

Recognize Anything: A Large Model For Multi Label Tagging
Explore the Recognize Anything Model (RAM), a cutting-edge solution for multi-label image tagging. RAM integrates high-quality data, a universal label system, and transformer-based architecture for enhanced recognition, enabling broader, zero-shot image tagging.


In the realm of multi-label image recognition, often referred to as image tagging, the objective is to assign semantic labels to images by identifying multiple relevant labels for a given image.
This task holds considerable significance in computer vision, given that images inherently encompass multiple labels pertaining to objects, scenes, attributes, and actions.
Unfortunately, existing models in multi-label classification, detection, segmentation, and vision-language approaches have displayed limitations in their tagging capabilities.
Two primary challenges impede progress in image tagging. Firstly, there is the need for more large-scale, high-quality data. Specifically, there needs to be a universal and unified labeling system and an efficient data annotation engine capable of semi-automatic or even fully automatic annotation for extensive image datasets encompassing numerous categories.
Secondly, there is a need for an efficient and adaptable model design capable of leveraging large-scale weakly-supervised data to construct a versatile and potent model.
In this blog, we will discuss about RAM (Recognize Anything Model), which is a recently published model, along with its architecture and performance details.
Table of Contents
- About Recognize Anything Model
- Architecture Details
- Evaluation and Comparison
- Limitations
- Conclusion
- Frequently Asked Questions
About Recognize Anything Model
To address these critical obstacles, the authors of this paper introduce the Recognize Anything Model (RAM), a robust foundational model for image tagging. RAM overcomes challenges related to data, including label system, dataset, and data engine, as well as limitations in model design.
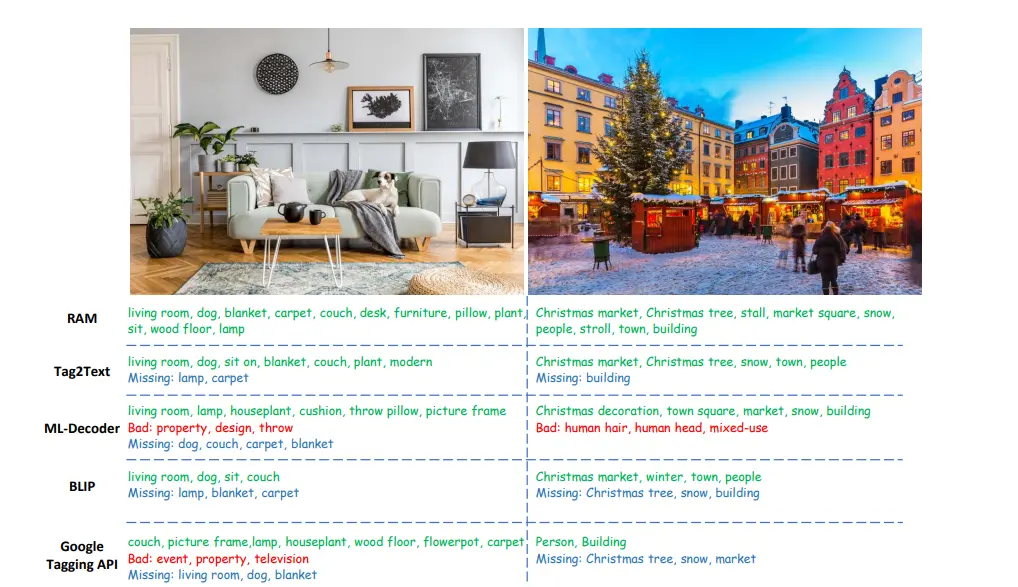
Figure: SAM compared to other image tagging models
Label System
The authors initiate the process by establishing a universal and unified label system. This system incorporates categories from prominent academic datasets (classification, detection, and segmentation) as well as commercial tagging products (Google, Microsoft, Apple).
The label system is created by amalgamating all publicly available tags with common tags derived from textual sources, thus covering a substantial portion of common labels with a manageable total of 6,449. Any remaining open-vocabulary labels can be identified through open-set recognition.
Dataset
The challenge of automatically annotating large-scale images with the established label system is addressed by drawing inspiration from CLIP and ALIGN, which utilize publicly available image-text pairs at scale to train robust visual models.
Similar datasets are employed for image tagging, and following the approach in previous research, text parsing is used to obtain image tags from the provided texts. This method enables the acquisition of a diverse collection of annotation-free image tags that correspond to image-text pairs.
Data Engine
However, the image-text pairs obtained from the web are inherently noisy and often contain missing or inaccurate labels. To enhance the quality of annotations, a tagging data engine is designed.
