

7 Top NLP Libraries For NLP Development


Natural Language Processing (NLP) is a fascinating field of Artificial Intelligence that teaches machines to understand and use human language.Think of it like giving computers the ability to read, write, and talk just like we do!
NLP is like having a super-smart assistant who can interpret the meaning and emotions behind our words.
Did you know?
- In 2022, the global NLP market was valued at around $10 billion, and it’s growing super fast!
- The global Natural Language Processing (NLP) market size is projected to grow from $29.71 billion in 2024 to $158.04 billion by 2032, at a CAGR of 23.2%
- In 2023, GPT-4, a successor to GPT-3, set records by training on an astonishing 1 trillion words!
NLP is all around us—helping doctors understand patient data, powering Siri and Alexa, and making search engines find exactly what you need.
It’s like having a smart friend that helps computers interact with humans seamlessly.
But NLP development wouldn’t be where it is today without the incredible libraries available to developers.
NLP libraries are the backbone of NLP applications, providing tools to process, analyze, and structure text data. These libraries make it possible to classify text, detect sentiment, extract information, and even train chatbots.
From speeding up text analysis to enabling complex deep learning models, NLP libraries simplify development and improve results.
In this article, you’ll discover 7 top NLP libraries for NLP development in 2024. We’ll explore their features, strengths, and why they’re essential for building intelligent applications in the ever-evolving AI landscape!
What is NLP?
NLP stands for Natural Language Processing, and it’s the technology behind teaching computers to read, understand, and process human language.
Here’s why NLP is so impressive:
- Fast Data Analysis: It can process thousands of pages of text in just seconds.
- Sorting Information: NLP can classify text, helping machines determine if a message is happy, sad, or something else.
- Emotion Recognition: It teaches robots to recognize emotions in text.
NLP libraries play a key role by converting text into structured data that can be easily used in Machine Learning (ML) or Deep Learning (DL) systems.A good NLP library should:
- Accurately organize text into usable features.
- Provide an easy-to-learn interface for developers.
- Use the most advanced methods and models effectively.
From simplifying text analysis to powering everyday tools, NLP is the backbone of modern AI systems!
Table Of Content
1. NLTK (Natural Language Toolkit)
NLTK is a widely used library for developing Python applications that engage with natural human language data, offering a hands-on introduction to language processing programming.
Many text-processing libraries for sentence identification, tokenization, lemmatization, stemming, parsing, chunking, and POS tagging are included with NLTK.

The library has all of the fundamental features needed to do nearly every type of Python natural language processing operation.
NLTK offers lexical resources and more than 50 corpora with user-friendly interfaces.
It helps computers read and process words and sentences, and understand their meaning. It understands words and helps computers understand stories and messages.
Pros:
(i) NLTK offers various tools and modules for natural language processing (NLP), including tokenization, stemming, tagging, parsing, and semantic reasoning.
(ii) NLTK is an excellent educational tool for teaching computational linguistics using Python.
(iii) NLTK has a large and active community as a popular and widely used library.
(iv) NLTK is open-source, allowing users to modify and customize the code according to their needs.
Cons:
(i) NLTK might not be the most performant library for large-scale or production-grade applications.
(ii) Certain NLTK functionalities may depend on external tools or resources, which can be an additional setup step.
(iii) Some users have noted that NLTK updates are less frequent than other NLP libraries, potentially leading to outdated features or compatibility issues.
Pricing
NLTK is an open-source library and is freely available for use. There are no licensing costs associated with NLTK.
Use Cases :

(i) Text Classification: NLTK can be used for sentiment analysis, spam detection, and other text classification tasks.
(ii) Information Extraction: Extracting structured information from unstructured text is facilitated by NLTK through techniques like named entity recognition.
(iii) Language Understanding: NLTK supports tasks such as part-of-speech tagging, syntactic parsing, and semantic reasoning, contributing to language understanding applications.
(iv) Chatbot Development: NLTK is commonly employed to develop chatbots for natural and context-aware conversations.
(v) Text Generation: NLTK's tokenization and syntactic parsing tools make it useful for text generation tasks, including language modeling and creative writing applications.
2. Gensim

