

Complete Guide On Fine-Tuning LLMs using RLHF
Explore how LLM reinforcement learning with human feedback (RLHF) fine-tunes large language models, improving natural language responses and optimizing AI behavior through rewards, human input, and iterative learning for enhanced model performance.


AI models like ChatGPT have redefined how we interact with technology. ChatGPT currently has 180 million active users and 132 million website traffic.
In discussions about why ChatGPT has captured our fascination, two common themes emerge:
- Scale: Increasing data and computational resources.
- User Experience (UX): Transitioning from prompt-based interactions to more natural chat interfaces.
However, there's an aspect often overlooked – the remarkable technical innovation behind the success of models like ChatGPT.
One particularly ingenious concept is Reinforcement Learning from Human Feedback (RLHF), which combines reinforcement learning and human input in the field of Natural Language Processing (NLP).
Historically, reinforcement learning has been challenging to apply, primarily confined to gaming and simulated environments like Atari or MuJoCo.
Just a few years ago, RL and NLP advanced independently, using different tools, techniques, and setups. It's remarkable to see how effective RLHF has become in such a vast and evolving field.
So, how does RLHF function? Why is it effective?
This article will break down the mechanics behind RLHF to answer these questions. But first, it’s crucial to understand how models like ChatGPT are trained and where RLHF fits into this process—this will be our starting point.
Table of Contents
- Reinforcement Learning from Human Feedback Overview
- How Does RLHF Operate?
- Deconstructing the RLHF Training Process: Step-by-Step Analysis
- Developing a Reward Model Through Training
- Techniques to Fine-Tune Model with Reinforcement Learning with Human Feedback
- Challenges Associated with Reinforcement Learning with Human Feedback
- Conclusion
- Frequently Asked Questions
Reinforcement learning from human feedback Overview
Let’s break down the development process of ChatGPT to pinpoint where RLHF is applied. Think of the model as evolving from a raw, unrefined state, much like the meme of a Shoggoth with a smiley face.
