

WebVoyager: Autonomously Data Extraction With Multimodal Web Agents
WebVoyager, an AI web agent, autonomously interacts with websites using multimodal models like GPT-4. It handles complex tasks, blending text, image, and context data for applications in e-commerce, customer support, and more, redefining online interactions.


Table of Contents
- Introduction
- Fundamentals of Web Agents and Multimodal AI Models
- Working of WebVoyager Web Agent
- Implementation Details of WebVoyager Web Agent
- Evaluation and Error Analysis
- Difference Between Web Agents and Traditional Web Scraping Tools
- Applications of Web Agents like WebVoyager in Real Industry
- Conclusion
- FAQ
Introduction
In today's digital landscape, end-to-end web agents represent a transformative leap in artificial intelligence, designed to autonomously interact with and navigate real-world websites.
These agents, such as WebVoyager discussed in recent research (reference paper), integrate advanced multimodal models to process and respond to user queries across various input types, including text, images, and more.
Unlike traditional web agents limited to single modality inputs or static web simulations, these advanced agents leverage large multimodal models (LMMs) like GPT-4 to handle complex tasks directly on live websites.
The primary purpose of end-to-end web agents is to enhance user interaction by providing comprehensive and context-aware responses, thereby improving efficiency and user satisfaction in diverse applications.
By employing LMMs, these agents not only understand and generate text but also interpret and manipulate multimodal inputs seamlessly. This capability not only broadens the scope of tasks these agents can perform but also sets new benchmarks for performance and reliability in real-world scenarios.
As demonstrated by WebVoyager's impressive task success rate and innovative evaluation metrics, these agents present a new era of AI-driven web interactions capable of meeting the demands of dynamic and complex online environments.
Fundamentals of Web Agents and Multimodal AI Models
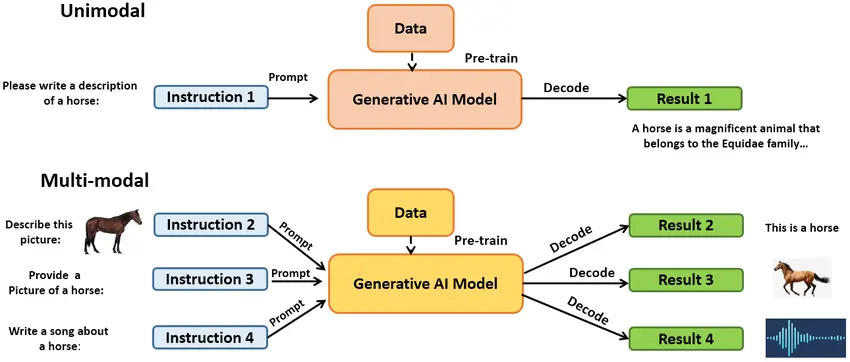
Definition and Importance
Web agents, also known as intelligent agents or chatbots, are AI-driven entities designed to interact autonomously with users through web interfaces.
They play a crucial role in automating various tasks such as customer support, information retrieval, and transaction processing, thereby enhancing user experience and operational efficiency in web-based applications.
The advent of large multimodal models (LMMs) represents a significant advancement in the capabilities of web agents. Unlike traditional models limited to handling single types of input, LMMs can process and integrate diverse data modalities such as text, images, videos, and even audio.
This integration enables web agents to understand and generate responses that are not only contextually rich but also perceptually relevant, mimicking more human-like interactions.
Types of Modalities
Multimodal AI models leverage multiple data modalities to enrich their understanding and responsiveness. These modalities include:
Text: The foundational modality for most AI models, text data forms the basis for understanding user queries and generating textual responses. Techniques such as natural language processing (NLP) are used to parse and interpret textual inputs.
Images: Visual data from images provides additional context and information. Convolutional Neural Networks (CNNs) are commonly used to extract features from images, allowing agents to recognize objects, scenes, and patterns.
