

Evaluating and Finetuning Text To Image Model - Case Study


Table of Contents
- Introduction
- Why Evaluate and Fine-Tune These Models
- How Fine-Tuning is Done for Text-to-Image Models
- Challenges Faced in Evaluating and Fine-Tuning Text-to-Image Models
- Case Study: Improving Text-to-Image Models for a Content Creation Client
- Conclusion
- FAQ
Introduction
Text-to-image models are advanced AI systems designed to generate visual content from textual descriptions. These models leverage deep learning techniques to interpret and transform textual input into corresponding images, making them incredibly useful across various domains.
For content generation, these models offer creative tools for artists, designers, and marketers, enabling the rapid creation of visual assets. Additionally, in digital asset management, they streamline the process of generating images based on textual metadata, thus enhancing workflow efficiency.
Evaluating and fine-tuning text-to-image models is crucial to ensure they produce high-quality and accurate images that meet user expectations and application requirements. Evaluation involves assessing the model's performance using metrics that measure the accuracy, relevance, and quality of the generated images.
This step is essential for identifying strengths and weaknesses in the model's output. Fine-tuning, on the other hand, involves adjusting the model based on evaluation results to improve its performance. This process includes enhancing training data, refining algorithms, and incorporating user feedback.
By thoroughly evaluating and fine-tuning these models, developers can enhance their robustness, adaptability, and overall user satisfaction, ensuring they serve their intended purposes effectively and reliably.
Why Evaluate and Fine-Tune These Models
Evaluating and fine-tuning text-to-image models is essential for ensuring their accuracy. Accurate image generation from textual descriptions is critical as it ensures that the outputs match the input prompts closely.
Without rigorous evaluation and fine-tuning, the generated images might not accurately represent the textual input, leading to user dissatisfaction and reduced trust in the model.
Consistency across different prompts is another crucial reason for evaluating and fine-tuning these models. A reliable model must produce consistent results across various scenarios.
Through evaluation, inconsistencies can be identified, and fine-tuning addresses these issues, resulting in more predictable and dependable outputs.
User satisfaction is significantly enhanced when the model produces high-quality and contextually appropriate images. Fine-tuning models based on evaluation feedback helps achieve this, making the outputs more visually appealing and relevant, thereby improving user experience and engagement.
Adaptability is essential, as different applications and industries have unique requirements. Fine-tuning allows the models to be tailored to specific domains, ensuring that the generated images meet the particular needs of different use cases, such as medical imaging, entertainment, or advertising.
Ethical considerations are also a crucial factor. Evaluating and fine-tuning help identify and mitigate biases present in the model, ensuring ethical use of AI. This process helps create fairer and more inclusive models that do not propagate harmful stereotypes or biases.
Lastly, performance optimization is a key reason for evaluating and fine-tuning. Regular evaluation helps monitor the model’s performance over time, ensuring it remains efficient and effective.
Fine-tuning based on these evaluations can address performance degradation and optimize resource usage, leading to more efficient model operation.
How Is Evaluation Done For These Models
The evaluation process combines quantitative metrics, qualitative analysis, benchmarking, and user feedback to assess model performance comprehensively.
The chart below compares different Text to image models on MS-COCO 5K test set. Here baselines are from DALL-Eval and ground truth represents the theoretical upper bound on this evaluation with captions generated using MS-COCO images as inputs to the VL-T5 model. Parti samples 16 images per text prompt and uses a CoCa model to rank the outputs.
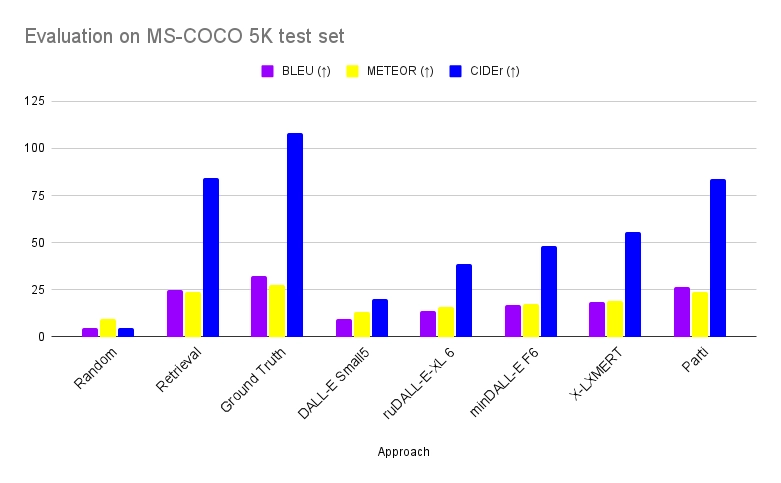
The metrics shown in the chart are explained below.
Quantitative Metrics