Initially rough and chaotic, the model gradually becomes more aligned and user-friendly through fine-tuning and human feedback.
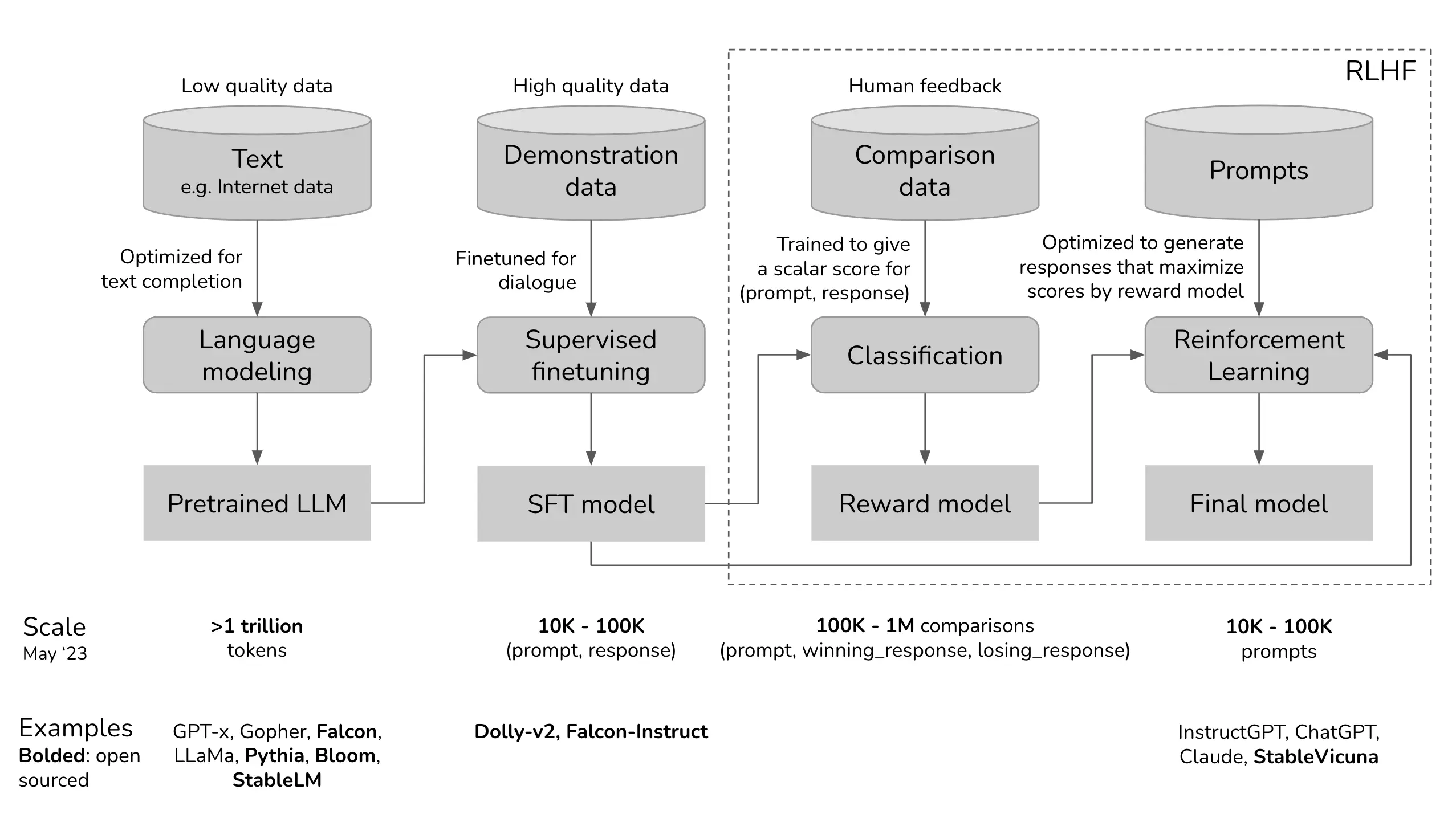
Figure: A schematic diagram of How LLM is brought to Production
The initial pre-trained model resembles an unrefined entity, having been trained on a vast array of internet data that includes clickbait, misinformation, propaganda, conspiracy theories, and inherent biases against certain groups.
This creature then underwent fine-tuning using higher-quality data sources like StackOverflow, Quora, and human annotations, making it more socially acceptable and improving its overall reliability.
Subsequently, the fine-tuned model was refined further through RLHF, transforming it into a version suitable for customer interactions – think giving it a smiley face – and eliminating the Shoggoth analogy.
How does RLHF operate?
The RLHF training process unfolds in three stages:
- Initial Phase: The outset involves designating an existing model as the primary model to establish a benchmark for accurate behavior.
Given the extensive data requirements for training, utilizing a pre-trained model proves efficient. - Human Feedback: Following the initial model training, human testers contribute their evaluations of its performance.
Human trainers assign quality or accuracy ratings to different outputs generated by the model. Based on this human feedback, the system generates rewards for reinforcement learning. - Reinforcement Learning: The reward model is fine-tuned using outputs from the primary model, and it receives quality scores from testers. The primary model uses this feedback to enhance its performance for subsequent tasks.
This process is iterative. Human feedback is collected repeatedly, and reinforcement learning refines the model continuously, improving its capabilities.
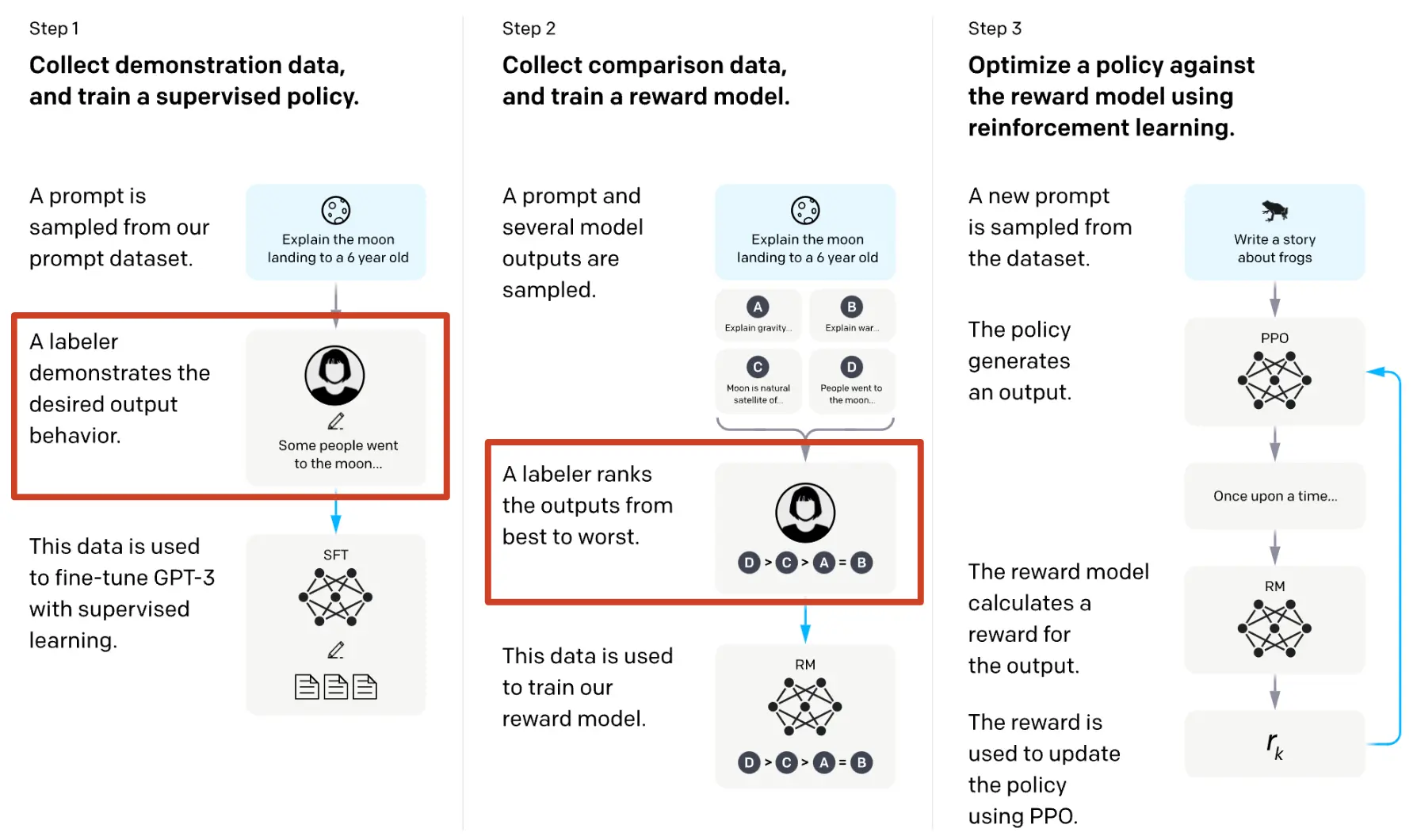
Figure: Working procedure in RLHF (With Reward Model)
Deconstructing the RLHF Training Process: Step-by-Step Analysis
As we learn more about the intricate workings of the Reinforcement Learning from Human Feedback (RLHF) algorithm, it's crucial to maintain an awareness of its connection with the fundamental component: the initial pretraining of a Language Model (LM).
Let's dissect each phase of the RLHF algorithm.
Pretraining a Language Model (LM)