To address missing labels, existing models are utilized to generate additional tags. A process is employed for inaccurate labels to identify specific regions within the image that correspond to different tags.
Subsequently, region clustering techniques are used to identify and remove outliers within the same class. Additionally, tags that exhibit contradictory predictions between entire images and their corresponding regions are filtered out to ensure cleaner and more accurate annotations.
Model
While Tag2Text has demonstrated strong image tagging capabilities by integrating image tagging and captioning, RAM takes a step further by enabling generalization to previously unseen categories through the incorporation of semantic information into label queries.
This innovative model design empowers RAM to excel in recognizing a wide range of visual data, underscoring its potential for diverse applications.
Leveraging large-scale, high-quality image-tag-text data and the synergistic integration of tagging with captioning, the authors have developed a robust model called RAM. RAM represents a groundbreaking paradigm for image tagging, demonstrating that a general model trained on noisy, annotation-free data can outperform fully supervised models.
RAM's advantages include exceptional image tagging capabilities with robust zero-shot generalization, affordability and reproducibility with open-source and annotation-free datasets, and versatility across various application scenarios.
By selecting specific classes, RAM can be tailored to address specific tagging needs, and when combined with localization models such as Grounding DINO and SAM, it forms a potent and versatile pipeline for visual semantic analysis.
Architecture Details
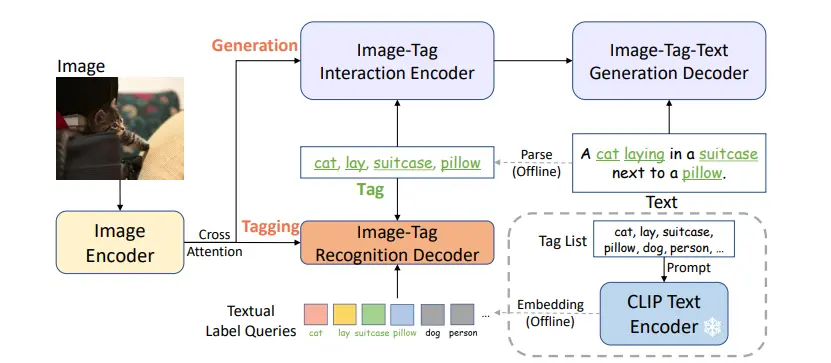
Figure: Description of RAM's model structure
Extensive image tags are derived from image-text pairs using automated text semantic parsing. RAM combines the tasks of generating captions and assigning tags through image-tag-text triplets.
Additionally, RAM incorporates a readily available text encoder to transform tags into textual label queries with context that is semantically rich, enabling the model to generalize to previously unseen categories during the training phase.
The RAM model utilizes the Swin-transformer as its image encoder, as it has demonstrated superior performance in both vision-language and tagging domains compared to the basic Vision Transformer (ViT).
In terms of architecture, the RAM model employs 12-layer transformers for text generation in the encoder-decoder setup, while the tag recognition decoder consists of 2 layers. The model leverages the pre-existing text encoder from CLIP to obtain textual label queries and employs prompt ensembling.
Additionally, the RAM model incorporates the CLIP image encoder to distill image features, thus improving its ability to recognize unseen categories through the alignment of image-text features.
Evaluation and Comparison
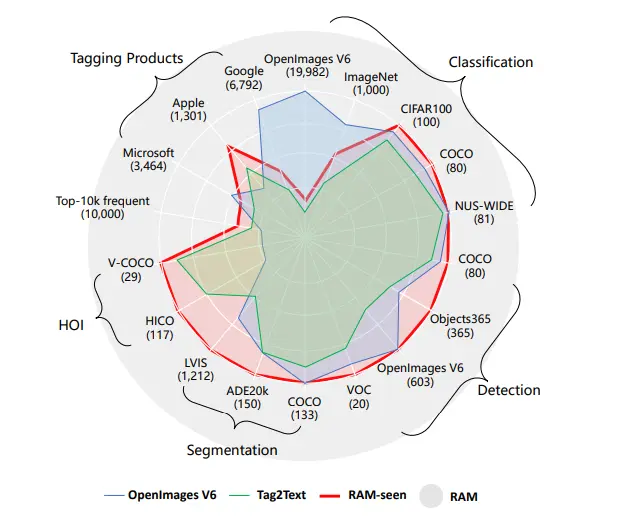
Figure: RAM Compared to other tagging models.
