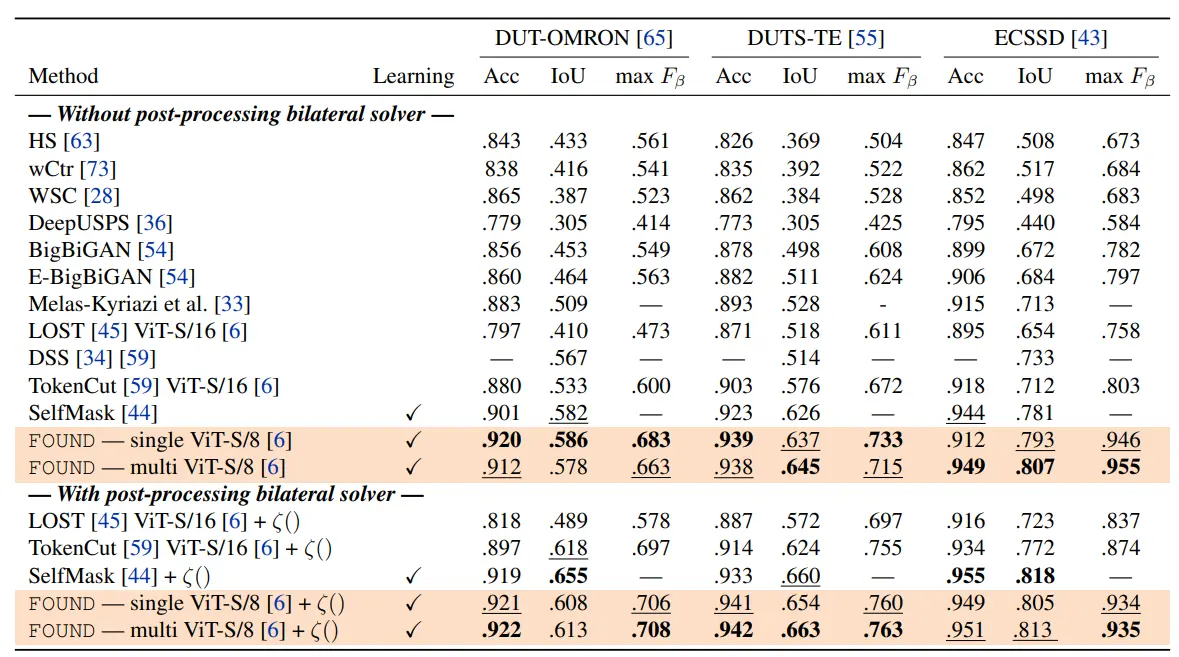
In contrast, FOUND's background-focused approach allows for a more stable and reliable identification of objects, resulting in higher overall performance metrics.
For instance, methods that rely heavily on saliency detection can be susceptible to noise and irrelevant features, whereas FOUND's use of self-supervised ViT features and background reweighting enhances its resilience to such issues.

Additionally, the lightweight segmentation head used in FOUND ensures that the method is computationally efficient, making it suitable for real-time applications without compromising on accuracy.
This efficiency, combined with the high precision and recall achieved, places FOUND ahead of many contemporary methods, establishing it as a leading approach in the domain of unsupervised object localization.
Applications and Future Work
The FOUND method for unsupervised object localization has a wide array of potential applications across various fields due to its innovative approach and high accuracy. One of the most significant applications is in autonomous driving.
In this field, accurate object localization is crucial for the safety and efficiency of self-driving cars.
By effectively distinguishing between the background and objects such as pedestrians, vehicles, and obstacles, the FOUND method can enhance the vehicle's perception system, leading to better navigation and collision avoidance.
FOUND can also be applied in surveillance systems where detecting and tracking objects in real-time is essential.
Its efficiency and accuracy can improve the performance of security cameras in identifying and following individuals or objects of interest.
Moreover, in the field of robotics, FOUND can enhance the interaction between robots and their environments by improving the robots' ability to recognize and manipulate objects. This can be particularly useful in industrial automation, household robotics, and search and rescue operations.
Limitations and Improvements
While the FOUND method offers numerous advantages, it is not without its limitations. One of the primary challenges is its reliance on the quality of self-supervised features extracted by Vision Transformers (ViTs).
If these features are not sufficiently robust, the identification of background patches may be less accurate, leading to suboptimal object localization.