The pretraining phase establishes the groundwork for RLHF. In this stage, a Language Model (LM) undergoes training using a substantial dataset of text material sourced from the internet.
Figure: Pretraining with large text corpus
This data enables the LM to comprehend diverse aspects of human language, encompassing syntax, semantics, and even context-specific intricacies.
Step 1: Choosing a Base Language Model
The initial phase involves the critical task of selecting a foundational language model.
The choice of model is not universally standardized; instead, it hinges on the specific task, available resources, and unique complexities of the problem at hand.
Industry approaches differ significantly, with OpenAI adopting a smaller iteration of GPT-3 called InstructGPT, while Anthropic and DeepMind explore models with parameter counts ranging from 10 million to 280 billion.
Step 2: Acquiring and Preprocessing Data
In the context of RLHF, the chosen language model undergoes preliminary training on an extensive dataset, typically comprising substantial volumes of text sourced from the internet.
This raw data requires cleaning and preprocessing to render it suitable for training. This preparation often entails eliminating undesired characters, rectifying errors, and normalizing text anomalies.
Step 3: Language Model Training
Following this, the LM undergoes training using the curated dataset, acquiring the ability to predict subsequent words in sentences based on preceding words.
This phase involves refining model parameters through techniques like Stochastic Gradient Descent.
The overarching objective is to minimize disparities between the model's predictions and actual data, typically quantified using a loss function such as cross-entropy.
Step 4: Model Assessment
The model's performance is assessed upon completing training using an isolated dataset that was not employed in the training process.
This step is crucial to verify the model's capacity for generalization and discover that it has yet to memorize the training data.
If the assessment metrics meet the required criteria, the model is deemed prepared for the subsequent phase of RLHF.
Step 5: Preparing for RLHF
Although the LM has amassed substantial knowledge about human language, it needs an understanding of human inclinations.
