

RT-DETR: The Real-Time End-to-End Object Detector with Transformers


Table of Contents
- Introduction
- Traditional Object Detection Methods: Evolution and Impact
- Limitations of Previous Models
- RT-DETR:Real-Time End-to-End Object Detector with Transformers
- Architecture of RT-DETR
- Experimental Results
- Applications of RT-DETR
- Conclusion
- Frequently Asked Questions
Introduction
Object detection is a fundamental computer vision task that involves identifying and locating objects within an image or video. It plays a crucial role in various applications, enabling machines to "see" and understand the world around them. It not only classifies objects into predefined categories but also draws bounding boxes around them, indicating their positions.
Object detection plays a pivotal role across numerous fields, underpinning advancements in fields such as autonomous driving, surveillance, healthcare, and beyond.
By enabling machines to identify and locate multiple objects within images or videos, object detection forms the foundation for sophisticated applications like real-time threat detection, inventory management, and personalized healthcare diagnostics.
Its significance lies in its ability to provide actionable insights from visual data, facilitating smarter decision-making processes and enhancing efficiency in diverse industries.
Traditional Object Detection Methods: Evolution and Impact
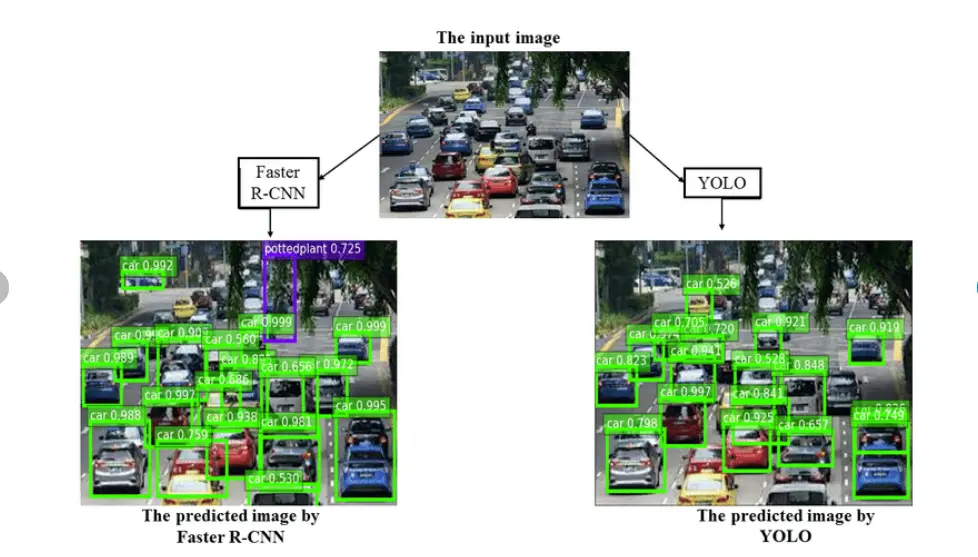
Traditional object detection methods have evolved significantly, integrating advancements like sliding window techniques and region proposal algorithms such as Selective Search.
These approaches laid the foundation for models like R-CNN (Regions with Convolutional Neural Networks), which used region proposals to identify potential objects and apply CNNs for classification, albeit with computational inefficiencies.
The evolution continued with Fast R-CNN, which optimized CNN computations across regions, and Faster R-CNN, which introduced the Region Proposal Network (RPN) for direct region generation within CNNs, boosting both speed and accuracy.
In contrast, YOLO (You Only Look Once) introduced a groundbreaking approach by treating object detection as a single regression problem, predicting bounding boxes and class probabilities directly from an image grid in real time. Subsequent iterations like YOLOv2, YOLOv3, and beyond have refined this approach, enhancing both speed and accuracy through improved network architectures and optimization techniques, solidifying YOLO's status as a leading object detection framework.
The impact of YOLO and its variants on real-time object detection has been profound. By achieving a balance between speed and accuracy, YOLO has enabled the deployment of object detection in numerous applications requiring immediate response and processing.
However, despite its success, there are still challenges, such as handling small objects, improving accuracy in complex scenes, and optimizing performance on resource-constrained devices.
To overcome these challenges, a new model Real-Time DEtection TRansformer (RT-DETR) has emerged, promising to push the boundaries of real-time object detection even further.