Inception Score (IS): The Inception Score is a widely-used metric for evaluating the quality of generated images. It is based on the premise that good models should produce images with distinct objects (high classification confidence) and diverse classes (high variety).
IS calculates the KL-divergence between the conditional label distribution and the marginal label distribution of the generated images using a pre-trained Inception model. A higher score indicates better quality and diversity of generated images, making it a common choice for assessing the performance of Generative Adversarial Networks (GANs) and other generative models.
Fréchet Inception Distance (FID): FID measures the distance between the feature distributions of the generated and real images. By passing images through an Inception network and comparing the means and covariances of the feature maps, FID captures the quality and realism of the generated images.
Lower FID scores indicate better quality, making it more robust and accurate than IS in many cases. FID is particularly favored for evaluating GANs, providing a reliable sense of how similar the generated images are to real ones.
Other Metrics: Other important metrics include Precision and Recall, which assess the coverage and quality of the generated image distribution relative to the real image distribution.
SSIM (Structural Similarity Index) measures the perceptual difference between generated and real images, while LPIPS (Learned Perceptual Image Patch Similarity) evaluates perceptual similarity using deep network features. These metrics together provide a comprehensive quantitative assessment of model performance.
Qualitative Analysis
Human Evaluations: Human evaluations play a crucial role in qualitative analysis. Surveys involving human raters assess the quality of generated images based on realism, fidelity to the text prompt, and visual appeal.
Experts provide detailed feedback, identifying specific strengths and weaknesses of the model. This subjective assessment is vital for understanding the nuances of image quality that quantitative metrics may not capture.
Visual Inspections: Expert reviews involve visual inspection by domain experts to ensure the generated images meet the required standards of quality and relevance. Comparative analysis, where images generated by different models are compared side-by-side, helps assess relative performance, providing insights into the model's strengths and areas for improvement.
Benchmarking
Comparing Against State-of-the-Art Models: Benchmarking involves comparing new models against well-known baselines such as DALL-E, CLIP, or BigGAN. Using standard datasets like COCO, ImageNet, or CUB-200 ensures fair evaluation and standardizes comparisons.
Tracking model performance on public leaderboards provides a gauge of how models stack up against the competition, offering a clear benchmark for performance.
A/B Testing
User Feedback: A/B testing with user feedback involves preference testing, where users choose between images from different models based on given criteria like relevance to the text prompt and image quality. Usability studies, where users interact with the models in real-world scenarios, provide insights into practical usability and satisfaction.
Performance Metrics: Engagement metrics such as clicks, shares, and likes help track user interactions with the generated images, inferring user satisfaction and preferences. In commercial applications, measuring the impact of generated images on conversion rates or other business-critical metrics helps refine models based on real-world feedback.
How Fine-Tuning is Done for Text-to-Image Models
Fine-tuning text-to-image models involves several complex strategies aimed at enhancing the model's ability to generate high-quality and contextually accurate images from textual descriptions. The process includes data augmentation, transfer learning, hyperparameter tuning, and reinforcement learning, each contributing uniquely to refining the model's performance.
Data Augmentation
Enhancing Training Data with Variations: Data augmentation is a critical technique used to improve the robustness and generalization of text-to-image models. By creating variations of the existing training data, models are exposed to a wider range of scenarios and examples.
Common data augmentation methods include geometric transformations (e.g., rotations, translations, scaling), color adjustments (e.g., brightness, contrast, saturation changes), and noise addition. For text-to-image models, text augmentations such as paraphrasing or altering sentence structures can also be beneficial.

