

Evaluating OpenSeed on Various Datasets


In the previous article, we explored how OpenSeeD works, its architecture, and the challenges it solved.
Now that we’ve covered the fundamentals, it's time to delve into something just as crucial, "the performance of OpenSeeD" on various datasets. How well does this model perform when put to the test on real-world data?
Performance in machine learning, particularly in object detection and segmentation tasks, can vary drastically depending on the dataset being used.
In this article, we’ll break down how OpenSeeD was evaluated, the importance of dataset-specific results, and why this performance matters in practical applications.
Overview of Performance Evaluation
The performance of a model like OpenSeeD isn’t just about how well it does in a lab setting but how well it generalizes to a variety of datasets.
In order to validate OpenSeeD's multi-tasking abilities for both segmentation and detection, the authors evaluated the model on several well-known datasets across different domains. The results help us understand how robust and scalable this model truly is.
OpenSeeD's evaluations are usually based on key metrics such as IoU for segmentation tasks and mAP for object detection.
These are the gold-standard measures used to quantify a model's ability to identify objects correctly and to ensure that the predictions align closely with the ground truth.
Importance of Dataset-Specific Results
Why is evaluating across different datasets so important?
In the field of computer vision, no two datasets are alike. Some datasets, like COCO, contain a mix of everyday objects in varied settings.