Limitations of Previous Models
Object detection has seen significant advancements with models like YOLO (You Only Look Once) and its subsequent versions, which have dominated the real-time detection space. However, these traditional models exhibit several limitations that necessitate the development of new approaches:
Accuracy vs. Speed Trade-off:
- YOLO models are designed to prioritize speed, making them suitable for real-time applications. However, this focus on speed often comes at the expense of accuracy. While YOLOv4 and YOLOv5 have improved accuracy over earlier versions, they still struggle to match the precision of slower, more complex models like Faster R-CNN.
- The accuracy of YOLO models can be insufficient for applications requiring high precision, particularly in scenarios with small objects, crowded scenes, or complex backgrounds.
Non-Maximum Suppression (NMS):
- YOLO models rely on Non-Maximum Suppression (NMS) to filter out redundant bounding boxes. This post-processing step introduces additional computational overhead and hyperparameters, which can affect both speed and accuracy.
- The requirement for careful tuning of NMS thresholds to balance recall and precision can be cumbersome and scenario-dependent, limiting the adaptability of YOLO models across diverse applications.
Complexity and Robustness:
- While YOLO models are relatively simple and efficient, they can lack robustness in handling variations in object scale, occlusions, and deformations. This can lead to missed detections or false positives in challenging conditions.
- Traditional convolutional neural network (CNN)-based architectures, like those used in YOLO, might struggle with capturing global context, which is crucial for accurate object localization and classification in complex scenes.
RT-DETR: The Real-Time End-to-End Object Detector with Transformers

RT-DETR, which stands for Real-Time Detection Transformer, is a groundbreaking object detection model introduced in the CVPR-2024 paper "DETRs Beat YOLOs on Real-time Object Detection". It holds significance for being, according to the paper, the first real-time and end-to-end object detector built upon the transformer architecture.
Here's a breakdown of what makes RT-DETR unique:
- Real-Time Performance: Unlike many Transformer-based models known for being computationally expensive, RT-DETR achieves real-time object detection speeds. This makes it suitable for applications where fast processing is crucial, like autonomous vehicles or video surveillance.
- End-to-End Design: RT-DETR eliminates the need for separate stages for object proposal and classification. This simplifies the overall pipeline and potentially improves efficiency.
- Transformer Architecture: At its core, RT-DETR utilizes the transformer architecture, known for its powerful ability to model long-range dependencies within data. This allows RT-DETR to effectively capture relationships between different parts of an image, leading to potentially more accurate object detection.
Backbone Network:
The paper mentions that RT-DETR can be implemented with various convolutional neural network (CNN) backbones as the foundation for feature extraction. Common choices include:
- ResNet-50: A widely used and well-performing CNN architecture.
- ResNet-101: A deeper variant of ResNet-50 offers potentially higher accuracy but with increased computational cost.
The specific backbone network chosen can impact the overall performance and speed of the RT-DETR model.
Architecture of RT-DETR
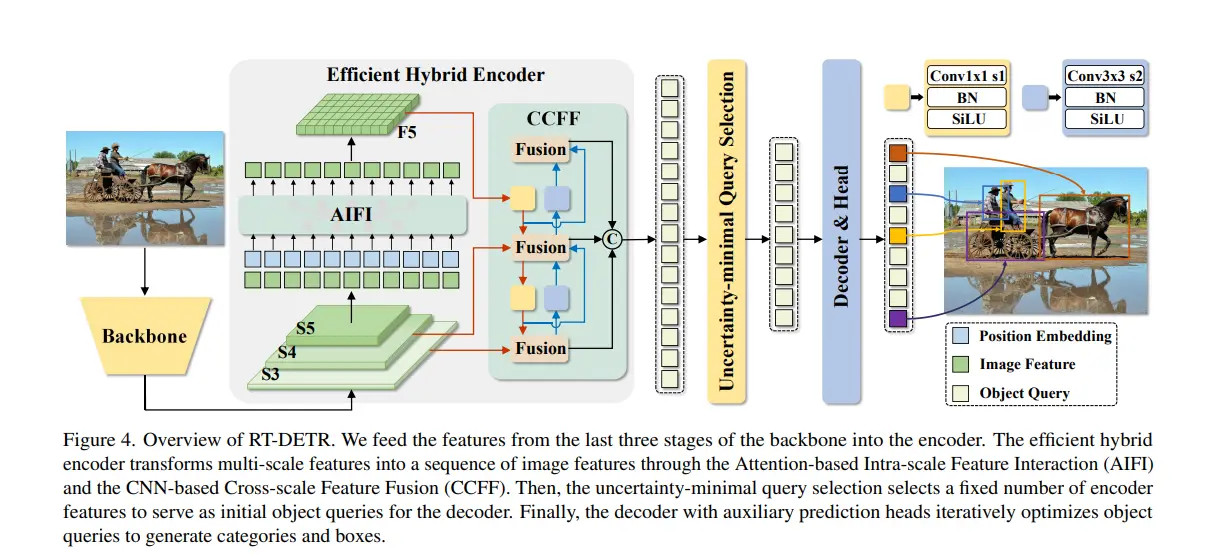
RT-DETR (Real-Time DEtection TRansformer) revolutionizes object detection by integrating transformer principles with innovative design elements tailored for real-time efficiency and accuracy.
