

Automating Vision Tasks Using 4M Framework


Table of Contents
- Introduction
- Current State of Vision Models
- Overview of 4M
- 4M Training Methodology
- Performance and Evaluation
- Use Cases of 4M
- Conclusion
- FAQs
Introduction
In the rapidly evolving landscape of artificial intelligence, the integration of multiple modalities—such as text, images, and audio—has become a frontier of innovation. Massively Multimodal Masked Modeling, often abbreviated as 4M, represents a groundbreaking approach that extends the principles of masked language modeling to include diverse data types within a unified framework.
At its core, 4M leverages the power of transformers and advanced deep learning architectures to process and understand information across different modalities simultaneously. This approach not only facilitates richer contextual understanding but also enables AI systems to perceive and generate content that integrates insights from multiple sources seamlessly.
The development of 4M models marks a significant advancement beyond traditional unimodal approaches, where each modality is typically handled in isolation. By using the relationship between text, images, audio, and potentially other forms of data, these models hold promise for transforming various domains, from natural language processing and computer vision to interactive AI systems and beyond.
Current State of Vision Models
In the field of computer vision, machine learning models have traditionally been designed to specialize in specific tasks or modalities. This specialization leads to the development of various models, each tailored to excel in a particular domain or application, such as object detection, image segmentation, or depth estimation. Here are some examples illustrating this specialization:
- Object Detection Models: Models like YOLO (You Only Look Once) and Faster R-CNN are fine-tuned to detect and classify objects within images. These models are highly optimized for accuracy and speed in recognizing and localizing objects but are limited to this single task.
- Image Segmentation Models: Models like U-Net and Mask R-CNN are designed for pixel-level classification, dividing images into segments corresponding to different objects or regions. These models are essential for applications requiring detailed scene understanding, such as medical image analysis.
- Depth Estimation Models: Models like DenseDepth and Monodepth2 focus on estimating the distance of objects in a scene from a camera, providing critical information for autonomous driving and augmented reality applications.
Each of these models operates within the confines of its specialized task, requiring separate architectures, datasets, and training processes. The need for task-specific models poses several challenges:
- Resource Intensiveness: Training and deploying multiple specialized models can be resource-intensive, requiring substantial computational power and time.
- Lack of Interoperability: Specialized models lack the ability to perform outside their trained tasks, limiting their applicability and versatility.
- Complexity in Integration: Combining insights from multiple specialized models into a single system can be complex and inefficient.
Overview of 4M
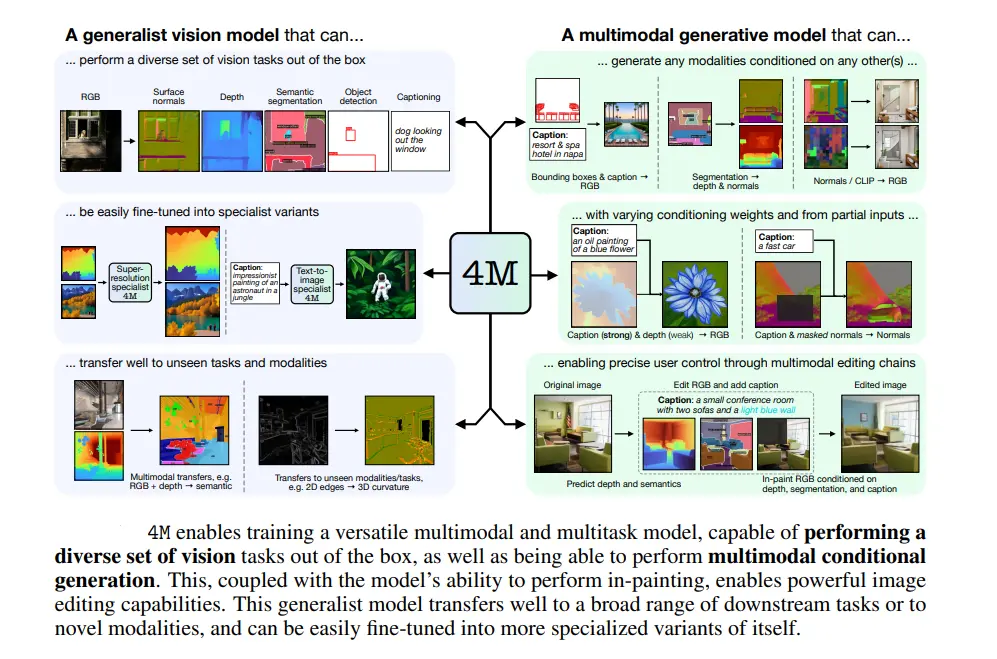
4M (Massively Multimodal Masked Modeling) is a groundbreaking framework designed to unify and extend the capabilities of computer vision models by training a single, versatile Transformer encoder-decoder across multiple modalities using a masked modeling objective.