To address this, supplementary data is necessary. Often, organizations compensate individuals to produce responses to prompts, which subsequently contribute to training a reward model.
While this stage can incur expenses and consume time, it's pivotal for orienting the model towards human-like preferences.
Notably, the pretraining phase doesn't yield a perfect model; errors and erroneous outputs are expected. Nevertheless, it furnishes a significant foundation for RLHF to build upon, enhancing the model's accuracy, safety, and utility.
Developing a Reward Model through Training
At the core of the RLHF procedure lies establishing and training a reward model (RM). This model serves as a mechanism for alignment, providing a means to infuse human preferences into the AI's learning trajectory.
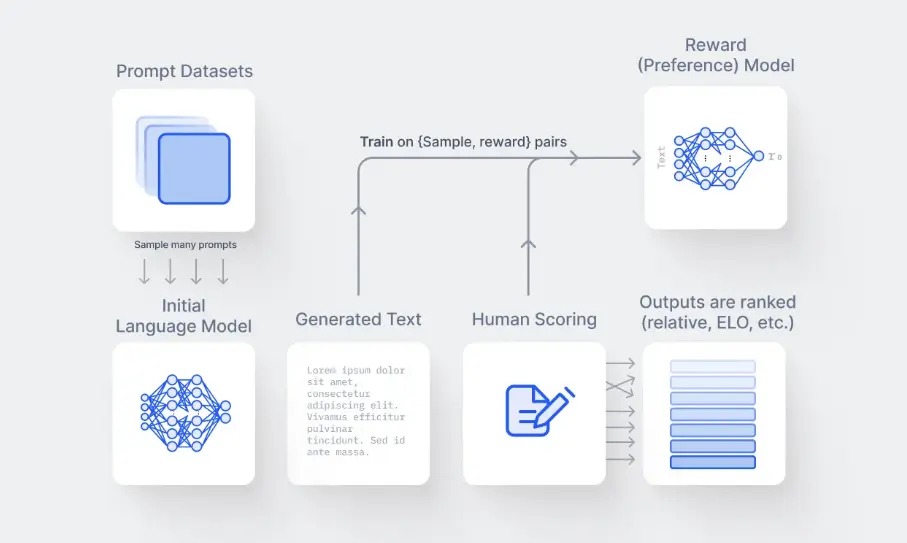
Figure: Creating a reward Model For RLHF
Step 1: Creating the Reward Model
The reward model can be either an integrated language or a modular structure.
Its fundamental role is associating input text sequences with a numerical reward value, progressively facilitating reinforcement learning algorithms to enhance their performance in various settings.
For instance, if an AI generates two distinct text outputs, the reward model will ascertain which one better corresponds to human preferences, essentially 'acknowledging' the more suitable outcome.
Step 2: Data Compilation
Initiating the training of the reward model involves assembling a distinct dataset separate from the one employed in the language model's initial training.
This dataset is specialized, concentrating on particular use cases, and composed of pairs consisting of prompts and corresponding rewards.
Each prompt is linked to an anticipated output, accompanied by rewards that signify desirability for that output.
While this dataset is generally smaller than the initial training dataset, it plays a crucial role in steering the model toward generating content that resonates with users.
Step 3: Model Learning
Using the prompt and reward pairs, the model learns to associate specific outputs with their corresponding reward values.
This process often harnesses expansive 'teacher' models or combinations to enhance diversity and counteract potential biases.
The primary objective here is to construct a reward model capable of effectively gauging the appeal of potential outputs.
Step 4: Incorporating Human Feedback
Integrating human feedback is an integral facet of refining the reward model. A prime illustration of this can be observed in ChatGPT, where users can rate the AI's outputs using a thumbs-up or thumbs-down mechanism.
This collective feedback holds immense value in enhancing the reward model, providing direct insights into human preferences.
Through this iterative cycle of model training and human feedback, AI undergoes continuous refinement, progressively aligning itself better with human preferences.
