

Self-Supervised Object Detection from Egocentric Videos


Table of Contents
- Introduction
- Why Self-Supervised Learning?
- Key Concepts of DEVI Model
- Model Architecture
- Results and Evaluation
- Conclusion
- FAQs
Introduction
Our world is experienced primarily through our own eyes. This first-person perspective, known as egocentric vision, presents a unique challenge for computer vision systems.
Unlike traditional images or videos where the camera is static or has controlled movement, egocentric videos capture the world from a constantly moving viewpoint. This dynamic nature, combined with the inherent subjectivity of human perception, makes object detection a complex task.
Traditionally, object detection models rely on vast amounts of labeled data. However, annotating objects in egocentric videos is labor-intensive and time-consuming. This limitation has spurred the exploration of self-supervised learning approaches, which aim to learn from data without explicit human annotations.
Why Self-Supervised Learning?
Traditional supervised learning methods rely heavily on large volumes of labeled data to train object detection models. However, labeling data for egocentric videos is labor-intensive, time-consuming, and expensive.
The dynamic and unpredictable nature of first-person perspectives exacerbates the challenge, as it requires extensive annotations for diverse scenarios and contexts.
Self-supervised learning (SSL) offers a promising alternative by leveraging the vast amount of unlabeled data available in egocentric videos. SSL techniques enable models to learn useful representations from the data itself, without requiring explicit labels.
This approach not only reduces the dependency on labeled data but also improves the model's ability to generalize across different environments and conditions.
Key Concepts of DEVI Model

