

AIDE (Automatic Data Engine): Leveraging LLMs To Auto Label

Table of Contents
Introduction
The field of autonomous vehicles (AVs) is rapidly evolving, with the promise of revolutionizing transportation by enhancing safety, efficiency, and convenience. Central to the successful deployment of AVs is the development of robust perception models that can accurately identify and understand the environment around the vehicle.
These perception models are critical for safety assurance, as they enable the AV to detect and respond to various objects on the road, from pedestrians and cyclists to other vehicles and obstacles.
One of the significant challenges in developing these perception models is the long-tailed distribution of objects encountered in real-world driving scenarios. The term "long-tailed distribution" refers to the vast array of object categories that AVs must recognize, many of which are infrequently encountered. For example, while cars, trucks, and pedestrians are common, objects like construction equipment, animals, or unique road signs might appear rarely but are equally crucial for safe navigation.
The long-tailed nature of object categories in AV datasets leads to two primary issues:
- Data Imbalance: Common objects have abundant data for training, while rare objects have limited data, resulting in imbalanced training datasets. This imbalance can cause perception models to perform poorly on rare but critical objects.
- Annotation Bottleneck: Annotating data for these rare objects is both time-consuming and expensive. Human annotators must manually label large datasets to ensure that the models can recognize all potential objects, a process that is neither scalable nor sustainable as AV technology expands.
Introduction To AIDE
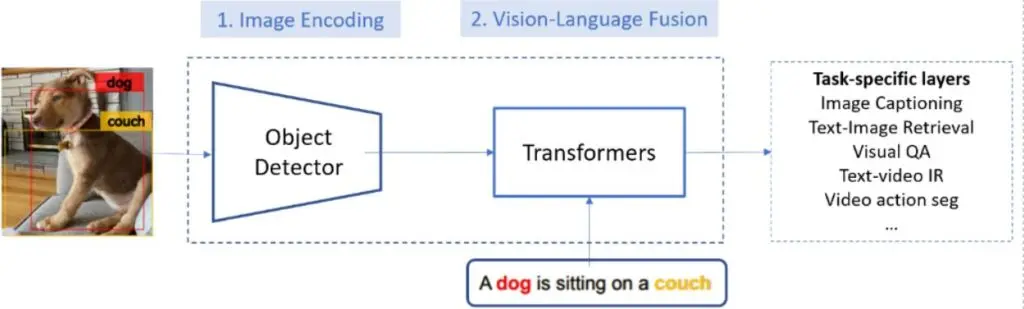
To address these challenges, new research introduces an innovative solution leveraging the latest advancements in vision-language models (VLMs) and large language models (LLMs). The goal is to develop an Automatic Data Engine (AIDE) that significantly improves the object detection capabilities of AV systems.
AIDE aims to automate the data curation and annotation process, thus enhancing the efficiency and scalability of developing perception models. The key objectives of the AIDE system are:
- Identify Missing Categories: Using dense captioning models, AIDE can identify objects and categories that are missing from the current label space of the perception model. This process helps in recognizing the long-tail objects that are not adequately represented in the training data.
- Efficient Data Retrieval: By utilizing vision-language models, AIDE can retrieve relevant data for these newly identified categories efficiently. This approach ensures that the model can learn from a more balanced and comprehensive dataset.
- Auto-Labeling and Model Updating: AIDE employs a two-stage pseudo-labeling process to automatically label the retrieved data, reducing the reliance on human annotators. The model is then updated with this newly labeled data, improving its ability to detect rare objects.
- Verification through Scenario Generation: Large language models are used to generate diverse and realistic driving scenarios to verify the model's performance. This step ensures that the updated perception model can accurately detect and respond to various real-world situations.
The Automatic Data Engine (AIDE) is an innovative system designed to address the challenges of data curation and annotation in autonomous vehicle (AV) perception models. AIDE leverages cutting-edge advancements in vision-language models (VLMs) and large language models (LLMs) to create a robust, scalable, and efficient process for improving object detection capabilities in AVs.
The AIDE system operates through an iterative process that encompasses several key steps:
- Identifying Issues: Recognizing gaps and missing categories in the existing label space to ensure comprehensive model coverage.
- Curating Data: Efficiently retrieving relevant data to fill these gaps using advanced AI models.
- Improving the Model: Automatically labeling the curated data and updating the perception model to enhance its detection capabilities.
- Verifying the Model: Generating diverse scenarios to test and validate the updated model's performance.