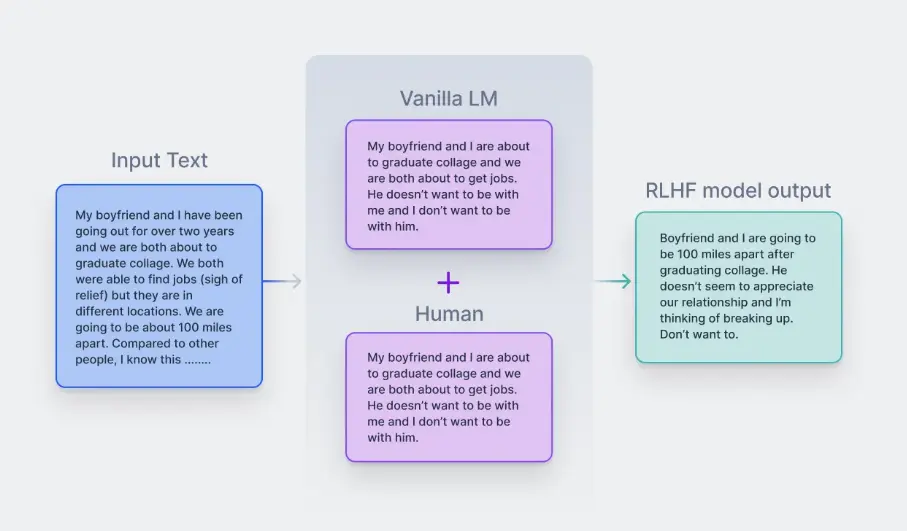
Figure: Incorporating Human Feedback in LLMs
Techniques to Fine-Tune Model with Reinforcement Learning with Human Feedback
Fine-tuning plays a vital role in Reinforcement Learning with the Human Feedback approach. It enables the language model to refine its responses according to user inputs.
This refinement process employs reinforcement learning methods, incorporating techniques like Kullback-Leibler (KL) divergence and Proximal Policy Optimization (PPO).
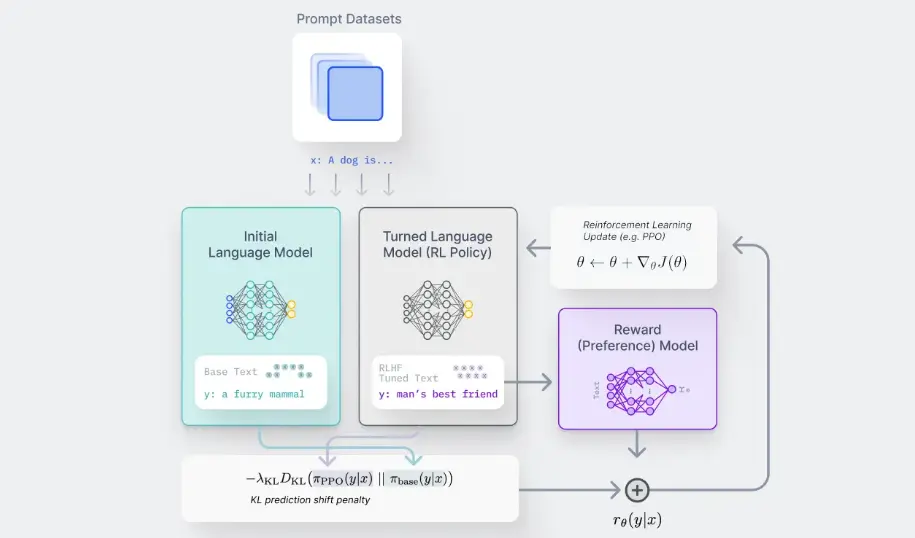
Figure: Techniques to Fine-Tune Model with Reinforcement Learning with Human Feedback
Step 1: Applying the Reward Model
At the outset, a user's input, referred to as a prompt, is directed to the RL policy, which is essentially a refined version of the language model (LM).
The RL policy generates a response, and the reward model assesses both the RL policy's output and the initial LM's output. The reward model assigns a numeric reward value to gauge the quality of these responses.
Step 2: Establishing the Feedback Loop
This process is iterated within a feedback loop, allowing the reward model to assign rewards to as many responses as resources permit.
Responses receiving higher rewards gradually influence the RL policy, guiding it to generate responses that better align with human preferences.
Step 3: Quantifying Differences Using KL Divergence
A pivotal role is played by Kullback-Leibler (KL) Divergence, a statistical technique that measures distinctions between two probability distributions.
In RLHF, KL Divergence is employed to compare the probability distribution of the current responses generated by the RL policy with a reference distribution representing the ideal or most human-aligned responses.