At the heart of self-supervised object detection from egocentric videos lies the idea of learning meaningful representations of objects directly from unlabeled video data.
Instead of relying on human-annotated labels, the model learns to identify patterns and relationships between visual elements within the video frames.
Motion: In egocentric videos, motion plays a crucial role in understanding the scene. Objects that move relative to the camera are often more salient and easier to identify. By analyzing motion patterns, the model can learn to distinguish between static background elements and dynamic objects of interest.
Appearance: The visual appearance of objects, including their shape, color, and texture, provides essential cues for object detection. The model learns to extract and recognize these features to differentiate between various objects.
Context: Contextual information, such as the spatial and temporal relationships between objects, helps the model understand the environment better. For instance, an object that consistently appears in a particular context (e.g., a coffee mug on a desk) can be more easily identified by the model.
Model Architecture
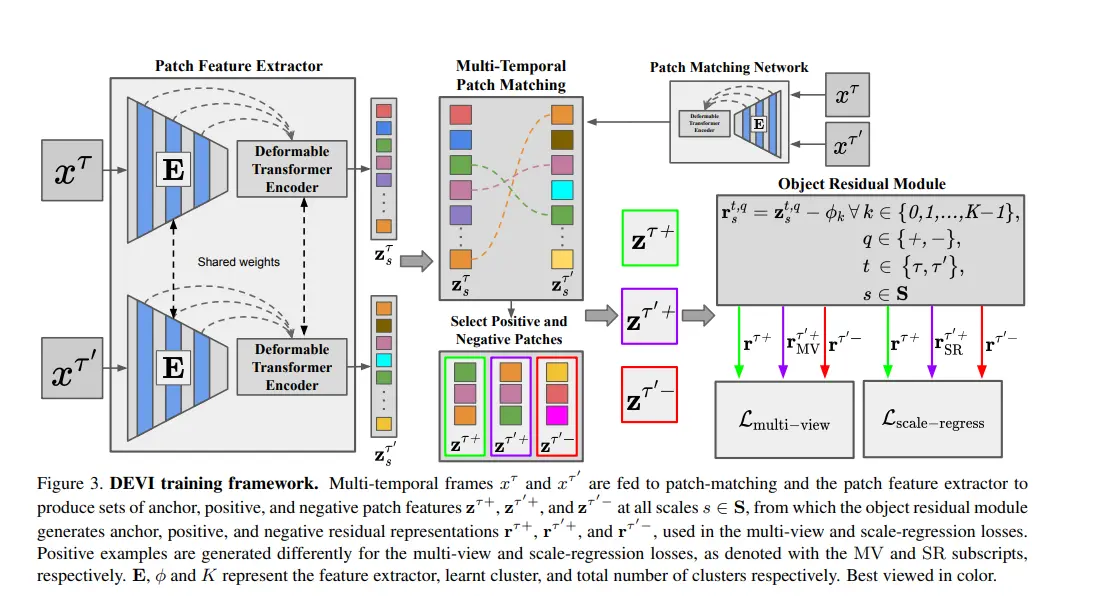
The proposed model architecture comprises several key components:
- Patch Feature Extractor: This module extracts features from image patches using a deformable transformer encoder. The shared weights across multiple frames enable the model to capture consistent object representations.
- Multi-Temporal Patch Matching: This component matches patches across different time steps to establish correspondences and identify potential object candidates.
- Object Residual Module: This module refines patch representations by learning residual information, enhancing the discriminative power of the features.
- Multi-view and Scale-Regression Losses: These loss functions guide the model's learning process by encouraging consistency in object representations across different views and scales.
Learning Process
The model learns to detect objects through a self-supervised learning paradigm. It is trained to predict the relationship between patches across different frames without explicit object labels. The model aims to maximize the agreement between the predicted and actual patch correspondences.
The loss function combines multi-view and scale-regression losses to optimize the model's parameters. The optimization technique typically involves gradient descent-based methods to minimize the loss and improve model performance.
By iteratively refining its predictions based on the loss signal, the model gradually learns to identify objects and their relationships within the video sequences.
Results and Evaluation
Metrics
To assess the performance of our self-supervised object detection model and compare it to existing methods, we employ standard object detection metrics:
- Average Precision (AP): This metric measures the average precision at different recall thresholds, providing a comprehensive evaluation of the model's accuracy.
- Average Recall (AR): AR evaluates the model's ability to detect objects at different recall levels, considering both true positives and false negatives.
These metrics are well-suited for object detection tasks as they capture the model's performance across various object categories and difficulty levels.
Performance Analysis
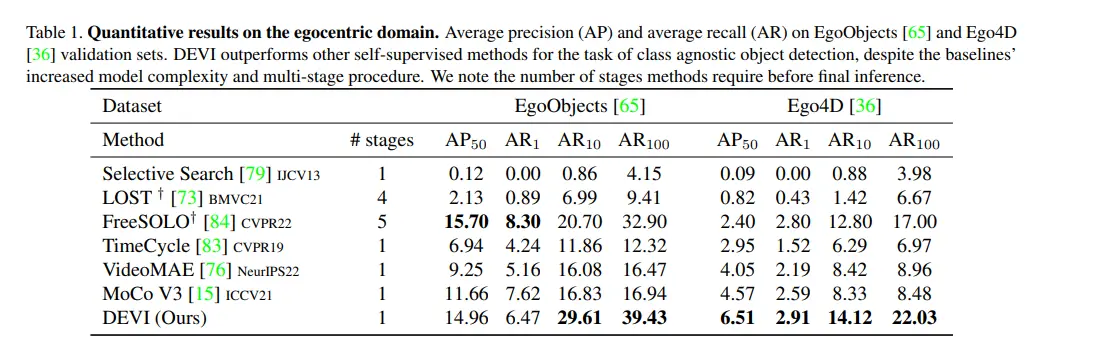
DEVI, compared to several state-of-the-art self-supervised object detection approaches on the EgoObjects and Ego4D datasets.
DEVI consistently outperforms other methods in terms of both AP and AR, demonstrating its superior ability to detect objects in egocentric videos. Notably, DEVI achieves this performance despite having a simpler architecture and requiring fewer training stages compared to some baselines.
Strengths of DEVI
- Strong performance: DEVI exhibits significantly higher AP and AR scores across different metrics, indicating its effectiveness in detecting objects in challenging egocentric video scenarios.
- Efficiency: The one-stage architecture and reduced training complexity make DEVI computationally efficient and practical for real-world applications.
- Generalizability: DEVI demonstrates robust performance on both EgoObjects and Ego4D datasets, suggesting its generalizability to different egocentric video scenarios.
Weaknesses
- Class agnostic: While DEVI excels at detecting objects without specific class labels, it may struggle to differentiate between objects of similar appearance.
- Small object detection: The model might exhibit limitations in detecting small objects due to the inherent challenges of egocentric video data.
DEVI presents a promising approach to self-supervised object detection in egocentric videos. Its strong performance, efficiency, and generalizability make it a valuable tool for various applications. However, further research is needed to address the challenges of class ambiguity and small object detection.
Conclusion
Self-supervised object detection from egocentric videos represents a significant advancement in the field of computer vision.
By leveraging the vast amounts of unlabeled data available in first-person perspective videos, this approach overcomes the limitations of traditional supervised learning methods, providing scalable, cost-efficient, and robust solutions for a wide range of applications.
In summary, self-supervised object detection from egocentric videos offers a promising and transformative approach to object detection.
As research continues to advance and overcome current challenges, this technology has the potential to unlock new possibilities and revolutionize various fields, ultimately improving the way we interact with and understand the world around us.
Object detection in video poses unique challenges due to constant camera motion and diverse environments. Traditional supervised methods require extensive labeled data, which is costly and time-consuming. Self-supervised learning offers a breakthrough by enabling models to learn directly from unlabeled video sequences, capturing motion and contextual cues to detect objects effectively.
The DEVI model exemplifies this approach by leveraging multi-frame patch matching and transformer-based feature extraction to identify objects without explicit annotations. This method not only reduces dependency on manual labeling but also improves generalization across varied video conditions, making it highly suitable for real-world applications like wearable cameras, robotics, and augmented reality.
Integrating advanced data annotation solutions can further enhance these models by providing high-quality labeled samples for fine-tuning and validation, ensuring better detection performance. As the field evolves, combining self-supervised learning with precise annotation tools will drive the future of scalable and accurate object detection in video.
Boost Your Object Detection Models with Labellerr
Labellerr offers a powerful data annotation tool designed to create accurate training datasets for object detection in video. Enhance your model’s performance and speed up development with our scalable, easy-to-use platform. Contact us today for a free demo and consultation.
Frequently Asked Questions
1. What is egocentric vision?
Egocentric vision refers to a first-person perspective captured from the viewpoint of an individual using wearable cameras or head-mounted devices. This perspective provides an immersive view of the user's interactions with their environment.
2. What are the main challenges of object detection in egocentric videos?
The primary challenges include:
- Dynamic camera movement: Constant changes in viewpoint due to head and body movements.
- Occlusions and motion blur: Frequent occlusions and rapid movements can obscure objects.
- Environmental variability: Diverse lighting conditions, backgrounds, and scenes require robust model adaptability.
- Data annotation: Manually labeling egocentric video data is labor-intensive and costly.
3. How does self-supervised learning differ from supervised learning?
Supervised learning relies on labeled data to train models, whereas self-supervised learning utilizes intrinsic signals within the data itself to learn representations without explicit labels. This reduces dependency on annotated data and leverages the abundance of unlabeled data.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