Transformer Backbone: At its core, RT-DETR leverages Transformer architecture renowned for its ability to capture global context and long-range dependencies. Unlike traditional CNNs, Transformers process entire images simultaneously, enabling them to understand relationships across the entire scene.
This global context understanding is crucial for accurately detecting objects, especially in complex and cluttered environments where local information may be insufficient.
Efficient Hybrid Encoder: RT-DETR incorporates an Efficient Hybrid Encoder designed to optimize both intra-scale and cross-scale interactions. It consists of two main components:
- Attention-based Intra-scale Feature Interaction (AIFI): Focuses on detailed feature processing within each scale using self-attention mechanisms. This ensures comprehensive coverage of features at different levels without sacrificing contextual coherence.
- CNN-based Cross-scale Feature Fusion (CCFF): Integrates information across multiple scales to enhance the model's ability to detect objects of various sizes and resolutions. This fusion process ensures robustness and improves performance in detecting objects across diverse image contexts.
Uncertainty-minimal Query Selection: RT-DETR introduces a novel approach to selecting initial object queries by optimizing uncertainty minimization.
This method ensures that the decoder receives high-quality, confident queries, thereby enhancing detection performance and minimizing computational overhead.
Detection Head: The Detection Head decodes processed features to generate final object categories and bounding boxes. It integrates Transformer decoders with auxiliary prediction heads, leveraging iterative refinement to enhance detection accuracy progressively.
This approach balances speed and precision, making it suitable for real-time applications without compromising performance.
Feature Pyramid Networks (FPN): Integrated FPNs play a critical role in RT-DETR by enhancing multi-scale feature extraction:
- They enable the representation of features at various scales, crucial for detecting objects of different sizes.
- Using top-down pathways and lateral connections, FPNs merge high-level semantic information with detailed features, ensuring comprehensive coverage and robust detection across diverse scenes.
RT-DETR's architecture combines Transformer's global context understanding with efficient feature encoding, uncertainty-aware query selection, and advanced detection head mechanisms. These innovations collectively enable real-time, accurate object detection across complex and dynamic visual environments.
Experimental Results
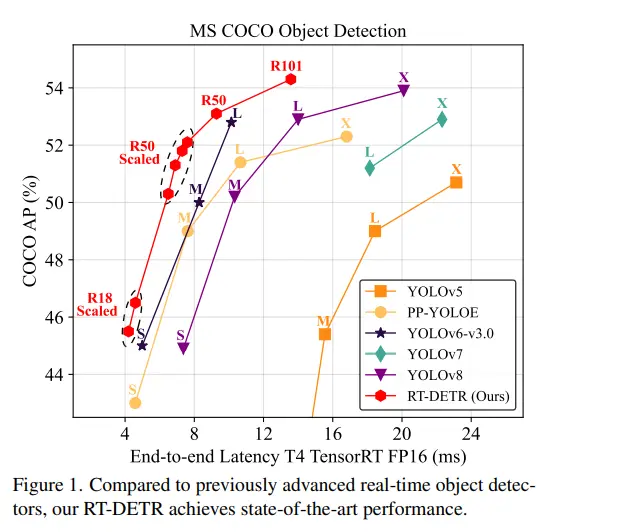
Benchmark Datasets
RT-DETR has been evaluated on several widely recognized benchmark datasets to demonstrate its effectiveness and robustness in real-time object detection tasks. The primary datasets used for evaluation include:
COCO (Common Objects in Context):
- The COCO dataset is a large-scale object detection, segmentation, and captioning dataset. It contains over 200,000 labeled images with more than 80 object categories. The diversity and complexity of COCO make it an excellent benchmark for evaluating the performance of object detection models.