The primary goal of 4M is to create a model that can seamlessly handle various vision tasks, ranging from classification and segmentation to depth estimation and beyond, all within a single architecture.
Core Concepts:
- Single Unified Transformer Architecture: Unlike traditional vision models, which are specialized for specific tasks, 4M utilizes a single Transformer architecture that can process and generate outputs for multiple modalities, such as images, text, and geometric data.
- Masked Modeling Objective: Inspired by the masked language modeling objective used in NLP, 4M employs a similar strategy where portions of the input data are masked and the model is trained to predict these masked portions. This approach encourages the model to learn rich, generalizable representations across different types of data.
Key Capabilities
The 4M framework introduces several key capabilities that make it a versatile and powerful tool for various vision-related tasks:
Performing Diverse Vision Tasks Out of the Box
- Multitask Learning: 4M is inherently designed to perform a wide range of vision tasks without requiring task-specific modifications. This capability is achieved through its unified architecture and training objective, which allow the model to learn from diverse data types and tasks simultaneously.
- Versatility in Application: Whether it's image classification, object detection, segmentation, or depth estimation, 4M can handle these tasks efficiently. This eliminates the need for separate models for each task, streamlining deployment and integration in real-world applications.
Excelling in Fine-Tuning for Unseen Tasks
- Transfer Learning: The rich, generalizable representations learned during pre-training enable 4M to excel in fine-tuning for new, unseen tasks. By leveraging the knowledge gained from its multimodal training, 4M can quickly adapt to new tasks with minimal additional training data.
- Efficient Adaptation: Fine-tuning 4M for specific applications is both time-efficient and resource-efficient, making it an attractive option for industries that require quick turnaround times for model development and deployment.
Functioning as a Generative Model Conditioned on Arbitrary Modalities
- Cross-Modal Generation: One of the most powerful features of 4M is its ability to generate outputs conditioned on arbitrary input modalities. For instance, the model can generate descriptive text from an image or create an image based on a text description.
- Multimodal Interactions: The ability to handle and generate data across different modalities allows 4M to support complex interactions between them. This is particularly useful in applications like multimodal content creation, augmented reality, and interactive AI systems.
4M Training Methodology
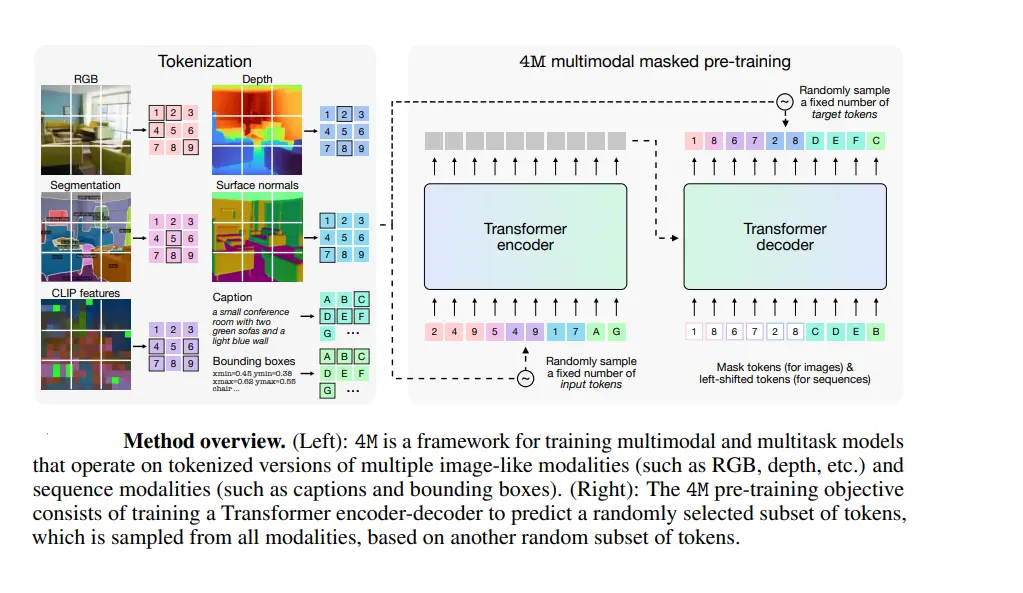
Modalities and Data
The 4M (Massively Multimodal Masked Modeling) framework is designed to integrate and learn from a diverse set of data modalities. This integration allows the model to perform a wide range of vision tasks by understanding and processing information from different types of data. Here are the key modalities used in 4M:
RGB Images:
- Standard color images that capture visual information in three channels (red, green, and blue). These are commonly used in tasks such as object detection, classification, and segmentation.