Components of AIDE
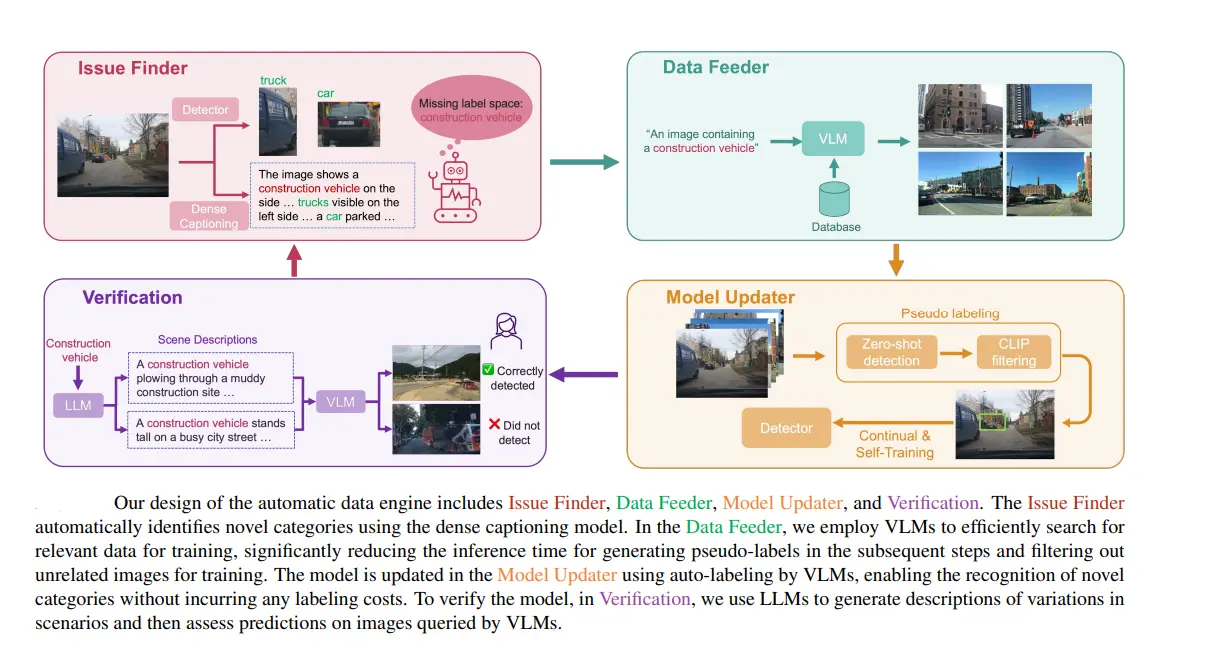
To achieve its goals, AIDE is composed of four main components, each playing a critical role in the system's overall functionality:
- Issue Finder
- Data Feeder
- Model Updater
- Verification
Each component performs a crucial role in the iterative process of identifying issues, curating data, improving the model through auto-labeling, and verifying the model through scenario generation.
1. Issue Finder

The Issue Finder component is the starting point of the AIDE system. It identifies gaps in the current label space by analyzing images and generating detailed descriptions using dense captioning models.
- Dense Captioning Models: These models analyze images to produce dense captions, which are comprehensive descriptions that include multiple objects and their relationships within the scene. For example, an image might be described with captions like "a red car parked next to a blue bicycle" or "a pedestrian crossing the street beside a dog."
- Identifying Novel Categories: By comparing the dense captions with the existing label space, the Issue Finder can identify objects and categories that are not yet represented in the training data. For instance, if the current model lacks the category "electric scooter," the Issue Finder will flag images containing electric scooters as having missing categories.
Example: Consider an AV dataset where the current model recognizes common objects like cars, trucks, and pedestrians. The Issue Finder processes an image and generates the caption "a person riding an electric scooter on the sidewalk." Since "electric scooter" is not in the existing label space, the Issue Finder identifies it as a novel category that needs to be included in the training data.
2. Data Feeder

Once novel categories are identified, the Data Feeder component steps in to curate relevant data for these categories using Vision-Language Models (VLMs).
- Vision-Language Models (VLMs): VLMs are used for text-guided image retrieval. These models leverage the relationship between textual descriptions and visual data to find images that match the identified novel categories. For example, if the Issue Finder identifies "electric scooter" as a novel category, the Data Feeder uses VLMs to retrieve images that contain electric scooters.
- Efficient Data Retrieval: This process ensures that a diverse set of images relevant to the new categories is quickly and efficiently gathered. The retrieved images provide the necessary data for training the perception model to recognize the newly identified objects.
Example: Following the identification of "electric scooter" as a novel category, the Data Feeder uses a text query like "images of electric scooters" to retrieve a variety of images from a large dataset. These images might include different types, angles, and contexts of electric scooters, providing a comprehensive dataset for model training.
