

Stop making these mistakes in image labeling for object detection


Image annotation is the most time consuming task in object detection model development journey.
Although the following best practices are generally accurate, it's vital to keep in mind that image labeling guidelines heavily depend on the task in hand.
Additionally, images labeled for one activity might not be appropriate for another — re-labeling is typical. The dataset and its labeling should be viewed as living things that are always evolving to best suit the task at hand.
In this blog, we have provided some tips that will help you do image labeling for object detection effectively. But before that. Let’s understand image labeling and object detection.
Table of Contents
- Image Labeling: What is it?
- Why is Image Labeling Crucial for Machine Learning and AI?
- What is Object Detection?
- Tips on How to Do Image Labeling for Object Detection Effectively
- Challenges That Teams Face in the Image Labeling Process
- How Labellerr Can Help You?
Image labeling: What is it?
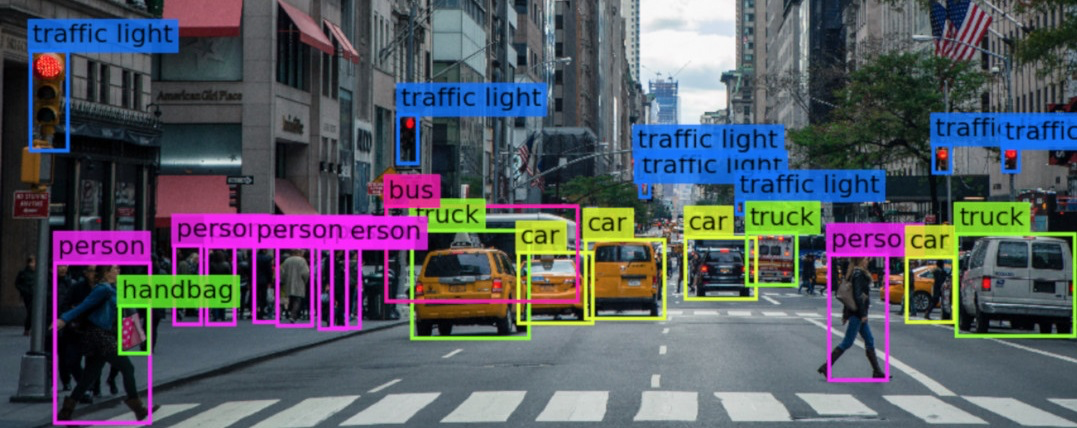
Data labeling that focuses on recognizing and tagging certain details in images is known as Image labeling. Data labeling in computer vision is adding tags to unprocessed data, including photos and videos.
An associated object class with the data is represented by each tag. Labels are used by supervised machine learning algorithms to identify a particular object class in unstructured data. It enables these models to give meaning to the data, which aids in model training.
Data sets for computer vision algorithms are produced using image labeling and are divided into training and test/validation sets.
The training set is used to train the model initially, while the test/validation set is used to assess the model's performance. The dataset is used by data scientists to train and test their models, after which the models may automatically categorize hidden unlabeled data.
Why is image labeling crucial for machine learning and AI?
A crucial step in creating supervised models having computer vision abilities is image tagging. Machine learning models can be trained to label complete images or recognize groups of items within an image. Image tagging is beneficial in the following ways:
- Image labeling tools and approaches aid in highlighting or capturing specific things in an image, assisting in the development of useful artificial intelligence (AI) models. Machines can now understand photographs thanks to these labels, and highlighted images are frequently used as training sets for machine learning and artificial intelligence models.
- Enhancing computer vision—by enabling object recognition, image labeling, and annotation aid to enhance computer vision accuracy. Machine learning and artificial intelligence models can recognize patterns before they can detect and recognize them on their own by being trained with labels.
What is object detection?
A computer vision technology called object detection helps locate and identify things in an image or video. To be more precise, object detection creates bounding boxes all around items it has found, allowing us to determine their location inside (or how they move across) a scene.
Before we continue, it's crucial to make the distinctions between object detection and picture recognition clear as they are sometimes misconstrued.
An image is given a label through image classification. The word "dog" is used to describe an image of a dog. The word "dog" is still used to describe an image of two canines.
Contrarily, object detection surrounds each dog with a box that is labeled "dog." The model forecasts the location of each object and the appropriate label. Consequently, object detection offers more details about a picture than object recognition.
The importance of object detection
Advanced driver assistance systems (ADAS), which enable vehicles to detect traffic lanes or carry out pedestrian detection to increase road safety, rely heavily on object detection as a crucial technology.
Application areas like video surveillance or object data retrieval systems benefit from object detection.
Tips on how to do image labeling for object detection effectively
Today, we understand that only excellent datasets result in extraordinary model performance. The robust performance of a model is attributable to an exact and meticulous data labeling procedure.
It's crucial to understand that data labels use a few "tactics" to hone the data labeling procedure and provide excellent results. Please be aware that each dataset has specific labeling guidelines for its labels. As you complete the procedures, keep considering the data as a dynamic phenomenon.