Videos: Video data extends the temporal dimension, enabling agents to comprehend actions, gestures, and sequential events. Models may employ recurrent neural networks (RNNs) to process video inputs.
Audio: Sound data, including speech, adds another layer of interaction. Speech recognition models convert audio signals into text, while audio processing techniques such as spectrograms aid in understanding content.
The integration of these modalities allows web agents to handle complex queries that involve multiple forms of information. For instance, an agent could assist a user in finding a product by analyzing both textual descriptions and images, or provide instructions based on a combination of text and video tutorials.
Key Technologies
Several key technologies enable the effective processing and integration of multimodal data within AI models:
Transformers: Transformers, particularly models like BERT (Bidirectional Encoder Representations from Transformers), facilitate deep contextual understanding of textual inputs. They excel in tasks requiring long-range dependencies and semantic coherence, crucial for interpreting complex user queries.
Convolutional Neural Networks (CNNs): CNNs are pivotal in processing visual data such as images and videos. They excel at feature extraction through hierarchical layers of convolutions, enabling agents to recognize visual patterns and contexts.
Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM): These models are adept at handling sequential data, including text and temporal aspects of video or audio. They maintain state information over time, making them suitable for tasks involving contextually rich dialogues or video analysis.
Attention Mechanisms: Found in transformer architectures, attention mechanisms allow models to focus on relevant parts of input sequences, enhancing both understanding and generation capabilities across modalities.
Pretrained Models: Leveraging pre-trained models such as those from the GPT (Generative Pretrained Transformer) series or vision models like ResNet or EfficientNet significantly accelerates development by providing robust representations of multimodal data.
Working of WebVoyager Web Agent
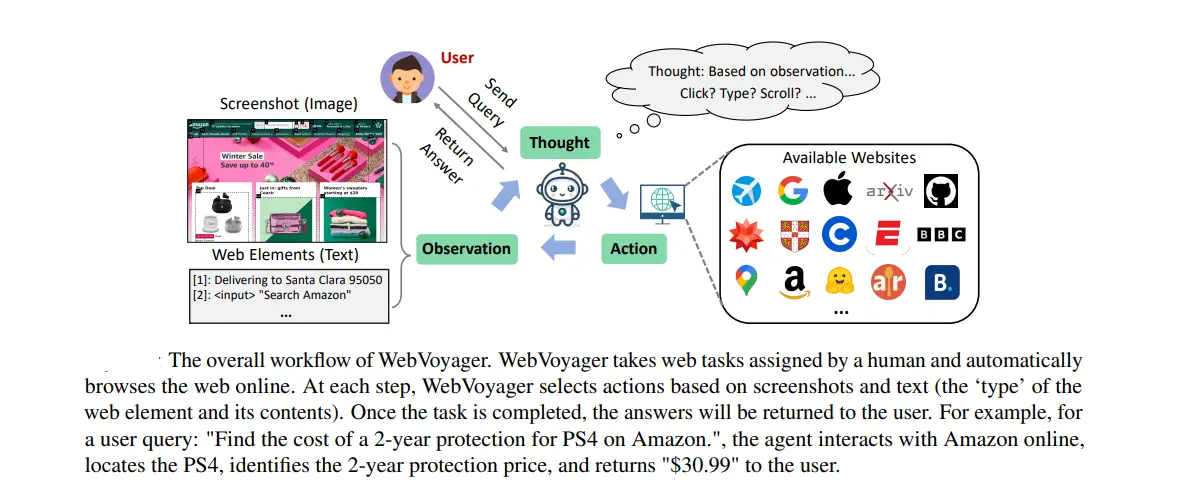
WebVoyager is designed to autonomously browse the open web, completing user instructions without human intervention. The system leverages visual (screenshots) and textual (HTML elements) signals to perform actions iteratively until the task is completed. Below, we detail the architecture and workflow of WebVoyager.