Captions:
- Text descriptions that provide semantic information about the content of an image. Captions help the model understand the relationship between visual and textual data, enabling tasks like image captioning and visual question answering.
Depth Maps:
- Images where each pixel value represents the distance from the camera to the objects in the scene. Depth maps are crucial for tasks requiring spatial understanding, such as 3D reconstruction and autonomous navigation.
Surface Normals:
- Images that depict the orientation of surfaces within a scene. Each pixel in a surface normal map encodes the direction of the surface normal vector at that point, which is essential for understanding the geometry of objects.
Semantic Segmentation Maps:
- Images where each pixel is labeled with a class corresponding to the object or region it belongs to. Semantic segmentation maps are used for tasks that require detailed scene understanding, such as autonomous driving and medical imaging.
Bounding Boxes:
- Rectangular boxes that define the location and extent of objects within an image. Bounding boxes are used in object detection tasks to localize and classify objects.
CLIP Feature Maps:
- High-dimensional feature representations generated by the CLIP (Contrastive Language-Image Pretraining) model. These feature maps capture rich semantic information that can be used for various vision tasks, enhancing the model's understanding of the visual content.
Pseudo Labeling
To train the 4M model on a large-scale multimodal/multitask dataset, pseudo labeling is employed. Pseudo-labeling involves generating labels for unlabeled data using existing models or heuristics, creating a richer training dataset.
Process of Pseudo Labeling:
- Source Datasets: Use publicly available datasets like CC12M (Conceptual Captions 12M) which contain a large number of image-caption pairs. These datasets provide a solid foundation for training on diverse visual content.
Label Generation:
- Pre-trained Models: Utilize pre-trained models to generate labels for additional modalities. For example, an object detection model can be used to generate bounding boxes, while a depth estimation model can produce depth maps.
- Heuristic Methods: Apply heuristic methods to infer labels from available data. For instance, surface normals can be approximated from depth maps using geometric principles.
Integration: Combine the generated labels with the original dataset to create a comprehensive multimodal/multitask dataset. This enriched dataset allows the 4M model to learn from a wide range of modalities, improving its generalization and performance across tasks.
Multimodal Transformer
The core of the 4M framework is its architecture, a Multimodal Transformer. This architecture is based on the Transformer encoder-decoder structure, which has proven highly effective in both NLP and vision tasks due to its flexibility and scalability.
Transformer Encoder-Decoder Structure:
Encoder:
- Self-Attention Mechanism: The encoder uses self-attention to process input sequences, capturing dependencies and relationships between tokens within the same modality. This mechanism allows the model to understand complex patterns and features in the data.
- Positional Encoding: Since Transformers do not inherently capture the order of input tokens, positional encodings are added to provide information about the position of each token in the sequence.
Decoder:
- Cross-Attention Mechanism: The decoder uses cross-attention to incorporate information from the encoded input sequence. This allows the model to generate outputs that are conditioned on the input data, making it capable of tasks like text generation from images or vice versa.
- Masked Attention: During training, the decoder masks certain positions to predict the masked tokens, reinforcing the model’s ability to infer missing information.
Handling Multiple Modalities:
- Unified Token Representation: All modalities are converted into a unified token format through modality-specific tokenization. This allows the model to process different types of data within a single architecture.