In the above figure, we can observe the recognition capabilities of various tagging models. Tag2Text identifies over 3,400 fixed tags, whereas RAM significantly enhances this number to over 6,400 tags.
RAM's expanded scope encompasses a broader range of valuable categories compared to OpenImages V6. Moreover, RAM's open-set capability allows it to recognize any common category potentially.
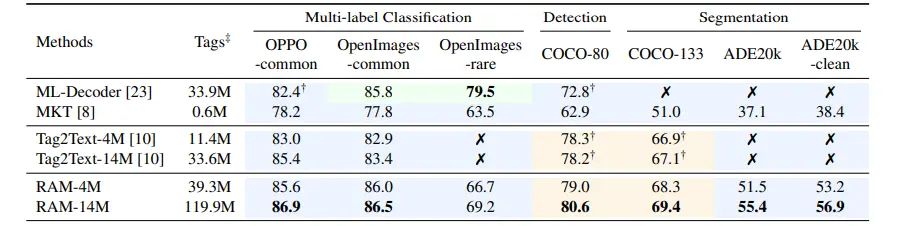
Figure: Comparison of RAM with other SOTA models in different Tasks.
In the evaluation of mAP (mean Average Precision) compared to classification models, certain cells are marked with ✗, indicating an inability to assess performance under those conditions.
The background color of the cells provides additional information: Green signifies results from fully supervised learning, Blue indicates zero-shot performance, and Yellow denotes scenarios where the model has encountered the corresponding training images but lacks annotations.
Notably, RAM outperforms ML-Decoder in zero-shot generalization to OpenImages-common categories. Additionally, RAM exhibits the ability to recognize categories in OpenImages-rare, even though it had no exposure to them during training.
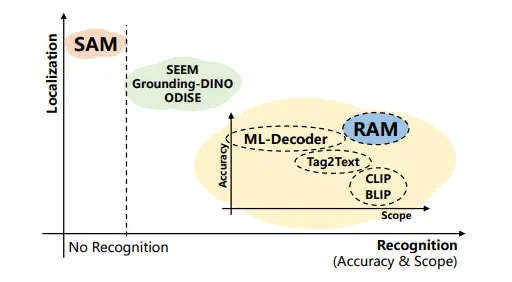
Figure: SAM performs exceptionally well in localization tasks but faces challenges in recognition tasks. On the other hand, RAM stands out for its remarkable recognition capabilities, surpassing existing models in both accuracy and the range of categories it can recognize.
Limitations
Just like CLIP, the present iteration of RAM demonstrates strong performance in identifying everyday objects and scenes but encounters difficulties when confronted with more abstract tasks like counting objects.
Additionally, RAM's zero-shot performance falls behind task-specific models in tasks that demand fine-grained classification, such as distinguishing between various car models or pinpointing specific species of flowers or birds. RAM is trained on open-source datasets, which could potentially result in reflecting dataset biases.
Conclusion
In conclusion, the Recognize Anything Model (RAM) represents a significant advancement in the field of multi-label image recognition, addressing critical challenges related to data and model design.
RAM's universal label system and the use of large-scale, annotation-free datasets set the stage for its exceptional performance in recognizing a broad range of visual categories. Its architecture, incorporating transformers and semantic information, empowers RAM to excel in image tagging and captioning tasks.
Through evaluations and comparisons, RAM demonstrates its capability to outperform existing models in recognizing common categories and showcases its impressive zero-shot generalization. However, it is important to acknowledge RAM's limitations, particularly in abstract tasks and fine-grained classification.
RAM stands as a powerful and versatile tool for image recognition, offering a robust solution for various computer vision tasks. Its ability to handle open-set scenarios and its potential for diverse applications make it a promising model in the ever-evolving field of computer vision.
Frequently Asked Questions
1. What exactly is the Recognize Anything Model (RAM)?
RAM represents a groundbreaking image tagging model that marks a substantial leap forward in the realm of computer vision.
Unlike conventional approaches, RAM doesn't depend on manual annotations for its training; instead, it harnesses large-scale image-text pairs to learn and perform its tasks. This innovative approach sets it apart from traditional methods in the field.
2. What is image tagging or image recognition?
Image tagging involves the task of recognizing and assigning labels to the elements within an image. This can be accomplished through manual efforts, where individuals observe the image and provide descriptions, or it can be automated using machine learning techniques.
3. What are the available methods for image tagging?
There are two main approaches: manual image tagging and AI image tagging. Let's examine the distinctions between these two methods. Manual tagging involves a human individually reviewing each image within the system and assigning a set of tags to it.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