1. Browsing Environment
WebVoyager operates in an automated web-browsing environment developed using Selenium. Unlike other environments that host websites locally, WebVoyager interacts with real, online websites.
This approach poses challenges such as dealing with floating ads, pop-up windows, and frequent updates. However, it ensures the agent can access real-time information and adapt to dynamic web environments, reflecting true real-world use cases.
2. Interaction Cycle
The interaction cycle involves several key steps:
- Instantiation: The agent instantiates a web browser to begin interaction.
- Action Execution: At each step, the agent selects and executes actions based on the current visual and textual inputs.
- Iteration: The process continues iteratively, with the agent refining its actions based on feedback from the environment, until it completes the assigned task.
3. Observation Space
WebVoyager uses screenshots as its primary source of input, overlaying bounding boxes on interactive elements to guide action prediction. The system employs a tool called GPT-4V-ACT, which extracts interactive elements using JavaScript and overlays numerical labels on them. This approach avoids the need for complex HTML DOM processing and simplifies the decision-making process.
Key aspects of the observation space include:
- Screenshots: Visual representation of the web page.
- Bounding Boxes: Highlight interactive elements with numerical labels.
- Auxiliary Text: Includes text within interactive elements, element types, and any additional comment text from the aria-label attribute.
- Single Tab Operation: All interactions occur within the current tab to simplify observations.
4. Action Space
The action space is designed to mimic human web browsing behavior, including common mouse and keyboard actions. The agent uses numerical labels from screenshots to locate and interact with elements precisely. The actions include:
- Click: Click on a link or button.
- Input: Select a text box, clear existing content, and input new text.
- Scroll: Vertically scroll the webpage.
- Wait: Pause to allow web pages to load.
- Back: Navigate back to the previous page.
- Jump to Search Engine: Restart from a search engine if stuck.
- Answer: Conclude the iteration and provide an answer.
Workflow Example
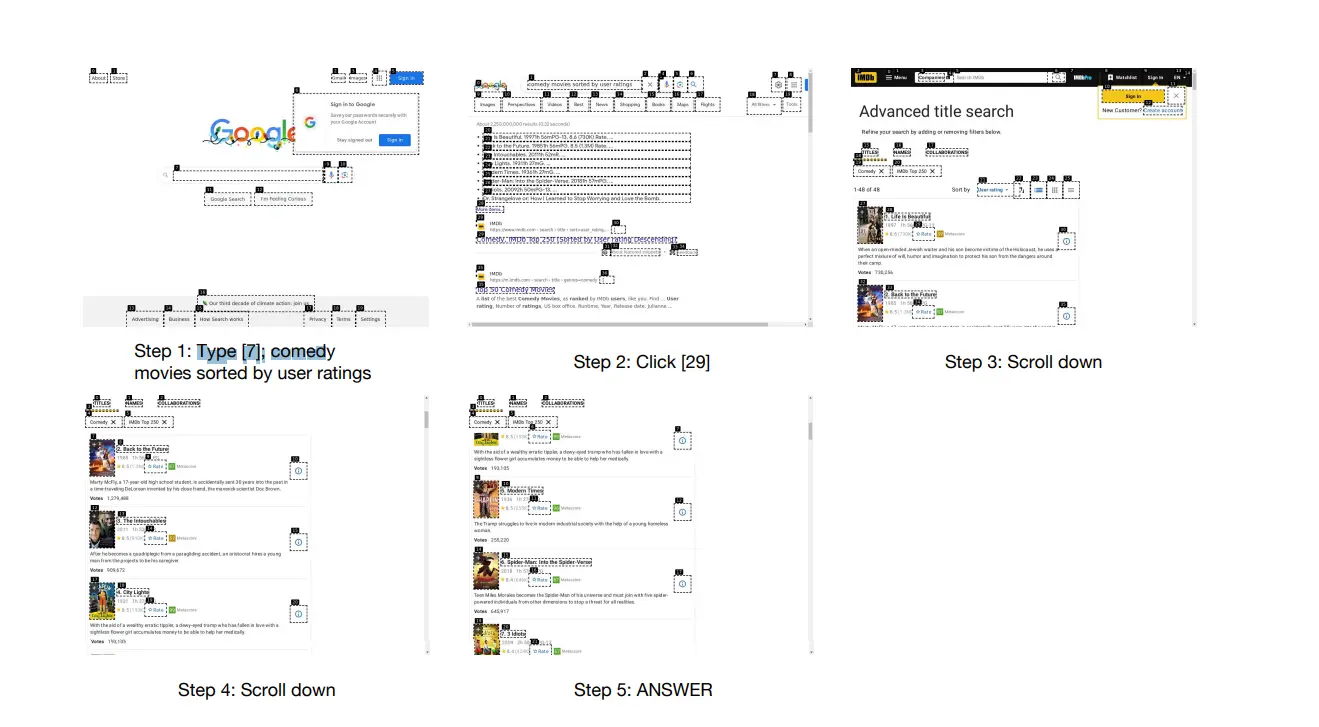
Task: “Show me a list of comedy movies, sorted by user ratings. Show me the Top 5 movies.”