- Evaluation Metrics: Mean Average Precision (mAP) at different Intersection over Union (IoU) thresholds are commonly used to assess the detection performance on the COCO dataset.
Comparison with YOLO
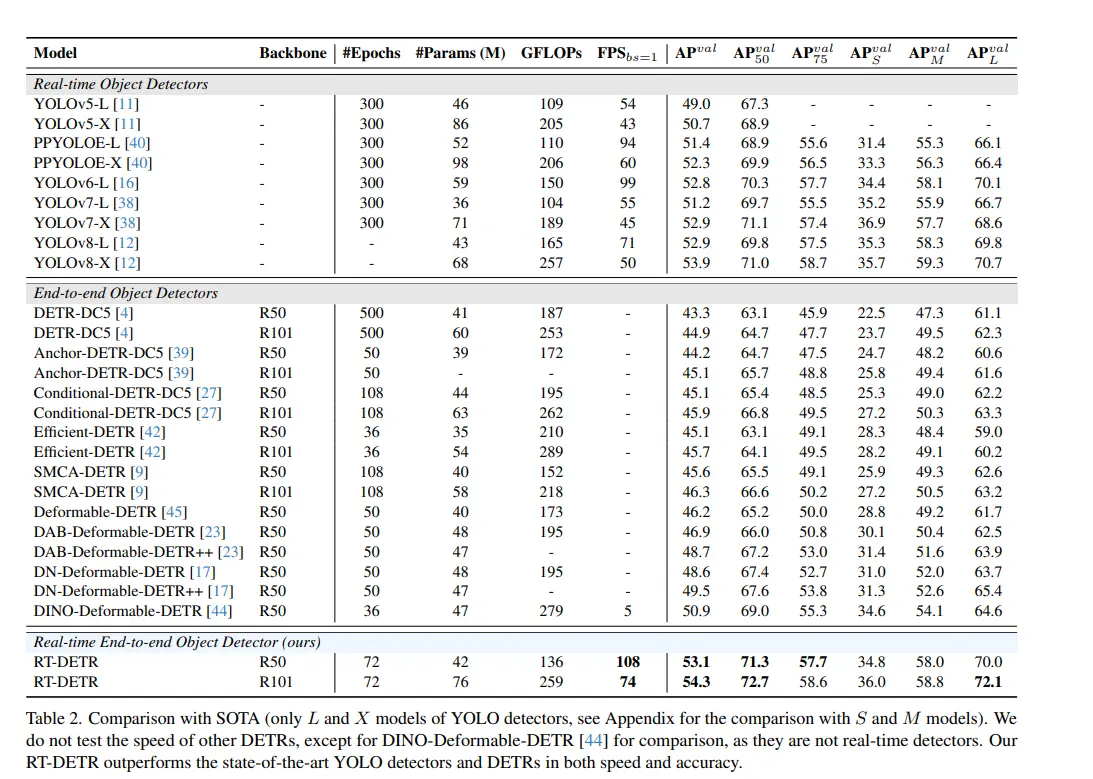
RT-DETR has been compared against state-of-the-art YOLO models, particularly the latest iterations such as YOLOv4 and YOLOv5, to highlight its performance in terms of accuracy, speed, and other relevant metrics. The comparison focuses on key aspects such as mAP, inference speed, and model size.
Accuracy:
- COCO Dataset: RT-DETR has shown significant improvements in accuracy over YOLO models on the COCO dataset. For instance, RT-DETR achieves a higher mAP and mAP compared to YOLOv4 and YOLOv5. This improvement is attributed to the efficient handling of multi-scale features and the robust query selection mechanism in RT-DETR.
- Pascal VOC: On the Pascal VOC dataset, RT-DETR also outperforms YOLO models in terms of mAP. The model's ability to capture global context and perform end-to-end detection contributes to its superior accuracy.