Each image's objects of interest should be identified
Computer vision models are developed to discover which pixel patterns correspond to a particular object of interest. Because of this, we must label each time a particular object appears in our photographs if we want to train a model to recognize it.
We will be giving our model false negatives if we don't label the target in some photographs.
For instance, in a dataset of chess pieces, we must identify the appearance of each and every piece on the board; for instance, we would not name just some of the white pawns.
The entire object should be labeled
The whole boundary of an object of particular interest should be contained inside the bounding boxes.
When an object is only partially labeled, our model becomes confused about what a complete object is made up of.
Consider how each chess piece in the dataset is completely encased by a bounding box.
Identify occluded objects

Occlusion occurs when an object in a picture is partially hidden from view because something is obscuring it.
Even obscured things should be labeled if possible. Additionally, rather than creating a bounding box for just the section of the occluded object that is partially visible, it is generally best practice to identify the occluded component as if it was fully visible.
For instance, in the chess dataset, a piece will frequently block another's view. Regardless of whether the boxes overlap, both items need labels. Contrary to popular belief, boxes can overlap.
Put together tight bounding boxes

The things of interest should be enclosed in tightly bound boxes. (However, a box shouldn't be so small that it completely encloses an object).
To teach our model precisely which pixels make up the object of interest vs unimportant areas of a picture, precise bounding boxes are essential.
Make unique label names
It is preferable to choose the option of being more detailed when choosing a label name for a given object. Being more generic is always simpler to achieve than being more particular, which necessitates relabeling.