Objective: The web agent interacts with the Google Search website and retrieves the top 5 comedy movies sorted by user ratings.
Workflow Steps
1. Task Assignment
- User Input: The user provides the task to WebVoyager: “Show me a list of comedy movies, sorted by user ratings. Show me the Top 5 movies.”
2. Input Processing
- Text Handling: The task description is tokenized and embedded. The agent understands the need to search for "comedy movies," "sorted by user ratings," and to retrieve the "Top 5 movies."
3. Action Selection
- Initial Query Generation: Based on the task, the agent formulates a search query: "Top comedy movies sorted by user ratings".
- Policy Learning: The agent decides to use Google Search to find the relevant information. It selects actions such as opening a web browser, navigating to the Google search page, and entering the query.
4. Execution
Web Interaction:
- Open a web browser and navigate to "https://www.google.com".
- Enter the search query “Top comedy movies sorted by user ratings” into the search bar.
- Submit the search query and wait for the results page to load.
5. Information Extraction
Extracting Relevant Data:
- Analyze the search results page to identify relevant sources that list comedy movies sorted by user ratings. This might include websites like IMDb, Rotten Tomatoes, or other reputable movie databases.
- Select a relevant source (e.g., IMDb's top-rated comedy movies page).
- Extract the top 5 comedy movies from the selected source, ensuring they are sorted by user ratings.
6. Response Generation
Natural Language Generation:
- Convert the extracted movie list into a user-friendly response.
- Formulate the response: “The Top 5 comedy movies sorted by user ratings are: Life Is Beautiful; Back to the Future; The Intouchables; City Lights; Modern Times.”
7. Task Completion
Final Response:
- Return the generated response to the user.
Implementation Details of WebVoyager Web Agent
Implementing a multimodal web agent involves meticulous dataset selection, annotation, preprocessing, and sophisticated model training strategies. Here’s a detailed exploration based on the approach outlined in the research paper:
Dataset Selection:
- Benchmark Dataset: The primary dataset includes tasks from 15 popular websites, providing a diverse range of real-world scenarios for the web agent to navigate and interact with.
- GAIA Dataset: Comprising 90 web browsing tasks categorized into Level 1 and Level 2, with predefined golden responses. This dataset serves as an additional benchmark for evaluating the agent's performance in dynamic web environments.
- SeeAct Agent’s Tasks: An evaluation dataset of 50 tasks used for comparative analysis with other state-of-the-art agents, focusing on task completion efficacy across different web interaction scenarios.
Annotation Process:
- Answer Categorization: Each task in the dataset is annotated with an answer categorized as either “Golden” or “Possible”:
- Golden Answers: Defined as stable responses considered correct in the short term. These are extensively listed to cover various expected responses for each task.