Additionally, the method may struggle in scenarios where the background is highly complex or dynamic, as these conditions can make it difficult to consistently identify background regions.
Another limitation is the potential for computational overhead, despite the lightweight nature of the segmentation head. While FOUND is designed to be efficient, real-time applications in resource-constrained environments may still face challenges, especially if the scenes are highly cluttered or involve rapid changes.
Furthermore, the method's performance might vary across different types of scenes and object categories, necessitating further refinement and adaptation to specific contexts.
To address these limitations, future research could focus on several key areas. Firstly, improving the robustness of self-supervised features through enhanced training techniques or the incorporation of additional contextual information could significantly enhance the accuracy of background identification.
Secondly, developing adaptive methods that can dynamically adjust to varying scene complexities and background characteristics would make the FOUND method more versatile and reliable.
Another direction for future research is to integrate FOUND with other complementary techniques, such as active learning or semi-supervised learning, to further reduce the reliance on large datasets and improve performance in diverse environments.
Exploring the use of FOUND in conjunction with other modalities, such as depth sensing or thermal imaging, could also expand its applicability and effectiveness in different scenarios.
Conclusion
The FOUND method for unsupervised object localization presents a groundbreaking approach by shifting the focus from directly identifying objects to discovering the background first.
This innovative conceptual shift leverages self-supervised Vision Transformer (ViT) features to identify background patches, selecting the least attended patch as the background seed, and reweighting attention heads to enhance the separation between background and foreground regions.
The method generates coarse background masks based on the similarity to the background seed, which are then refined using a lightweight segmentation head through a self-training scheme. This process leads to highly accurate and efficient object localization without the need for labeled data.
The experimental results demonstrate the effectiveness of the FOUND method across various tasks, such as unsupervised saliency detection and object discovery.
Using datasets like DUTS-TR, the method achieved high precision, recall, F-measure, and intersection over union (IoU) scores, indicating its robustness and accuracy in identifying and segmenting objects.
Compared to other state-of-the-art methods, FOUND stands out for its computational efficiency and superior performance, making it suitable for real-time applications in diverse fields.
The FOUND method represents a significant advancement in the field of unsupervised object localization, offering a novel perspective that challenges traditional approaches.
By emphasizing background discovery, this method provides a more stable and reliable foundation for object localization, which can be particularly beneficial in complex and dynamic environments.
The success of FOUND highlights the potential of self-supervised learning and background-focused strategies, opening new avenues for research and development in unsupervised object localization.
This approach is likely to influence future research by encouraging the exploration of background-centric methods and the integration of self-supervised features in various computer vision tasks.
Researchers may build on the principles of the FOUND method to develop even more sophisticated models that can handle a wider range of scenarios and object categories.
Additionally, the emphasis on computational efficiency and lightweight models will likely drive innovation in creating practical and scalable solutions for real-world applications.
Frequently Asked Questions (FAQs)
What is the problem with object localization?
Object localization poses significant challenges, particularly in complex and dynamic environments. Identifying and delineating objects accurately within an image or video is difficult due to variability in object appearances, occlusions, and cluttered backgrounds.
The absence of labeled data in unsupervised settings further complicates the task, as models must infer object boundaries and identities from raw, unlabeled data, making accurate localization inherently challenging.
What is the difference between object detection and object localization?
Object detection involves identifying the presence of objects and classifying them within an image, typically drawing bounding boxes around the detected objects. Object localization, on the other hand, focuses on determining the precise location and boundaries of objects within an image.
While object detection provides information on what objects are present and where they are, localization provides more detailed information about the exact spatial extent and shape of the objects.
How does object localization work?
Object localization works by identifying the position and boundaries of objects within an image.
Techniques vary, but common approaches include using convolutional neural networks (CNNs) to generate feature maps, applying bounding box regressors to refine object locations, and employing segmentation models to delineate object boundaries.
Methods like the FOUND model focus on identifying background regions first and using self-supervised learning to isolate objects based on their contrast with the background.
What is the localization task in computer vision?
The localization task in computer vision involves determining the exact position and boundaries of objects within an image or video.
This task requires accurately identifying the spatial extent of objects, distinguishing them from the background, and often involves generating bounding boxes or segmentation masks.
Localization is a fundamental component of various applications, such as autonomous driving, medical imaging, and robotic vision, where precise object placement and boundaries are crucial for accurate interpretation and interaction.
References

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