Consider making a dog detector as an illustration. Although a dog is an object of interest, it could be a good idea to separate labradors and poodles into their own category. Our labels might be merged to form the word "dog" while first building the model. However, we would have had to completely rename our dataset if we had begun with "dog" and then understood the value of having distinct breeds.
Keep your labeling instructions clear
We will inevitably need to expand our data set; this is a crucial component of model improvement. We make the most of our labeling time by using strategies like active learning.
In order to maintain and develop high-quality datasets, it is crucial for both our present selves and our coworkers to have clear, reproducible, and shareable labeling instructions.
Many of the strategies we've covered here should be used, such as labeling every object, making labels tight, and labeling everything. Always choose the option of greater specificity rather than less.
Challenges that teams face in the image labeling process
Choose between Human vs automated annotation
Depending on the technique, data annotation can be expensive.
Automated processes for annotation that promise a particular degree of precision can be quick and less expensive, but they run the danger of imprecise annotation because the accuracy level is unknown until it is explored.
On the contrary hand, human annotation can be slower and more expensive, but it is also more accurate.
To consistently ensure high-quality data
Any ML model performs best with high-quality training data, which is a challenge in and of itself. Only reliable and consistent data will allow an ML model to produce accurate predictions.
Due to cultural differences, beliefs, and even prejudices, subjective data, for instance, might be challenging to understand for data labels from different parts of the world, which can lead to inconsistent results for repeated tasks.
Selecting the appropriate annotation tool
The correct data annotation tools and skilled personnel are required to provide high-quality training datasets. Data labeling uses a variety of data formats, therefore it's crucial to be aware of the aspects to take into account while choosing the best annotation tool.
How Labellerr can help you?
Labellerr offers a smart feedback loop that automates the processes that help data science teams to simplify the manual mechanisms involved in the AI-ML product lifecycle.
We are highly skilled at providing training data for a variety of use cases with various domain authorities. By choosing us, you can reduce the dependency on industry experts as we provide advanced technology that helps to fasten processes with accurate results.
A variety of charts are available on Labellerr's platform for data analysis. The chart displays outliers if any labels are incorrect or to distinguish between advertisements.
We accurately extract the most relevant information possible from advertisements—more than 95% of the time—and present the data in an organized style. having the ability to validate organized data by looking over screens.
We offer the best plans with affordable pricing
The most important feature of any data training platform is its pricing. At labellerr, we offer different pricing models based on the different requirements of users. You can visit our platform to learn more about it.
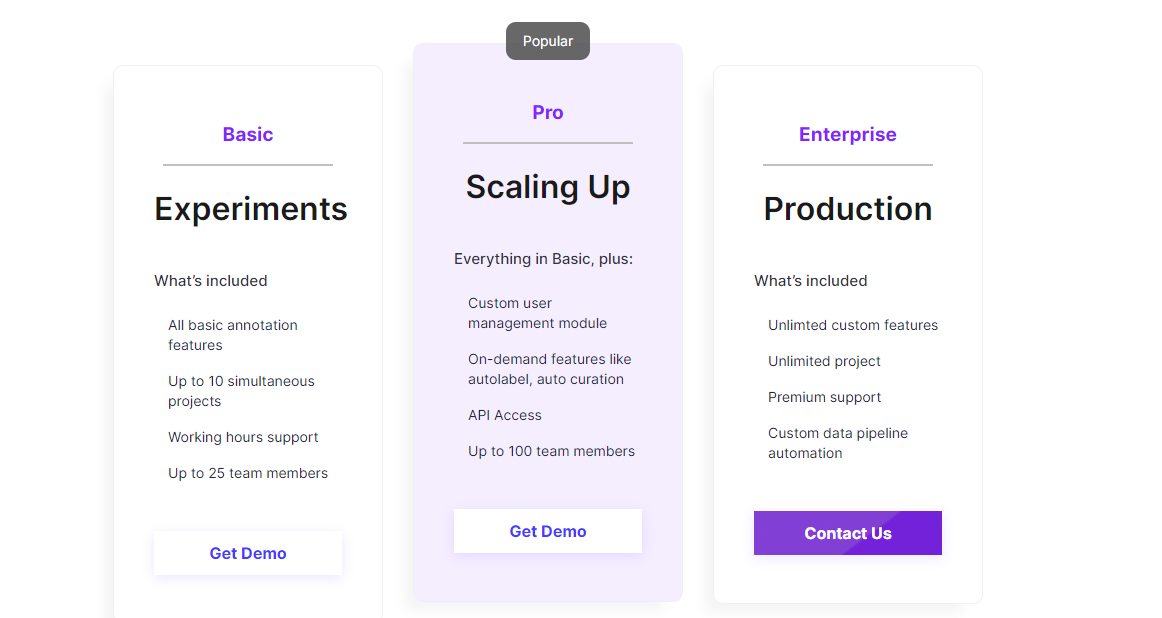
If you are looking for the best data training platform with perfect plan that suits your current need and provide flexibility while scaling up, then do check out our pricing page.

Simplify Your Data Annotation Workflow With Proven Strategies
Download the Free Guide