- Possible Answers: Used for open-ended tasks where exact matches are challenging (e.g., summarization tasks) or where multiple correct answers exist (e.g., real-time information tasks like flight prices).
Model Training
Backbone Models Used:
- GPT-4 Turbo with Vision: Selected as the primary backbone model due to its robust semantic and visual understanding capabilities, equivalent to GPT-4V. This model integrates both textual and visual inputs for enhanced comprehension and response generation.
- Claude 3 Opus and GPT-4o: Additional backbone models included to diversify research and evaluate performance across different multimodal architectures.
Baseline Models:
- GPT-4 (All Tools): A comprehensive model integrating vision, web browsing, code analysis, and plugins, serving as a benchmark for comparison.
- Text-Only Baseline: Simplified model variant receiving only website accessibility tree data as input, highlighting the impact of multimodal integration on performance metrics.
Training Process:
- Fine-Tuning: Pretrained models undergo fine-tuning on the aggregated dataset to adapt them specifically for web navigation and interaction tasks.
- Multi-Task Learning: Models are trained using multi-task learning strategies to handle diverse tasks efficiently, leveraging shared representations across different modalities to improve overall task success rates.
- Hyperparameter Optimization: Parameters such as learning rates, batch sizes, and exploration limits (e.g., maximum steps per task) are tuned to optimize model convergence and performance metrics.
- Evaluation Metrics: The primary evaluation metric, Task Success Rate, measures the agent’s ability to successfully complete tasks as defined by benchmark datasets and real-world interaction scenarios. This metric focuses on task completion efficacy rather than optimal pathfinding.
Experimental Details
- Environment Setup: The agent operates within a fixed browser window size of 1024 * 768 pixels, ensuring consistency in visual inputs (e.g., screenshots) across observations.
- Generation Settings: During response generation, a temperature setting of 1 balances exploration and exploitation, allowing for diverse and contextually appropriate responses within task constraints.
- Exploration Constraints: Agents are allowed a maximum of 15 steps per task to navigate and interact dynamically with web environments, maintaining efficiency and task-focused interaction capabilities.
Evaluation and Error Analysis
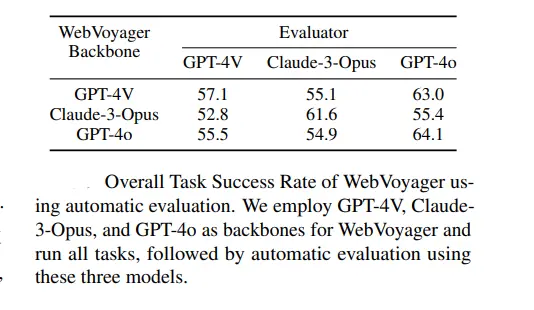
Evaluation of WebVoyager involves a comprehensive framework to assess its performance in navigating and interacting with real-world websites. This section explores the evaluation methods employed, the framework used, and a common errors encountered during the evaluation process.
Evaluation Framework
Human Evaluation:
- Methodology: Human evaluation serves as the primary metric due to the open-ended nature of many tasks. Human evaluators are provided with complete trajectories of WebVoyager’s interactions, including all screenshots and actions taken during the task execution.
- Scalability Concerns: While accurate, human evaluations are not scalable for large-scale assessments. Therefore, to explore automatic evaluation feasibility, GPT-4V, a large multimodal model, is leveraged as an auto-evaluator to emulate human evaluator's behavior.
GPT-4V as Auto-Evaluator:
- Approach: GPT-4V is tasked with evaluating navigation trajectories of WebVoyager by analyzing task prompts, agent responses, and the last k screenshots (a hyper-parameter determining context depth).
- Evaluation Prompt: The prompt provided to GPT-4V includes task details, agent responses, and visual context to judge task completion. This auto-evaluator aims to provide scalable and consistent evaluations akin to human judgment.