3. Model Updater
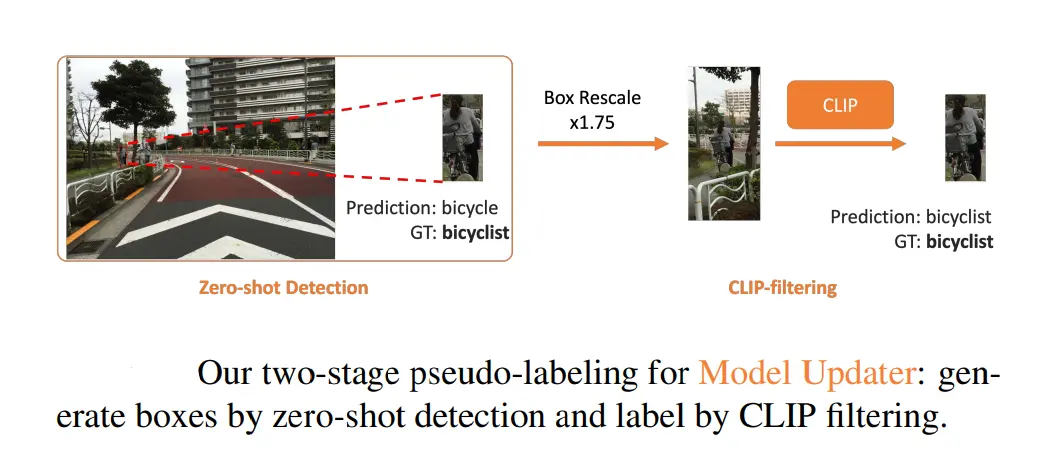
The Model Updater component is responsible for automatically labeling the curated data and updating the perception model. This process involves a two-stage pseudo-labeling technique.
This method includes two main stages:
- Box Generation: In the first stage, the model generates bounding boxes around objects in the retrieved images. These bounding boxes delineate the areas where the novel categories are located.
- Label Generation: In the second stage, the model assigns labels to the objects within the bounding boxes. This involves identifying the specific category of each object, such as the "electric scooter" in our example.
- Automatic Labeling: This automated process significantly reduces the need for human annotators, making the data curation process more efficient and scalable. The newly labeled data is then used to update the perception model, enhancing its ability to detect a broader range of objects.
Example: For the retrieved images of electric scooters, the Model Updater first generates bounding boxes around the scooters. Then, it assigns the label "electric scooter" to these boxes. This labeled data is added to the training set, and the perception model is retrained to recognize electric scooters accurately.
4. Verification

The final component of AIDE is Verification, which ensures the robustness and reliability of the updated perception model. This is achieved through scenario generation and model evaluation using Large Language Models (LLMs).
- Large Language Models (LLMs): LLMs are employed to generate diverse and realistic driving scenarios that test the model's performance. These scenarios cover a wide range of situations that the AV might encounter, including different environmental conditions, object interactions, and uncommon events.
- Scenario Generation and Testing: By creating various test scenarios, the Verification component rigorously evaluates the updated model's ability to detect and respond to different objects and conditions. This step is critical for ensuring that the model performs well in real-world environments and can handle the complexity and variability of autonomous driving.
Example: After updating the model to include electric scooters, the Verification component uses LLMs to generate scenarios such as "a rainy day with multiple electric scooters on the sidewalk" or "an electric scooter crossing a busy intersection." The updated model is then tested on these scenarios to ensure it can accurately detect and respond to electric scooters under various conditions.
The AIDE system's methodology involves a comprehensive and automated process of identifying issues, curating relevant data, updating the model, and verifying its performance. By utilizing advanced AI models such as dense captioning, VLMs, and LLMs, AIDE addresses the challenges of data curation and annotation in AV perception models. This innovative approach enhances the scalability, efficiency, and accuracy of developing AV systems, ultimately contributing to safer and more reliable autonomous driving technology.
Experimental Results
The experimental results of the AIDE (Automatic Data Engine) system demonstrate its effectiveness in enhancing the performance of autonomous vehicle (AV) perception models. The results are evaluated on a new benchmark for open-world detection in AV datasets, highlighting significant improvements in average precision (AP) and showcasing the advantages of AIDE over existing methods.
Benchmark and Evaluation
To thoroughly assess the performance of AIDE, the authors introduced a new benchmark specifically designed for open-world detection in AV datasets. This benchmark evaluates the system's ability to detect both known and novel categories in diverse and dynamic driving environments. The benchmark includes:
- Open-World Detection: Evaluating the model's capability to recognize objects that were not part of the initial training set, reflecting real-world scenarios where AVs encounter a wide variety of objects.
- Diverse Scenarios: Incorporating various driving conditions, such as different weather, lighting, and traffic situations, to test the robustness of the perception model.