Gensim is an open-source Python library for natural language processing (NLP) and topic modeling.
It was developed by Radim Rehurek and is designed to efficiently extract semantic topics from extensive text collections.
Gensim is particularly well-suited for handling large corpora and for training models for topic modeling, document similarity analysis, and other NLP tasks.
Gensim's user-friendly interfaces enable effective multiprocess implementations of well-known techniques, such as word2vec deep learning, online Latent Semantic Analysis (LSA/LSI/SVD), Latent Dirichlet Allocation (LDA), Random Projections (RP), and Hierarchical Dirichlet Process (HDP).
Jupyter Notebook tutorials and copious documentation are available in Gensim.
NumPy and SciPy are primarily used in scientific computing. Therefore, before installing Gensim, you must install these two Python packages.
Gensim is created explicitly for topic modeling, document indexing, and similarity retrieval with large corpora.
Since every method in Gensim is memory-independent for corpus size, it can handle input that is greater than RAM.

Pros:
(i) Efficiency and Scalability: Gensim is optimized for efficiency and can handle large text datasets efficiently. It uses memory-mapped I/O and streaming processing, making it scalable for large corpora.
(ii) Topic Modeling: Gensim excels in topic modeling tasks, allowing users to discover hidden topics within a collection of documents. Popular algorithms like Latent Semantic Analysis (LSA) and Latent Dirichlet Allocation (LDA) are implemented in Gensim.
(iii) Word Embeddings: Gensim supports training and using word embeddings through algorithms like Word2Vec and Doc2Vec. Word embeddings capture semantic relationships between words, enabling applications such as word similarity and analogy.
(iv) Easy-to-Use Interface: Gensim provides a user-friendly interface for common NLP tasks, making it accessible for researchers and practitioners. The library is well-documented, and its API is relatively easy to understand.
(v) Compatibility: Gensim integrates well with other popular Python libraries such as NumPy, SciPy, and sci-kit-learn, providing a comprehensive ecosystem for NLP and machine learning tasks.
Cons:
(i) Sparse Documentation: While Gensim has improved its documentation over time, some users may find it less comprehensive than other NLP libraries, making it challenging for beginners to get started.
(ii) Limited Deep Learning Support: Gensim was initially developed before the deep learning era, and while it supports Word2Vec and Doc2Vec for word embeddings, it may not be as feature-rich as deep learning-focused libraries like TensorFlow or PyTorch.
Use Cases:
(i) Topic Modeling: Gensim is widely used to uncover topics in extensive document collections, aiding in document clustering and summarization.
(ii) Document Similarity: Gensim can be applied to measure the similarity between documents, helping in tasks like document retrieval and recommendation systems.
(iii) Word Embeddings: The library is employed for training word embeddings, which can be utilized in various NLP applications such as sentiment analysis, part-of-speech tagging, and named entity recognition.