Speed:
- Inference Speed: Despite the improvements in accuracy, RT-DETR maintains competitive inference speeds. On standard GPU hardware, RT-DETR achieves real-time performance with inference speeds comparable to YOLOv4 and YOLOv5. The efficient hybrid encoder and parallel processing capabilities of Transformers play a crucial role in maintaining high speed.
- Latency: The end-to-end detection pipeline of RT-DETR reduces latency by eliminating the need for complex post-processing steps like Non-Maximum Suppression (NMS). This streamlined approach ensures fast and consistent inference times.
Applications of RT-DETR

RT-DETR's high accuracy and real-time performance make it suitable for a variety of real-world applications across multiple domains. Here are some notable use cases:
Autonomous Driving:
- Object Detection and Classification: RT-DETR can be used to detect and classify objects such as pedestrians, vehicles, traffic signs, and obstacles in real-time. This capability is crucial for making instantaneous decisions required for safe navigation.
- Lane Detection and Path Planning: In addition to detecting objects, RT-DETR can assist in lane detection and path planning, helping autonomous vehicles stay within lanes and navigate complex traffic scenarios.
Surveillance:
- Security Monitoring: RT-DETR can enhance security systems by accurately detecting and tracking intruders, abandoned objects, or suspicious activities in real-time. This is particularly useful in critical infrastructure, public spaces, and private properties.
- Crowd Management: In public events or crowded places, RT-DETR can monitor crowd density, detect unusual activities, and assist in maintaining safety protocols.
Robotics:
- Industrial Automation: In manufacturing and warehouse environments, RT-DETR can enable robots to identify and manipulate objects, perform quality control, and manage inventory. Its real-time capabilities ensure efficient and accurate operations.
- Service Robots: Service robots in hospitality, healthcare, and retail can use RT-DETR for navigation, object retrieval, and interaction with humans. For example, a healthcare robot can assist in patient care by identifying medical supplies or monitoring patient movements.
Smart Cities:
- Traffic Management: RT-DETR can be deployed in smart city infrastructure to monitor traffic flow, detect accidents, and manage traffic signals dynamically. This can help reduce congestion and improve urban mobility.
- Environmental Monitoring: The model can be used to detect environmental hazards, such as wildfires or flooding, by analyzing real-time video feeds from surveillance cameras or drones.
Conclusion
The Real-Time DEtection TRansformer (RT-DETR) represents a significant advancement in the field of object detection, bridging the gap between high accuracy and real-time performance.
By leveraging a Transformer-based architecture, efficient hybrid encoders, and innovative query selection mechanisms, RT-DETR addresses many of the limitations faced by traditional models like YOLO.
In conclusion, RT-DETR offers a compelling solution for real-time object detection, combining cutting-edge technology with practical advantages. Its ability to deliver high accuracy and speed in real-time applications positions it as a transformative tool in various industries, paving the way for smarter and more responsive systems.
As object detection continues to evolve, RT-DETR sets a new standard, promising exciting possibilities for future advancements and applications.
Frequently Asked Questions
1. What is RT-DETR?
RT-DETR stands for Real-Time Detection Transformer. It is an advanced object detection model that uses a Transformer-based architecture to achieve high accuracy and real-time performance. RT-DETR addresses the limitations of traditional models like YOLO by efficiently handling multi-scale features and providing robust detection capabilities.
2. How does RT-DETR differ from traditional object detection models like YOLO?
RT-DETR differs from traditional models like YOLO in several ways:
- Architecture: RT-DETR uses a Transformer-based architecture, which enables it to capture global context and perform end-to-end detection.
- Feature Extraction: It employs an efficient hybrid encoder that combines Attention-based Intra-scale Feature Interaction (AIFI) and CNN-based Cross-scale Feature Fusion (CCFF).
- Query Selection: RT-DETR uses uncertainty-minimal query selection to optimize the detection process.
- Real-time Performance: Despite its complex architecture, RT-DETR achieves real-time inference speeds comparable to YOLO.
3. How does RT-DETR perform compared to YOLO?
RT-DETR outperforms YOLO models in several key aspects:
- Accuracy: Higher mean Average Precision (mAP) on benchmark datasets like COCO and Pascal VOC.
- Speed: Comparable real-time inference speeds due to its efficient processing and end-to-end detection pipeline.
- Robustness: Better performance in handling small objects, occlusions, and cluttered backgrounds.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