- Comprehensive Metrics: Using metrics such as Average Precision (AP) to quantify the detection performance on both known and novel categories, providing a clear measure of improvement.
Performance Improvement
The experimental results reveal significant performance improvements achieved by the AIDE system, particularly in detecting novel categories without human annotations and enhancing the detection of known categories.
- Improvement on Novel Categories: AIDE achieved a 2.3% increase in Average Precision (AP) for novel categories. This improvement is noteworthy as it demonstrates the system's ability to automatically identify and label new object categories without the need for manual annotations, addressing the long-tailed distribution challenge.
- Improvement on Known Categories: For categories that were part of the initial training set, AIDE delivered an impressive 8.9% increase in AP. This enhancement indicates that the additional data and improved labeling processes not only benefit novel categories but also refine the detection accuracy for already known objects.
Example: In practical terms, this means that an AV perception model updated with AIDE is better equipped to accurately detect uncommon objects like electric scooters, as well as improve its precision in recognizing frequently encountered objects like cars and pedestrians.
Comparison with Existing Methods
The results of AIDE were compared with other prominent paradigms in the field, including OWL-v2, semi-supervised learning, and active learning. The comparison highlights the superior performance and efficiency of AIDE.
OWL-v2: This method is designed for open-world learning, where models are trained to identify novel categories during inference. While OWL-v2 is effective in recognizing new objects, it relies heavily on the model's ability to generalize from existing knowledge, which can be limited by the quality and diversity of the training data.
- Comparison: AIDE outperformed OWL-v2 by leveraging dense captioning and VLMs to actively identify and retrieve data for novel categories, resulting in higher AP improvements.
Semi-Supervised Learning: This approach uses a combination of labeled and unlabeled data to improve model performance. It reduces the need for extensive manual labeling but can struggle with the accuracy of pseudo-labels generated from unlabeled data.
- Comparison: AIDE's two-stage pseudo-labeling process provided more accurate and reliable labels for both known and novel categories, leading to better overall performance compared to traditional semi-supervised learning methods.
Active Learning: Active learning focuses on selectively annotating the most informative samples from a large dataset to maximize model performance with minimal annotation effort. However, it still requires human intervention to label the selected samples.
- Comparison: AIDE minimizes human effort by automating the data curation and annotation process, achieving superior AP improvements without the need for continuous human involvement in the labeling process.
Example: In the comparative analysis, AIDE demonstrated higher AP scores across various categories and scenarios, showcasing its ability to effectively bridge the gap between manual and automated data annotation techniques. This highlights AIDE's potential to set a new standard in open-world detection for AVs.
Conclusion
The development and implementation of the Automatic Data Engine (AIDE) represent a significant advancement in the field of autonomous vehicle (AV) perception models. By addressing the challenges of data curation, annotation, and model improvement through an innovative and automated approach, AIDE stands as a transformative solution for enhancing object detection capabilities in AV systems.
The successful implementation of AIDE not only addresses current challenges in AV perception but also sets the stage for future advancements. As AV systems continue to evolve, the need for robust, scalable, and cost-effective data solutions will remain critical. AIDE's approach ensures that perception models can continuously adapt to the dynamic and unpredictable nature of real-world driving environments, maintaining high standards of safety and reliability.
In conclusion, the AIDE system represents a paradigm shift in the development and maintenance of AV perception models. By automating the processes of data curation and annotation, AIDE provides a scalable solution that significantly enhances detection capabilities, promotes industry innovation, and contributes to the safer deployment of autonomous vehicles. The introduction of a new benchmark for open-world detection further underscores AIDE's potential to set new standards in the field, paving the way for more reliable and effective autonomous driving technology.
FAQs
1. What is AIDE?
AIDE, or Automatic Data Engine, is an innovative system designed to automate and optimize the process of data curation, annotation, and model improvement for autonomous vehicle (AV) perception models. It leverages advanced AI technologies, including dense captioning models, vision-language models (VLMs), and large language models (LLMs), to enhance object detection capabilities in AV systems.
2. Why is data curation and annotation important for AV perception models?
Data curation and annotation are critical for training AV perception models to accurately detect and recognize various objects in diverse driving environments. High-quality labeled data is essential for improving the model's ability to handle real-world scenarios, ensuring safety, and enhancing the overall performance of AV systems.
3. What challenges does AIDE address in the AV industry?
AIDE addresses several challenges, including:
- The high cost and labor-intensive nature of manual data curation and annotation.
- The need for continuous updates to perception models to recognize novel categories of objects encountered on the road.
- The scalability of data solutions to handle large volumes of data efficiently.
References:
AIDE: An Automatic Data Engine for Object Detection in Autonomous Driving

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