(iv) Text Summarization: Gensim can be used to extract key information and generate summaries from large documents, making it valuable for text summarization tasks.
(v) Information Retrieval: Gensim is employed in information retrieval scenarios, helping to index and search through large text corpora efficiently.
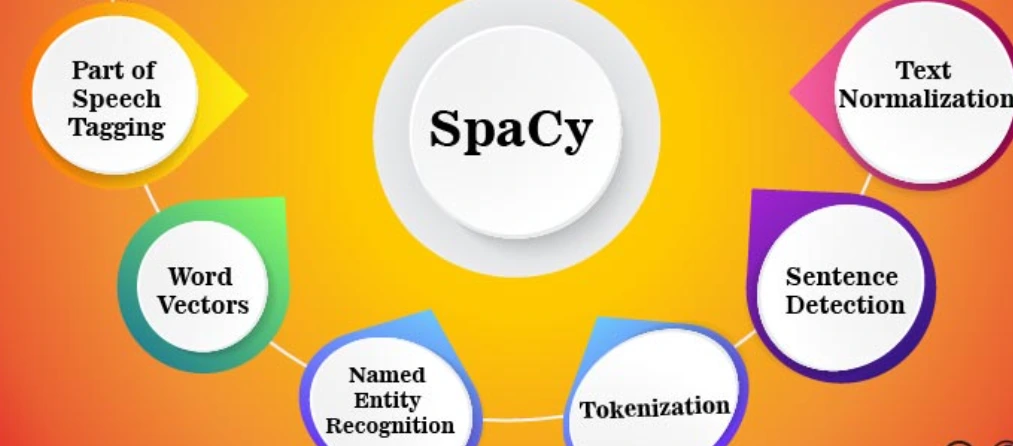
3. spaCy
spaCy is an open-source natural language processing (NLP) library designed for efficient and scalable processing of textual data.
It provides pre-trained models for various languages and allows users to perform tasks such as tokenization, part-of-speech tagging, syntactic parsing, and more.
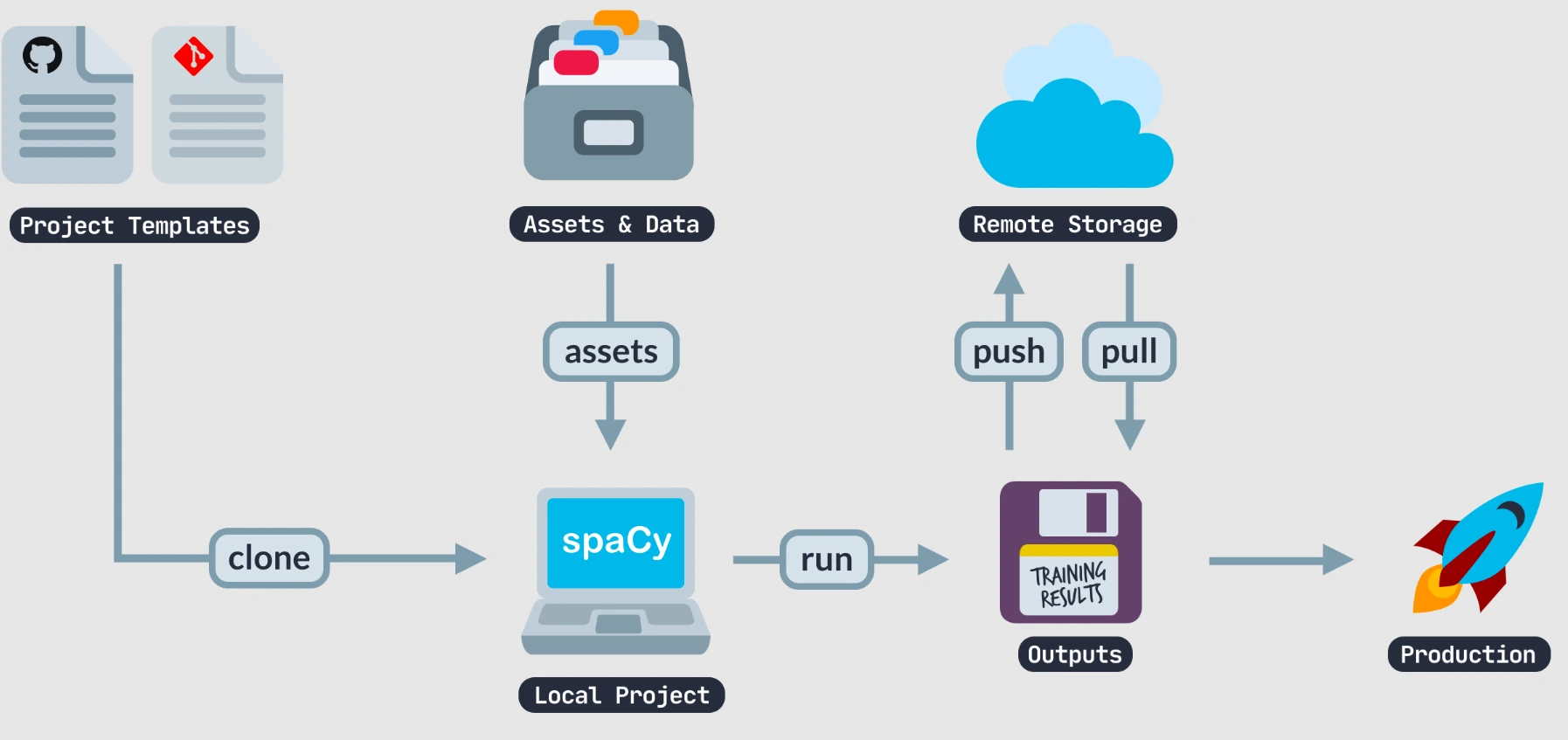
Python NLP library spaCy is available for free download. You can create apps that process and comprehend large amounts of text using it because it is specifically made for production use.
spaCy can preprocess text for Deep Learning. Information extraction systems and systems for interpreting natural language can be constructed with it.
Word vectors and statistical models that have already been trained are included in spaCy. Over 49 languages are supported for tokenization.
Innovative features of spaCy include named entity recognition, speed, parsing, tagging with convolutional neural network models, and deep learning integration.
Pros:
(i) Efficiency: spaCy is known for its speed and efficiency. It is designed to be fast and can quickly process large amounts of text, making it suitable for production environments.
(ii) Pre-trained Models: spaCy has pre-trained models for multiple languages, covering various NLP tasks. This allows users to get started quickly without the need to train models from scratch.
(iii) Integration: spaCy is easily integrated with other popular NLP and machine learning libraries like scikit-learn, TensorFlow, and PyTorch, making it versatile for building complex pipelines.
(iv) User-Friendly: The library is designed to be user-friendly with straightforward APIs and easy-to-understand documentation. This makes it accessible to both beginners and experienced NLP practitioners.
(v) Support for Multiple Languages: spaCy supports multiple languages, which is crucial for projects dealing with multilingual data.
(vi) Active Community: spaCy has a vibrant and active community, that provides continuous support, updates, and a variety of resources for users.
Cons:
(i) Customization Limitations: While spaCy provides pre-trained models, customization of these models for specific domains might be limited compared to other frameworks.
(ii) Learning Curve: Although spaCy is designed to be user-friendly, there might still be a learning curve for those new to NLP or programming in general.
(iii) Resource Intensive: The memory requirements of spaCy can be relatively high, especially when using large models. This can be a consideration for resource-constrained environments.
Use Cases:
(i) Named Entity Recognition (NER): spaCy is commonly used to extract entities such as names of people, organizations, locations, and more from text.