Error Types and Analysis
Common Errors:
Visual Grounding Issues:
- Description: Occurs when WebVoyager fails to accurately interpret visual elements such as buttons, forms, or text within screenshots, leading to incorrect actions or responses.
- Example: Misidentification of a "Buy Now" button on an e-commerce site due to visual similarity with other elements.
Navigation Getting Stuck:
- Description: Agent fails to progress through a task due to navigation barriers such as pop-up dialogs, broken links, or unexpected redirects.
- Example: Inability to proceed beyond a login prompt that requires human interaction or verification.
Hallucinations:
- Description: Agent generates responses based on incorrect or misleading interpretations of web content, leading to irrelevant or erroneous outputs.
- Example: Providing incorrect product specifications based on misinterpreted data from a dynamically updated webpage.
Prompt Misalignment:
- Description: Discrepancies between user queries or task instructions and the agent’s interpretation, resulting in mismatched actions or responses.
- Example: Misinterpreting a query for current flight prices as historical prices, leading to outdated information retrieval.
Difference Between Web Agents and Traditional Web Scraping Tools
Traditional Web Scrapers (e.g., Puppeteer, Selenium):
Scripted Behavior: These tools automate web interactions based on pre-defined scripts. They execute tasks like clicking buttons, filling forms, and extracting data from HTML elements.
No Understanding of Context: They operate purely based on the scripts provided without understanding the context or the content they are dealing with.
Limited to Pre-Defined Tasks: They are not flexible and can’t handle variations or unexpected changes in the web page structure.
Web Agents:
Intelligent Interaction: Uses machine learning models to understand the content and context, allowing it to interact more intelligently with web pages.
Adaptive: Can adapt to different websites and tasks dynamically, even if the web structure changes.
Contextual Understanding: Maintains the context over multiple interactions, enabling it to handle complex, multi-turn tasks.
Multimodal Input Handling: Can process and integrate text and visual inputs, making it capable of tasks that require understanding images and text together.
Advantages of Web Agents:
Flexibility and Adaptability: Can adapt to different tasks and websites without needing new scripts for each variation.
Contextual Awareness: Understands and maintains context across multiple interactions, allowing it to handle complex queries and tasks.
Multimodal Capabilities: Processes both text and images, providing a more comprehensive understanding of web pages.
Efficiency: Reduces the need for manual scripting and can handle unexpected changes in web page structure dynamically.
Applications of Web Agents like WebVoyager in Real Industry

1. E-commerce and Retail
Use Case: Product Information Retrieval and Comparison
Explanation: Web agents like WebVoyager can revolutionize the e-commerce and retail industry by automating the process of product information retrieval and comparison. Currently, users often spend significant time browsing multiple websites to find the best deals, compare product features, and check availability. A web agent can perform these tasks quickly and efficiently.
Price Comparison: The agent can browse multiple e-commerce sites, extract price information for a specific product, and present a comparative analysis to the user. For instance, it can compare the prices of a PS4 on Amazon, eBay, and Best Buy, including shipping costs and delivery times.
Product Reviews and Ratings: By aggregating reviews and ratings from different platforms, the agent can provide a comprehensive overview of a product’s performance and customer satisfaction. This helps users make informed purchasing decisions.
Availability Checks: The agent can monitor stock levels across various retailers and notify users when a product becomes available or goes on sale, ensuring they don’t miss out on limited-time offers.
Industry Impact: This automation can significantly reduce the time and effort required for users to make purchasing decisions, leading to increased customer satisfaction and higher conversion rates for retailers.
2. Customer Support and Service
Use Case: Automated Customer Service Agents
Explanation: In customer support, web agents can be deployed to handle a wide range of tasks, from answering frequently asked questions to resolving complex issues by navigating support websites and knowledge bases.
FAQ Handling: The agent can autonomously browse a company’s FAQ section and provide users with accurate answers to common queries, reducing the load on human support staff.