- Shared Embedding Space: Tokens from different modalities are embedded into a shared space, enabling the model to learn cross-modal relationships and interactions.
- Multimodal Training Objective: The multimodal masked modeling objective trains the model to predict masked tokens across different modalities, encouraging the learning of general, transferable features.
What is Masking?
Masking involves temporarily hiding or "masking" certain tokens or elements within a sequence during the training phase of a model. The model is then trained to predict these masked tokens based on the surrounding context. This technique is primarily used in models based on the Transformer architecture, such as BERT (Bidirectional Encoder Representations from Transformers) and its variants, which are foundational to 4M.
Why is Masking Needed in 4M?
- Contextual Understanding: Masking helps the model learn to predict missing words or tokens in a sequence based on the context provided by the other tokens. This encourages the model to develop a deeper understanding of how different parts of the sequence relate to each other.
- Pre-training: Before fine-tuning on specific tasks or domains, models like 4M are initially pre-trained on vast amounts of text data. Masking is crucial during this pre-training phase because it allows the model to learn bidirectional representations of language. By predicting masked tokens, the model learns to capture both left and right context, enabling more nuanced understanding of language.
- Generalization: Masking encourages the model to generalize its understanding beyond simple memorization of input-output pairs. Instead, it learns to infer meanings from context, which is essential for tasks like natural language understanding, where the same word can have different meanings depending on its context.
- Multimodal Integration: In the context of 4M, masking may also extend to other modalities like images or audio. For example, in multimodal tasks where both text and image inputs are used, masking could involve predicting masked-out portions of the visual input based on textual cues, fostering integrated multimodal understanding.
- Efficient Training: By masking tokens, the model is forced to learn meaningful representations of language or other modalities from incomplete information, which can lead to more efficient training and better generalization to new, unseen data.
Performance and Evaluation
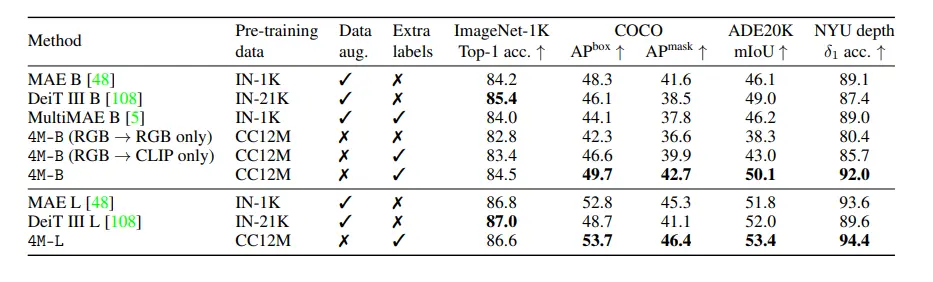
Experimental Results
The 4M (Massively Multimodal Masked Modeling) framework has been extensively evaluated across various benchmarks and experimental setups to demonstrate its versatility and performance. These evaluations highlight 4M’s ability to handle multiple vision tasks effectively and achieve competitive performance on unseen tasks.
Key Vision Tasks:
Image Classification:
- Dataset: Evaluated on standard datasets like ImageNet.
- Performance: 4M models exhibit strong performance, comparable to state-of-the-art classification models. The ability to leverage multimodal information (e.g., captions or depth maps) further enhances classification accuracy.
Object Detection:
- Dataset: Tested on COCO (Common Objects in Context) dataset.
- Performance: 4M achieves competitive results in object detection, with precise localization and classification of objects. The unified model structure allows it to integrate contextual information from other modalities, improving detection performance.
Semantic Segmentation:
- Dataset: Evaluated on datasets like PASCAL VOC and Cityscapes.
- Performance: The model demonstrates high accuracy in segmenting images into meaningful regions. Multimodal training, particularly with depth and surface normal information, contributes to more accurate boundary delineation and region classification.
Depth Estimation:
- Dataset: Tested on NYU Depth V2 and KITTI datasets.
- Performance: 4M provides accurate depth maps, benefiting from the joint training on RGB images and other modalities. The model’s ability to understand geometric relationships within scenes leads to superior depth estimation results.