(ii) Part-of-Speech Tagging (POS): Identifying the grammatical parts of speech (nouns, verbs, adjectives, etc.) is a fundamental task in NLP, and spaCy excels in this area.
(iii) Dependency Parsing: Analyzing the grammatical structure and relationships between words in a sentence is crucial for understanding the meaning of the text, and spaCy facilitates this through dependency parsing.
(iv) Text Classification: spaCy can be used for text classification tasks, such as sentiment analysis or topic categorization.
(v) Information Extraction: Extracting structured information from unstructured text, such as events, relationships, or key facts, can be achieved using spaCy.
4. CoreNLP
CoreNLP (Stanford CoreNLP) is a natural language processing (NLP) library developed by the Stanford Natural Language Processing Group.
It provides a set of tools for processing and analyzing human language, making it easier for developers to integrate NLP capabilities into their applications.
CoreNLP supports a wide range of NLP tasks, including part-of-speech tagging, named entity recognition, sentiment analysis, coreference resolution, parsing, and more.

It attempts to simplify the process of applying linguistic analysis techniques to a document.
Because CoreNLP is developed in Java, your device must have Java installed to use it.
However, it provides programming interfaces for a wide range of well-known programming languages, such as Python.
CoreNLP is also compatible with Arabic, Chinese, German, French, and Spanish, and English.
Use Cases:
(i) Information Extraction: CoreNLP can be used to extract structured information from unstructured text, including named entities, relationships, and events.
(ii) Sentiment Analysis: The library is suitable for analyzing and determining sentiment in text, which can be valuable for applications like social media monitoring or customer feedback analysis.
(iii) Document Summarization: CoreNLP can assist in summarizing large documents by extracting key information and generating concise summaries.
(iv) Question Answering: It can be employed in question-answering systems, helping to process and understand user queries and provide relevant responses.
(v) Coreference Resolution: CoreNLP's coreference resolution capabilities can be used to identify when different expressions in a text refer to the same entity, improving overall understanding.
(vi) Dependency Parsing: The library's parsing capabilities can aid in syntactic analysis, allowing developers to extract grammatical relationships between words in a sentence.