Others, like ADE20K or LVIS, have more complex scenes with more fine-grained categories. Generalization across datasets is key to the utility of a model in real-world applications.
When models are only trained on specific datasets, they often perform well on similar data but struggle with generalization to unseen tasks or environments.
OpenSeeD, however, tackles this problem through its unique architecture that decouples segmentation and detection tasks, allowing it to perform well on diverse datasets.
As a result, OpenSeeD achieves more consistent performance across these varied domains, proving its effectiveness in both segmentation and detection.
By performing well on challenging datasets, OpenSeeD demonstrates that it can not only handle real-world data but also adapt to new contexts where traditional models might fall short.
Performance of OpenSeeD on Various Datasets
In this section, we will explore how OpenSeeD performs across several benchmark datasets, focusing on Panoptic Segmentation on COCO and Instance Segmentation on ADE20K and Cityscapes. These datasets are critical in evaluating the real-world effectiveness of the model.
General Performance Metrics
OpenSeeD demonstrates exceptional flexibility and robustness, achieving state-of-the-art (SOTA) performance across multiple segmentation and detection tasks.
- Direct Transfer: OpenSeeD can be applied immediately for tasks like panoptic segmentation and object detection without further fine-tuning, showcasing its power as a versatile model that generalizes well across different datasets.
- Task-Specific Transfer: Fine-tuning on specific datasets further enhances its performance, establishing new SOTA records in segmentation and detection tasks.
Panoptic Segmentation on COCO
The COCO dataset is one of the most widely used benchmarks for panoptic segmentation, where models must detect both stuff (background regions like sky, road) and things (discrete objects like people, cars) in a unified manner.
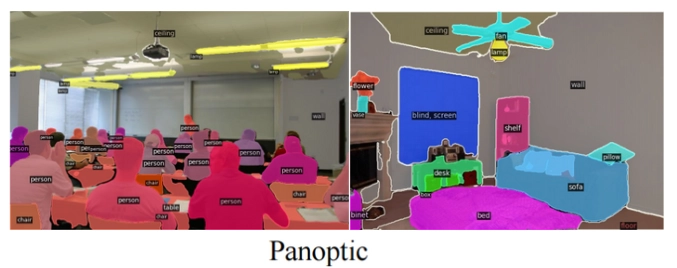
Panoptic Quality (PQ): OpenSeeD achieves an impressive 59.5 PQ on the COCO panoptic segmentation task. PQ is a composite metric that balances both segmentation quality and detection accuracy.
This SOTA result indicates that OpenSeeD excels at accurately segmenting both foreground objects and background regions while minimizing errors in pixel classification.
This high performance without additional fine-tuning underscores OpenSeeD's strong generalization ability, effectively handling COCO’s diverse image content and complex scenes.
Instance Segmentation on ADE20K and Cityscapes
Instance segmentation involves identifying individual object instances within an image, ensuring each instance is correctly labeled and segmented.
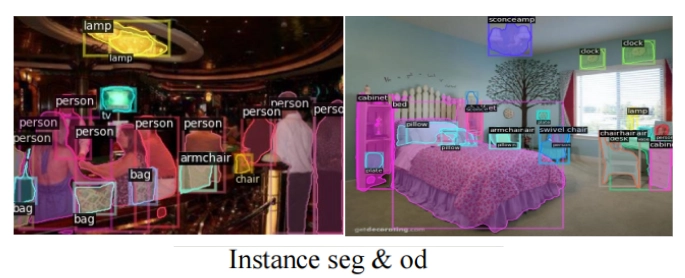
OpenSeeD shines on the ADE20K and Cityscapes datasets, which are crucial benchmarks for evaluating the granularity and precision of instance segmentation models.
ADE20K
- The ADE20K dataset includes a wide range of scenes, from natural environments to urban landscapes, making it a challenging testbed for segmentation models.
- OpenSeeD achieves 53.7 PQ in panoptic segmentation and 42.6 AP (Average Precision) in instance segmentation when evaluated using a 1280 × 1280 image size.
- The PQ score reflects the model's ability to correctly segment both background and individual object instances, while the AP score reflects its accuracy in detecting object instances within the scene.
- These results indicate OpenSeeD's superiority in handling complex, multi-object environments with diverse types of scenes.
Cityscapes
- The Cityscapes dataset focuses on street-level imagery and urban environments, which require models to excel at detecting small objects and managing occlusions.
- OpenSeeD achieves 48.5 AP in instance segmentation on Cityscapes, demonstrating its capability in urban scenes with numerous, often occluded, objects (such as cars, pedestrians, etc.).
Overview of Direct Transfer Results
Direct Transfer refers to OpenSeeD’s ability to generalize to segmentation and detection tasks immediately after pretraining, without further fine-tuning.
OpenSeeD achieves state-of-the-art (SOTA) performance on various datasets purely from its pretraining setup.
- COCO Panoptic Segmentation: OpenSeeD achieves a remarkable 59.5 Panoptic Quality (PQ) score on the COCO dataset without any fine-tuning.
This score highlights its strong performance in balancing detection and segmentation tasks across a wide range of objects and scenes. - Instance Segmentation in the Wild: Evaluated across 25 instance segmentation datasets under the Segmentation in the Wild (SegInW) tests, OpenSeeD improves segmentation performance by over 10 AP compared to existing models, showcasing its flexibility in handling diverse domains.
- Object Detection in the Wild: When tested on 35 object detection datasets under the Object Detection in the Wild (ODinW) tests, OpenSeeD’s tiny model outperforms GLIP-T by 2.8 AP.
This result demonstrates the model's ability to generalize well to real-world detection tasks without additional training.
Task-Specific Fine-Tuning
While Direct Transfer showcases OpenSeeD’s pretraining effectiveness, Task-Specific Fine-Tuning further enhances its performance on specific datasets, optimizing the model for domain-specific challenges.
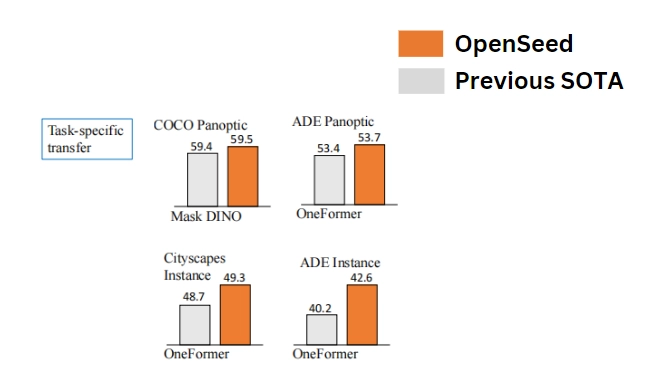
Fine-tuning allows OpenSeeD to adapt its features to the particular characteristics of the dataset, leading to SOTA results.
ADE20K Dataset: When fine-tuned on the ADE20K dataset for panoptic segmentation and instance segmentation.
OpenSeeD achieves 53.7 Panoptic Quality (PQ) for panoptic segmentation. And 42.6 Average Precision (AP) for instance segmentation at a resolution of 1280 × 1280.
These results reflect the model’s enhanced ability to detect and segment individual objects with higher precision in complex environments.
Cityscapes Dataset: The Cityscapes dataset, which focuses on street-level scenes with multiple objects and heavy occlusions, provides another benchmark for fine-tuned models.
OpenSeeD achieves 48.5 AP for instance segmentation. This score represents the model’s strength in accurately detecting small and occluded objects, which are common in urban scenes.
Segmentation and Detection in the Real World
OpenSeeD showcases its impressive capability to generalize across diverse datasets through its Segmentation in the Wild (SeginW) and Object Detection in the Wild (ODinW) evaluations.

