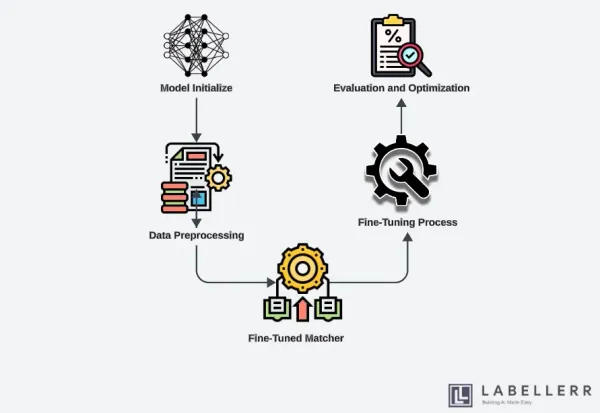
Vision foundation models (VFMs) have become a cornerstone in the field of computer vision. These models, which are trained on large-scale datasets, have demonstrated remarkable capabilities in a wide range of visual perception tasks.
The primary advantage of VFMs lies in their ability to generalize across different domains, making them