Pros:
(i) Wide Range of NLP Tasks: CoreNLP supports a comprehensive set of NLP tasks, making it a versatile choice for various natural language processing applications.
(ii) Integrated Pipeline: It offers a unified pipeline for processing text, allowing users to perform multiple NLP tasks seamlessly without needing separate tools.
(iii) Multilingual Support: CoreNLP supports multiple languages, making it suitable for applications in a global context.
(iv) Pre-trained Models: CoreNLP comes with pre-trained models for various tasks, saving users the effort of training models from scratch.
(v) Active Development: The Stanford NLP Group actively develops and maintains the library, ensuring updates and improvements over time.
Cons:
(i) Resource Intensive: CoreNLP can be resource-intensive, especially when processing large amounts of text or dealing with complex linguistic analysis.
This might be a concern for applications with strict resource constraints.
(ii) Dependency on Java: CoreNLP is primarily implemented in Java, which might be a limitation for developers working in environments where Java integration is challenging or not preferred.
(iii) Limited Customization: While CoreNLP provides pre-trained models, customization options for these models are somewhat limited compared to some other NLP libraries.
5. TextBlob

TextBlob is a Python (2 & 3) library for processing textual data, especially for natural language processing (NLP) tasks.
It is built on top of other popular NLP libraries such as NLTK (Natural Language Toolkit) and Pattern.
TextBlob provides a simple API for everyday NLP tasks, making it easy for users to perform tasks like part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more.
Its main goal is to give users familiar interfaces to access popular text-processing functions.
Use Cases:
(i) Sentiment Analysis: Determine the sentiment of a piece of text, which is useful for gauging opinions, feedback, and reviews.

(ii) Part-of-Speech Tagging: Identify and extract parts of speech in a sentence, which is fundamental for many NLP tasks.
(iii) Noun Phrase Extraction: Extract important noun phrases from text, aiding in information extraction and summarization.
(iv) Text Classification: Classify documents into predefined categories, making it suitable for tasks like spam detection, topic categorization, etc.
(v) Language Translation: TextBlob supports language translation, enabling text conversion from one language to another.
(vi) Named Entity Recognition (NER): Identify and classify named entities (e.g., names, locations, organizations) within the text.
Pros:
(i) Simplicity: TextBlob offers a simple and easy-to-use API, making it accessible for users with varying levels of expertise in NLP.
(ii) Integration with NLTK and Pattern: TextBlob leverages the capabilities of NLTK and Pattern, allowing users to benefit from the functionality of these libraries.
(iii) Ease of Learning: The library is designed to be beginner-friendly, making it a good choice for those who are new to NLP and want to get started quickly.
(iv) Sentiment Analysis: TextBlob includes built-in tools for sentiment analysis, making it convenient for analyzing the sentiment of text data.
Cons:
(i) Limited Complexity: While TextBlob is suitable for common NLP tasks, it may lack the advanced features and customization options required for more complex tasks.
(ii) Performance: TextBlob might not be as efficient for large-scale or resource-intensive taskst as some lower-level NLP libraries.
6. Pattern