These benchmarks test OpenSeeD’s ability to perform on datasets that vary widely in terms of object types, scene complexity, and domain-specific challenges.
Performance on SeginW (25 Segmentation Datasets)
SeginW evaluates OpenSeeD on 25 instance segmentation datasets, which include diverse real-world tasks ranging from everyday objects to complex, occluded objects in specific contexts (such as natural scenes, vehicles, or urban landscapes).
- Improved Segmentation Performance: OpenSeeD demonstrates its detection supervision advantage, leading to over 10 AP improvement in segmentation performance.
This result showcases the model's ability to handle segmentation tasks in the wild, especially when applied to previously unseen domains. - Wide Generalization: Despite the challenges of these 25 datasets, OpenSeeD excels by adapting to the complexities of each dataset.
This flexibility is powered by the model’s decoupled architecture, allowing it to separate segmentation and detection tasks more effectively than traditional models.
Key Highlights:
- 10 AP boost due to its unique architecture and detection supervision.
- Success across a wide array of segmentation tasks without requiring dataset-specific fine-tuning.
Performance on ODinW (35 Detection Datasets)
The ODinW benchmark evaluates OpenSeeD’s object detection capabilities across 35 different datasets, each presenting distinct detection challenges.
This test covers a broad range of domains, from urban environments and natural scenes to retail and industrial settings.
- Outperformance of Competitors: OpenSeeD's tiny model consistently outperforms GLIP-T by 2.8 AP in object detection tasks.
This result demonstrates the model’s ability to generalize across various object categories and domains, even when directly compared with other leading models in the field. - Real-World Applicability: The ODinW datasets reflect real-world challenges, such as identifying small objects, detecting occluded or overlapping objects, and maintaining precision across diverse environmental settings.
OpenSeeD’s high performance on these benchmarks highlights its practical applicability in industries like retail, automotive, and urban planning.
Key Highlights:
- 2.8 AP improvement over leading competitor GLIP-T.
- Strong performance across datasets with diverse detection challenges, proving its utility in real-world applications.
Detailed Results on Specific Datasets
The performance of OpenSeeD on various datasets demonstrates its versatility and effectiveness across a wide range of real-world tasks, from vehicle detection and segmentation to retail object detection.
Below is a breakdown of its performance across specific datasets, focusing on the vehicle detection and segmentation, retail object detection, and the COCO dataset.
Vehicle Detection and Segmentation
Keywords Used: truck, van, car, motorcycle, bus, bicycle

OpenSeeD was evaluated on vehicle detection and segmentation tasks using these common vehicle-related keywords.
The model’s performance in identifying and segmenting different types of vehicles is a testament to its robustness in urban environments where transportation is a critical aspect.
Detection Accuracy and Errors:
- High Accuracy: OpenSeeD accurately detects and segments all the vehicle types listed. For each category (e.g., truck, car, bus), the detection rate is high, with a low error margin.
- Error Rate: The probability of incorrect labeling for vehicles is approximately 10%, meaning that in most cases, vehicles are labeled correctly.
However, errors occur in distinguishing between similar vehicle types (e.g., confusing a van for a bus), particularly when objects are occluded or the vehicle is partially visible.
This performance is crucial for real-world applications like traffic management, autonomous driving, and urban planning, where accurate vehicle detection is paramount.
Retail Object Detection
Keywords Used:
- ice cream, toothpaste, bottle, retail item, packet, packaging