Performance on Unseen Tasks:
One of the standout features of 4M is its ability to generalize to unseen tasks with minimal fine-tuning. This capability is evaluated through transfer learning experiments:
Fine-Tuning on New Tasks:
- Process: The pre-trained 4M model is fine-tuned on datasets for tasks it was not initially trained on, such as visual question answering (VQA) or image-to-text generation.
- Results: 4M consistently outperforms baseline models when fine-tuned on new tasks, demonstrating the effectiveness of its multimodal pre-training in learning generalizable features.
Zero-Shot Learning:
- Evaluation: Tested on tasks where the model is directly applied without any task-specific fine-tuning.
- Performance: Even in zero-shot settings, 4M shows competitive performance, particularly in tasks that involve understanding and generating multimodal content.
Use Cases of 4M
Autonomous Vehicles: The 4M model can significantly enhance the capabilities of autonomous vehicles. By integrating multiple types of sensory data such as RGB images from cameras, depth maps from LiDAR, and semantic segmentation maps, 4M can provide a comprehensive understanding of the vehicle's surroundings.
For example, an autonomous vehicle navigating through a busy urban intersection. Equipped with the 4M model, the vehicle seamlessly integrates RGB images captured by its cameras, depth maps from LiDAR sensors, and semantic segmentation maps of the environment.
Healthcare and Medical Imaging: In the healthcare sector, 4M can revolutionize medical imaging and diagnostics. By combining various imaging modalities, such as MRI scans, CT scans, and X-rays with textual medical records and annotations, the model can provide more accurate and comprehensive diagnostic insights.
For example, a radiologist could use 4M to integrate MRI images with patient history and symptom descriptions to detect anomalies and predict potential health issues more accurately.
Content Creation and Media Production: 4M can be a game-changer in the content creation and media production industry. By leveraging its ability to understand and generate multimodal data, 4M can automate and enhance various aspects of media production.
For example, it can generate high-quality images or videos based on textual descriptions, making it an invaluable tool for creative professionals like graphic designers and filmmakers. Additionally, 4M can be used to create captions, summaries, and translations for multimedia content, making it accessible to a broader audience.
Conclusion
The 4M (Massively Multimodal Masked Modeling) framework represents a significant advancement in the field of machine learning, particularly in its ability to integrate and process diverse types of data.
By utilizing a unified Transformer model capable of handling multiple modalities, 4M achieves remarkable versatility and performance across a wide range of vision and multimodal tasks.
Its applications span various real-world scenarios, from enhancing the safety and functionality of autonomous vehicles to revolutionizing medical diagnostics and accelerating content creation in the media industry. The model's ability to learn from and integrate rich, multimodal datasets paves the way for more intelligent and adaptable AI systems, offering substantial benefits to researchers, developers, and end-users alike.
As multimodal models like 4M continue to evolve, they hold the promise of driving innovation and efficiency across numerous domains, ultimately contributing to more advanced and holistic AI solutions.
FAQs
Q1) What is 4M?
4M stands for Massively Multimodal Masked Modeling. It is a framework that uses a unified Transformer model to handle various types of data (modalities) such as images, text, depth maps, and more, enabling it to perform a wide range of vision and multimodal tasks.
Q2) How does 4M differ from traditional models?
Traditional models are typically specialized for single modalities or specific tasks. In contrast, 4M is designed to integrate and process multiple modalities simultaneously within a single model, providing greater versatility and efficiency.
Q3) What are the primary applications of 4M?
4M can be used in various applications, including autonomous vehicles (for enhanced perception and navigation), medical imaging (for improved diagnostic accuracy), and content creation (for generating multimedia content and enhancing media production processes).
Q4) Can 4M be fine-tuned for specific tasks?
Yes, 4M can be fine-tuned for specific tasks. Its pre-trained multimodal model can quickly adapt to new applications with minimal additional training, making it highly versatile and effective for various specialized tasks.
Q5) What are the key benefits of using 4M?
The key benefits of 4M include its ability to handle multiple data modalities within a single model, perform a wide range of tasks out of the box, generate outputs based on diverse inputs, and adapt quickly to new tasks. This leads to enhanced efficiency, scalability, and performance across different domains.
Reference:
1) 4M: Massively Multimodal Masked Modeling(Paper)
2) 4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities(Paper)

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