Pattern is a Python library for natural language processing (NLP) and machine learning. It helps in various NLP tasks, including tokenization, part-of-speech tagging, named entity recognition, sentiment analysis, and more.
Pattern is a library for network analysis, natural language processing, text processing, web mining, and machine learning.
It has many features included for data mining (Google, Twitter, Wikipedia API, web crawler, and HTML DOM parser), natural language processing (NLP), machine learning (ML), sentiment analysis (WordNet, n-gram search, vector space model, clustering, SVM, and network analysis.
Both scientific and non-scientific audiences can benefit significantly from the use of patterns.
Its syntax is clear-cut and uncomplicated; the commands are self-explanatory due to the clever selection of function names and arguments.
Pattern is a rapid development framework for web developers and also provides a very excellent learning environment for students.
Pros:
(i) Ease of Use: Pattern is designed to be user-friendly and provides a simple API for common NLP tasks, making it accessible for beginners.
(ii) Wide Range of Functions: It offers a diverse set of functionalities, including text processing, web mining, machine learning, and network analysis.
(iii) Integration with Other Libraries: Pattern can be easily integrated with other popular Python libraries, such as NumPy and scikit-learn, enhancing its capabilities.
(iv) Multilingual Support: The library supports multiple languages, which can benefit projects involving text in various languages.
Cons:
(i) Limited Documentation: One common criticism of Pattern is that its documentation is somewhat limited compared to other NLP libraries, which might make it challenging for users to fully leverage its capabilities.
(ii) Performance: While Pattern is suitable for basic NLP tasks, it might not be as performant or scalable as some other specialized libraries for large-scale applications or more complex tasks.
(iii) Slow Development Activity: The development of Pattern seemed to have slowed down, with the last official release being a few years ago. This could be a concern for users looking for actively maintained libraries with up-to-date features and bug fixes.
Use Cases:
A pattern can be applied in various NLP applications, including:
(i) Text Processing: Tokenization, stemming, and other basic text processing tasks.
(ii) Part-of-Speech Tagging: Identifying the grammatical parts of speech for each word in a given text.
(iii) Named Entity Recognition (NER): Extracting entities such as names, locations, and organizations from text.
(iv) Sentiment Analysis: Determining the sentiment expressed in a piece of text, whether it is positive, negative, or neutral.
(v) Web Mining: Extracting information from websites and analyzing text data obtained from the web.
7. PyNLPl (Pineapple)
PyNLPl (pronounced 'pineapple') is a Python library designed for Natural Language Processing (NLP) tasks.
It includes several specially designed Python modules for tasks related to NLP.
Each of the several modules and packages that make up PyNLPl is helpful for both simple and complex NLP jobs.
PyNLPl offers more complex data types and algorithms for advanced NLP activities, but it can also be used for fundamental NLP tasks like building a simple language model and extracting n-grams and frequency lists.
It can do simple things like counting words and more complicated tasks like working with special types of writing.
Use Cases:
(i) Text Processing: PyNLPl can be used for basic text processing tasks like n-gram analysis, frequency counting, and simple language modeling.
(ii) Linguistic Annotation: The extensive support for FoLiA XML makes PyNLPl suitable for projects involving linguistic annotation and analysis.
(iii) File Format Conversion: With its file format parsers, PyNLPl can be employed for converting and processing data in different NLP file formats.
(iv) Advanced NLP Tasks: PyNLPl's inclusion of more complex data types and algorithms makes it applicable for advanced NLP tasks such as machine translation, language modeling, and parsing.
Pros:
(i) Versatility: PyNLPl supports a wide range of NLP tasks, from basic to advanced, making it versatile for different applications.
(ii) FoLiA XML Support: The extensive support for FoLiA XML can be beneficial for projects involving linguistic annotation.
(iii) File Format Parsers: The inclusion of parsers for multiple file formats used in NLP enhances its utility in dealing with diverse data sources.
(iv) Server Interfacing: Clients for interfacing with NLP servers provide flexibility in integrating PyNLPl with existing server-based solutions.
Cons:
(i) Learning Curve: Given its extensive capabilities and various modules, there might be a learning curve for users new to the library.
(ii) Documentation: The effectiveness of the library could be influenced by the availability and comprehensiveness of documentation. If not well-documented, it may pose challenges for users.
Conclusion
Natural Language Processing (NLP) is like teaching computers to understand and use human language. It's a part of Artificial Intelligence that allows machines to read, write, and talk just like us!
NLP has achieved incredible things, helping computers analyze large amounts of text quickly, classify different types of messages, and even understand emotions.
Thanks to NLP and its libraries like NLTK, Gensim, spaCy, CoreNLP, TextBlob, Pattern, and PyNLPl, that helps computers to read, understand, and talk, making our lives easier.
These libraries are like toolkits that help programmers make computers smart and efficient when it comes to language.
So, next time you use a voice assistant or search the internet, remember that NLP is the superhero behind the scenes, making it all possible!
Frequently Asked Questions
1. Which NLP library should I use if I'm a beginner?
If you're a beginner, start with NLTK (Natural Language Toolkit) or spaCy. They're easy to use and have lots of helpful tools for understanding and working with human language.
2. What is natural language processing (NLP)?
Natural Language Processing (NLP) is a field of artificial intelligence (AI) that focuses on the interaction between computers and humans through natural language.
The goal of NLP is to enable computers to understand, interpret, and generate human language in a way that is both meaningful and contextually relevant.
It involves the development of algorithms and models that can analyze and process text or speech data, allowing machines to perform tasks such as language translation, sentiment analysis, text summarization, and chatbot interactions.
NLP combines techniques from computer science, linguistics, and machine learning to bridge the gap between human communication and computer understanding.
3. What is an NLP architect?
NLP Architect refers to a natural language processing (NLP) library developed by Intel AI Lab.
It is designed to provide researchers and developers with a set of pre-built models and tools for various NLP tasks.
NLP Architect aims to make it easier for individuals and organizations to implement state-of-the-art NLP solutions without having to build models from scratch.

Simplify Your Data Annotation Workflow With Proven Strategies
Download the Free Guide