In the retail space, OpenSeeD was tested to detect and segment various retail items, ranging from everyday products like ice cream and toothpaste to general packaging.
Misclassification and Labeling Challenges:
- Packet and Toothpaste Detection: The model struggles significantly with detecting certain retail items. For example, OpenSeeD failed to detect and segment 49 out of 50 packets and toothpaste items in the test set.
This challenge is likely due to the variety in packaging shapes and sizes that are not adequately represented in the training data. - Misclassification of Bottles: One notable issue is that the model frequently misclassified packets and other items as bottles, labeling 25 out of 50 objects incorrectly.
This suggests that while the model excels at detecting certain retail items, it requires further fine-tuning to handle the nuanced differences between products. - Partial Detection: In some instances (e.g., 4 out of 50 objects), the model detected parts of a packet but misidentified them as other objects, such as bottles.
These challenges indicate that OpenSeeD can perform well in structured retail environments but struggles when faced with more irregular or ambiguous items. This highlights areas for improvement in object detection for retail-specific applications.
COCO Dataset
The COCO dataset is a widely used benchmark for both object detection and segmentation. OpenSeeD’s performance on COCO showcases its ability to generalize across a variety of object categories.

Performance on Various Object Categories:
- OpenSeeD was evaluated using generalized object categories like vehicle, animal, flower, vegetable, person, bird, food, drink, cat, train.
- The model's performance varies depending on the object category. For instance, animals and vehicles posed a challenge for the model when using generalized keywords like "animal" or "vehicle."
However, when more specific labels such as "cat" or "car" were used, the model achieved a much higher detection and segmentation accuracy.
Generalized Keywords vs. Specific Labels:
- Generalized Keywords: When using broad terms like “animal” or “vehicle,” the model struggled to distinguish between different types within the category.
For example, detecting a cat under the keyword "animal" proved challenging, leading to lower accuracy. - Specific Labels: When more specific labels (e.g., cat, car) were employed, the model performed significantly better, accurately detecting and segmenting 47 out of 50 objects.
This shows that OpenSeeD excels with clear, specific object labels but may struggle with broad or ambiguous terms.
This performance on COCO underscores OpenSeeD’s strength in handling detailed and fine-grained tasks, particularly when given specific information, making it ideal for applications where object categories are well-defined.
Conclusion
OpenSeeD delivers state-of-the-art performance across various datasets, excelling in both segmentation and detection tasks.
In direct transfer, the model achieves top results without the need for fine-tuning, such as 59.5 PQ on COCO panoptic segmentation, while its task-specific fine-tuning sets new benchmarks on datasets like ADE20K and Cityscapes.
These results highlight OpenSeeD’s robust generalization abilities and adaptability to different tasks and domains.
In real-world applications, OpenSeeD's strengths such as its ability to handle Segmentation in the real world and Object Detection in the real world make it highly applicable across industries like autonomous driving, retail, and urban planning, where precise object detection and segmentation are critical.
FAQs
1. What is open-set object detection?
Open-set object detection refers to the model's ability to detect and identify objects that were not part of its training dataset.
Unlike closed-set detection, where a model is limited to recognizing only a fixed set of predefined object categories, open-set detection aims to generalize and identify unseen or unknown object categories in real-world environments.
2. How does open-set object detection differ from closed-set detection?
In closed-set detection, the model is trained to recognize a specific set of object classes, and any object outside these classes is ignored or misclassified.
In contrast, open-set detection models are designed to identify objects that belong to classes not seen during training. This makes open-set detection more suitable for real-world applications where new, unknown objects frequently appear.
3. What are the main challenges of open-set object detection?
The primary challenges include:
- Generalization: Open-set models must generalize to unseen object classes without overfitting to the training data.
- Confidence Calibration: The model must accurately estimate when an object does not belong to any known category and classify it as unknown.
- Data Scarcity: Limited labeled data for unknown objects makes training more difficult.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