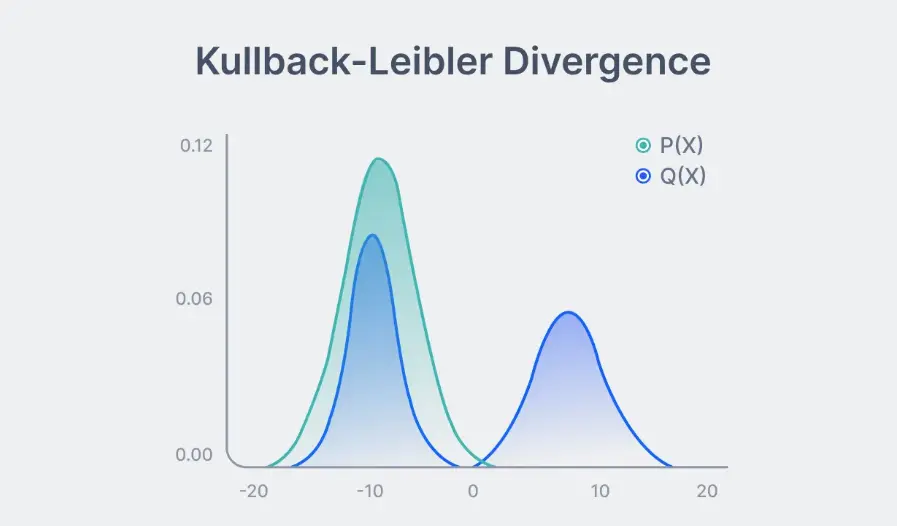
Figure: Measuring Similarity between Probability Distribution
Step 4: Fine-tuning Through Proximal Policy Optimization
Integral to the fine-tuning process is Proximal Policy Optimization (PPO), a widely recognized reinforcement learning algorithm known for its effectiveness in optimizing policies within intricate environments featuring complex state and action spaces.
PPO's strength in maintaining a balance between exploration and exploitation during training is particularly advantageous for the RLHF fine-tuning phase.
This equilibrium is vital for RLHF agents, enabling them to learn from both human feedback and trial-and-error exploration. The integration of PPO accelerates learning and enhances robustness.
Step 5: Discouraging Inappropriate Outputs
Fine-tuning serves the purpose of discouraging the language model from generating improper or nonsensical responses.
Responses that receive low rewards are less likely to be repeated, incentivizing the language model to produce that more closely align with human expectations.
Challenges Associated with Reinforcement Learning with Human Feedback
What are the difficulties and restrictions associated with RLHF?
- Variability and human mistakes: Feedback quality can differ among users and evaluators.
Experts in specific domains like science or medicine should contribute feedback for tackling intricate inquiries, but locating these experts can be costly and time-intensive. - Question phrasing: The accuracy of answers hinges on the wording of questions. Even with substantial RLHF training, an AI agent struggles to grasp user intent without adequately trained phrasing.
This can lead to inaccurate responses due to contextual misunderstandings, although rephrasing the question may resolve this issue. - Bias in training: RLHF is susceptible to machine learning biases. While factual queries yield one correct answer (e.g., "What's 2+2?"), complex questions, especially those related to politics or philosophy, can have multiple valid responses.
AI tends to favor its training-based answer, introducing bias by overlooking alternative responses. - Scalability: Since RLHF involves human input, the process tends to be time-intensive.
Adapting this method to train larger, more advanced models requires significant time and resources due to its dependency on human feedback.
This can potentially be alleviated by devising methods to automate or semi-automate the feedback loop.
Conclusion
As we conclude our exploration of Reinforcement Learning from Human Feedback (RLHF), it’s clear that this innovative approach is reshaping the landscape of AI interactions.
By integrating human feedback, we enhance the performance of large language models, leading to richer and more satisfying user experiences.
Remember, while RLHF presents tremendous potential, it's essential to remain vigilant about the challenges it faces, such as biases and the need for high-quality feedback.
The journey of refining AI is ongoing, and your insights and engagement can drive meaningful progress. Together, let’s navigate the future of AI and ensure it aligns with our collective values.
Frequently Asked Questions
1. What purpose does RLHF serve?
Reinforcement Learning from Human Feedback (RLHF) is a machine learning strategy that merges reinforcement learning methods like rewards and comparisons with human direction to educate an artificial intelligence (AI) agent. Machine learning plays a crucial role in the development of AI.
2. How does the process of reinforcement learning from human feedback function?
Once the initial model is trained, human evaluators offer their input on its performance. These human trainers assign scores indicating the quality or accuracy of outputs produced by the model.
Subsequently, the system assesses its performance using human feedback to generate rewards for the purpose of reinforcement learning.
3. Can you provide an illustration of reinforcement learning in humans?
Consider a young child seated on the ground (representing their present state) who takes an action – attempting to stand up – and subsequently receives a reward. This scenario encapsulates reinforcement learning concisely.
Although the child might not be familiar with walking, they grasp it through experimentation and learning from mistakes.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