These variations help the model learn more generalized features, thereby enhancing its ability to generate diverse and high-quality images from different textual inputs.
Transfer Learning
Leveraging Pre-Trained Models:Transfer learning involves using pre-trained models that have already been trained on large datasets and fine-tuning them on specific, often smaller, datasets relevant to the new task. This approach significantly reduces the computational resources and time required to train a model from scratch.
For text-to-image generation, models like BERT, GPT-3, and DALL-E, pre-trained on vast amounts of text and image data, are often fine-tuned on domain-specific datasets. For example, a model pre-trained on a general image dataset can be fine-tuned on a specialized dataset of architectural images to generate more accurate and relevant outputs for architectural design descriptions.
Hyperparameter Tuning
Adjusting Parameters to Optimize Performance:Hyperparameter tuning involves systematically adjusting the parameters that govern the training process of the model to optimize its performance.
Key hyperparameters in text-to-image models include learning rate, batch size, number of epochs, and architecture-specific parameters like the number of layers and units per layer. Techniques such as grid search, random search, and Bayesian optimization are commonly used to find the optimal hyperparameter settings.
Proper tuning of these parameters can lead to significant improvements in the model's ability to generate high-quality images that accurately reflect the given textual descriptions.
Reinforcement Learning
Using Techniques Like Reinforcement Learning with Human Feedback (RLHF):Reinforcement Learning (RL) is employed to iteratively improve the model by using a reward signal to guide its learning process. One advanced technique is Reinforcement Learning with Human Feedback (RLHF), where human evaluators provide feedback on the quality of the generated images.
This feedback is used to adjust the model's parameters and improve its performance over time. RLHF is particularly effective in fine-tuning text-to-image models, as it allows for continuous improvement based on human judgment, ensuring the generated images are not only accurate but also aesthetically pleasing and contextually appropriate.
By integrating human feedback into the reinforcement learning loop, models can better align with user expectations and generate more satisfactory outputs .
Challenges Faced in Evaluating and Fine-Tuning Text-to-Image Models
Text-to-image models, while powerful, encounter several significant challenges that need to be addressed to ensure their effectiveness and fairness. These challenges include issues related to data quality, computational resources, bias and fairness, and generalization.
Data Quality
Ensuring High-Quality and Diverse Training Data:The quality and diversity of training data are paramount for the successful performance of text-to-image models. High-quality data ensures that the model learns accurate and relevant associations between text and images.
Diverse data helps the model generalize across different contexts and avoid overfitting to specific scenarios. However, obtaining such data can be difficult. Datasets must encompass a wide range of objects, scenes, and descriptive texts to cover various use cases.
Additionally, ensuring that the data is annotated accurately and consistently is crucial. Inaccurate annotations can lead to erroneous learning, while lack of diversity may result in the model being unable to handle rare or novel input combinations effectively.
Computational Resources
Managing High Computational Costs of Training and Fine-Tuning:Training and fine-tuning text-to-image models are computationally intensive processes. These models often require powerful hardware such as GPUs or TPUs and substantial time to achieve satisfactory performance.
The computational costs can be a barrier, particularly for smaller organizations or individual researchers who may not have access to extensive computational resources. Additionally, the process of hyperparameter tuning and the iterative nature of reinforcement learning further increase the computational demands.
Efficient use of resources and optimization techniques are essential to manage these costs effectively and make the technology more accessible.
Bias and Fairness
Addressing Biases in Training Data: Bias in training data is a critical issue that affects the fairness and ethical implications of text-to-image models. These biases can arise from imbalanced datasets that over-represent certain groups or scenarios while under-representing others.
Such biases can lead to models that produce biased outputs, reinforcing stereotypes or excluding certain groups. Ensuring fair representation involves carefully curating training datasets to be balanced and diverse, as well as implementing techniques to detect and mitigate bias during the training process. Addressing these biases is crucial for developing models that are fair and ethical in their applications .
Generalization
Ensuring the Model Performs Well on Unseen Data: One of the key challenges in machine learning is ensuring that models generalize well to unseen data. For text-to-image models, this means being able to generate accurate and relevant images from textual descriptions that were not encountered during training.
Overfitting, where a model performs well on training data but poorly on new, unseen data, is a common issue. Techniques such as data augmentation, regularization, and cross-validation are employed to improve generalization.
Additionally, leveraging large-scale pre-trained models and fine-tuning them on specific datasets can help improve the model's ability to handle a wide variety of inputs effectively.
Case Study: Improving Text-to-Image Models for a Content Creation Client
One of our customers, a prominent content creation company was facing significant challenges with their text-to-image generation model. The primary issue was the generation of biased images that often did not align with the company's diverse and inclusive content strategy.