Issue Resolution: For more complex issues, the agent can navigate support portals, submit tickets, track the status of service requests, and guide users through troubleshooting steps based on the latest information from support databases.
Live Chat Support: By integrating with live chat systems, the agent can provide real-time assistance, understand user queries through natural language processing, and provide instant solutions by accessing relevant online resources.
Industry Impact: Automating these tasks can significantly improve response times, reduce operational costs, and enhance the overall customer experience by providing consistent and accurate support around the clock.
3. Market Research and Competitive Analysis
Use Case: Automated Data Collection and Analysis
Explanation: Web agents can be used extensively for market research and competitive analysis by automating the process of data collection and analysis from various online sources.
Competitor Monitoring: The agent can track competitors’ websites to gather data on new product launches, pricing strategies, promotional activities, and customer feedback. This information can be used to adjust marketing strategies and stay competitive.
Trend Analysis: By scanning industry blogs, news sites, and social media platforms, the agent can identify emerging trends, consumer preferences, and market shifts. This helps companies stay ahead of the curve by adapting their offerings to meet evolving demands.
Sentiment Analysis: The agent can analyze customer reviews, social media comments, and forum discussions to gauge public sentiment about a company’s products or services. This information is invaluable for reputation management and product improvement.
Industry Impact: Automated market research saves time and resources while providing businesses with up-to-date and comprehensive insights, enabling more informed decision-making and strategic planning.
4. Healthcare and Medical Research
Use Case: Automated Information Retrieval and Patient Support.
Explanation: In the healthcare sector, web agents can assist both professionals and patients by automating the retrieval of medical information and providing support services.
Medical Literature Search: The agent can search through medical databases, journals, and publications to find relevant research papers, clinical trials, and treatment guidelines. This is particularly useful for healthcare professionals who need to stay informed about the latest advancements.
Patient Education: By navigating medical websites, forums, and patient education portals, the agent can provide patients with reliable information about conditions, treatments, and preventive measures. This helps patients understand their health better and make informed decisions.
Industry Impact: Automating these processes improves access to information, enhances patient education, and reduces the administrative burden on healthcare providers, ultimately leading to better patient outcomes and more efficient healthcare delivery.
Conclusion
In this article, we have explored the details involved in developing and implementing multimodal web agents, focusing on the example of WebVoyager.
These agents integrate text, images, and other data types to navigate and interact with real-world websites autonomously.
Looking forward, the impact of multimodal web agents promises to revolutionize various sectors and applications.
By enabling more intuitive and effective interactions with online platforms, these agents enhance user experiences, streamline e-commerce transactions, improve customer support systems, and facilitate data-intensive tasks like information retrieval and analysis.
The ability of these agents to understand and synthesize information from multiple modalities opens gates for personalized services, adaptive learning systems, and enhanced decision-making processes.
In conclusion, multimodal web agents represent an important advancement in AI-driven technologies, poised to redefine how we interact with and utilize information on the internet. As these capabilities evolve, so too will our ability to harness AI’s full potential in shaping a more interconnected and intelligent digital ecosystem.
FAQS
1) What are multimodal web agents?
Multimodal web agents are AI-driven systems designed to interact with and navigate through web environments using multiple types of data inputs, such as text, images, and other media. They integrate these modalities to perform tasks autonomously, enhancing user interactions and task completion efficiency.
2) What technologies are used to build multimodal web agents?
Technologies typically include large language models (like GPT-4), convolutional neural networks (CNNs) for image processing, transformers for natural language understanding, and reinforcement learning techniques for task optimization. These agents leverage these technologies to interpret and respond to complex user queries across diverse web platforms.
3) How do multimodal web agents handle different types of data?
Multimodal web agents employ sophisticated algorithms to process and integrate diverse data types. Textual data is analyzed using natural language processing (NLP) techniques, while images and videos are interpreted through computer vision algorithms. These agents learn to extract relevant information from each modality and synthesize responses accordingly.
References:
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models(Link)

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