For example, when given descriptions such as "a doctor" or "a leader," the model frequently produced images that reinforced gender and racial stereotypes as you can see in the image. This not only affected the quality and relevance of the generated content but also raised ethical concerns and negatively impacted user satisfaction.
Solution: Reinforcement Learning with Human Feedback
To address this issue, they approached us and we decided to leverage Reinforcement Learning with Human Feedback (RLHF). This approach involves the iterative improvement of the model using feedback from human evaluators. Here’s how the process was implemented:
Initial Evaluation and Feedback Collection: The initial model outputs were evaluated by a diverse group of human reviewers who provided detailed feedback on the generated images. This feedback focused on aspects such as the presence of bias, relevance to the text description, and overall quality.

Reinforcement Learning Implementation: The feedback was used to guide the reinforcement learning process. The model was trained to adjust its parameters based on human evaluations, promoting outputs that aligned better with the company’s inclusivity goals. This involved:
- Adversarial Training: Incorporating adversarial examples in training to help the model learn robust representations. This can include generating adversarial prompts that are specifically designed to expose biases.
- Penalizing biased or stereotypical outputs.
- Rewarding outputs that were diverse and accurately represented the textual descriptions.
- Using techniques such as reward shaping to fine-tune the reward signals received by the model.
Iterative Refinement: The process was iterative, with multiple rounds of generation, evaluation, and feedback. Each round helped in refining the model further, reducing biases, and improving the relevance and quality of the images.
Outcome
The implementation of RLHF led to significant improvements in the model’s performance. Key outcomes included:
- Reduced Bias: The frequency of biased or stereotypical images decreased substantially. The model began to produce more diverse and representative images that aligned with the company’s inclusivity standards.
How to reduce biasedness with RLHF - Enhanced Quality and Relevance: The overall quality of the generated images improved, with better alignment to the text descriptions provided. This led to more accurate and contextually appropriate visual content.

- Increased User Satisfaction: User feedback indicated higher satisfaction with the content, appreciating the diversity and accuracy of the images. This positive reception translated into increased engagement with the company's content.
- Ethical Compliance: The company was able to align its content generation process with ethical standards, ensuring that the visual content was fair and inclusive, thereby enhancing its brand reputation.
Conclusion
Evaluating and fine-tuning text-to-image models is crucial to ensure their performance, relevance, and ethical compliance. These processes help address the inherent challenges of model biases, data quality, and computational demands, ensuring that the generated images meet user expectations and ethical standards.
By continuously assessing model outputs using quantitative metrics like Inception Score (IS) and Fréchet Inception Distance (FID), and qualitative methods such as human evaluations and A/B testing, practitioners can identify areas for improvement and make necessary adjustments.
FAQ
Q1) What are text-to-image models?
Text-to-image models are a type of artificial intelligence that generates images based on textual descriptions. These models use deep learning techniques, particularly neural networks, to interpret the text and create corresponding visual content.
The models typically involve complex architectures that can understand language nuances and translate them into detailed and coherent images.
Q2) Why is fine-tuning important?
Fine-tuning is crucial for enhancing the accuracy, adaptability, and performance of text-to-image models. By fine-tuning, models can be adjusted to perform better on specific tasks or datasets, ensuring that the generated images are more relevant and precise.
This process involves retraining the model on new data or adjusting its parameters to better align with the desired outputs, ultimately leading to improved user satisfaction and more effective model deployment.
Q3) What is Reinforcement Learning with Human Feedback (RLHF)?
Reinforcement Learning with Human Feedback (RLHF) is a method where human feedback is incorporated into the training process of a model to guide and improve its performance. In RLHF, humans evaluate the model’s outputs and provide feedback, which is then used to adjust the model's parameters and learning process.
This iterative approach helps the model learn more effectively from human preferences and judgments, leading to more accurate and human-aligned outputs.
References
1. Scaling Autoregressive Models for Content-Rich Text-to-Image Generation(Link)
2. RE-IMAGEN: RETRIEVAL-AUGMENTED TEXT-TO-IMAGE GENERATOR(Link)

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
