

Opik Is Changing How You Evaluate LLMs — Find Out How
Opik by Comet automates LLM evaluation, detects errors and hallucination. It tracks decisions, flags mistakes, and removes manual testing.


Did you know that over 60% of enterprise AI failures are caused by issues like hallucinations, poor monitoring, and weak evaluation methods?
Many companies invest in powerful AI models, but when they go live, they don’t perform as expected, leading to costly mistakes and a loss of trust.
As an AI engineer, I faced this firsthand.
I wanted to compare different LLMs for various tasks, but I quickly realized many benchmarks didn’t cover key failure points.
Manually testing models became overwhelming.
I spent more time evaluating than actually analyzing where models hallucinate.
That’s when I discovered Opik by Comet, a powerful LLM evaluation framework, helps.
![]()
In this blog, we’ll show how Opik helps developers with LLM evaluations, automated testing, and real-time monitoring.
Why Do We Need Opik?
Large Language Models (LLMs) are powerful, but they aren't perfect.
They can hallucinate, lose context, or give unreliable answers, especially when used in real-world applications.
Opik helps developers detect issues early, improve model performance, and ensure reliability at scale.
These are some of the problem which is faced by AI engineers-
- Inefficient way to detect hallucination in LLM responses
- Difficulty in understanding LLM Chain of thought and workflow
- Inability to check LLM response's relevance and accuracy
Inefficient way to detect hallucination in LLM responses
LLMs also made up information called hallucinations in their reasoning, and spotting these took a lot of time.
Developers used manual testing and basic logging.
They would only spot errors like hallucinations or lost context after the LLM made mistakes.
Fixing these issues was slow and often relied on guesswork.

Difficulty in understanding LLM Chain of thought and workflow
AI engineers found it hard to understand and debug how large language models (LLMs) reasoned through tasks.
Chain-of-thought (CoT) prompting broke tasks into steps, but engineers couldn’t easily see if each step made sense.
They lacked tools to view intermediate outputs or track how prompts changed during reasoning.
Engineers had to check outputs manually, which was slow and error-prone.

Inability to check LLM response's relevance and accuracy
AI engineers struggled to check if LLM responses were accurate and relevant, especially in complex tasks like Retrieval-Augmented Generation (RAG).
They had to manually review each answer to see if it matched the context or user question.
This was slow and often missed subtle mistakes, like saying “Berlin” instead of “Paris” for the Eiffel Tower’s location.
There were no standard ways to measure how well an answer used the given context.

Features of Opik
Opik is packed with powerful features that make working with large language models (LLMs) easier, more transparent, and efficient.
Here’s how it helps AI engineers and researchers streamline LLM evaluation and monitoring-
- Hallucination detection in LLM responses
- Trace responses for LLM prompt and track LLM decision Workflow
- Improving LLM response
- Real-time monitoring of LLM performance
Hallucination detection in LLM responses
Opik catches hallucinations as soon as they occur, so the LLM always gives reliable answers.
It alerts developers immediately if the system makes mistakes, allowing them to fix problems quickly.
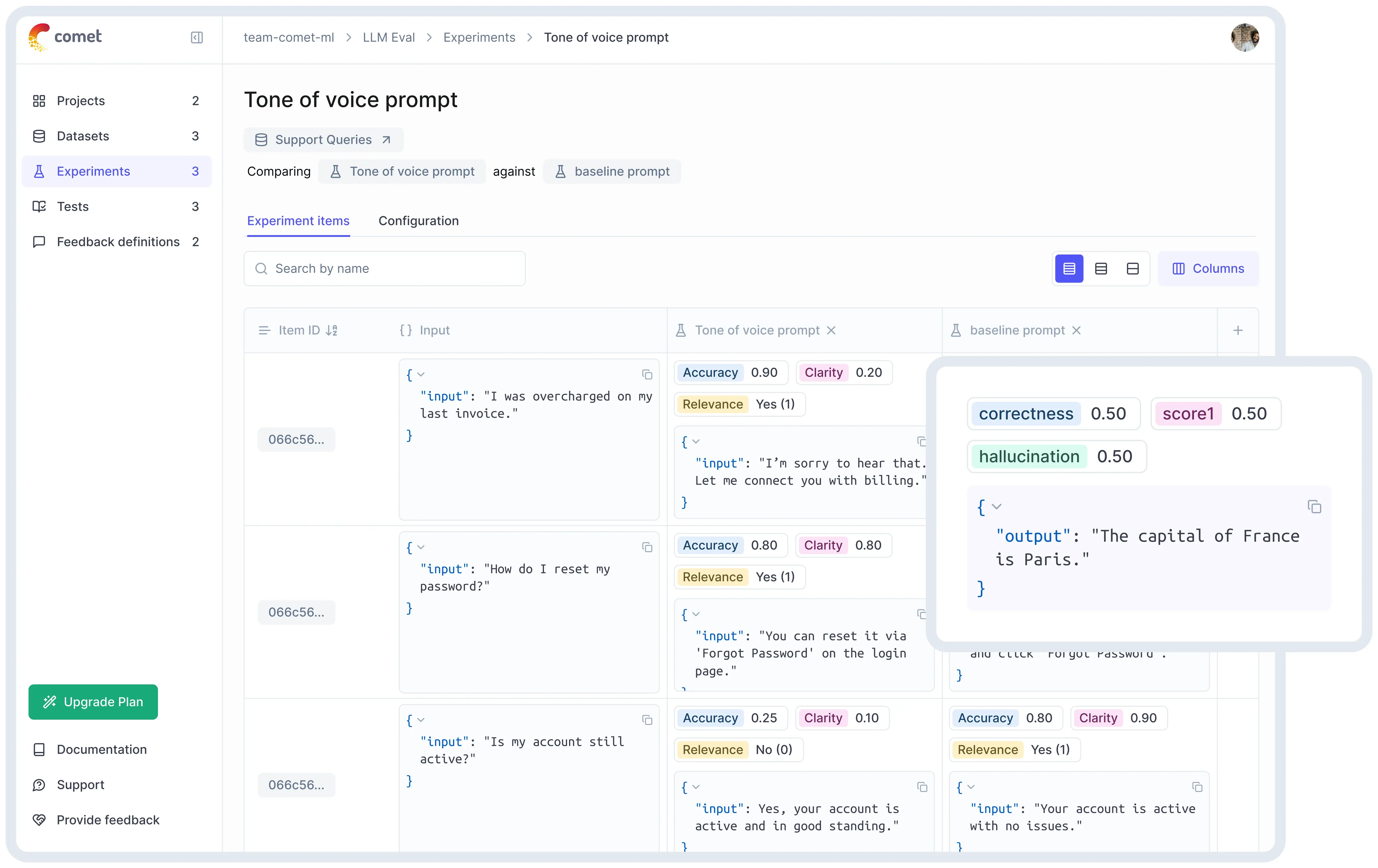
Trace responses for LLM prompt and track LLM decision Workflow
Opik tracks everything an LLM does, from the prompts you provide to the responses it generates.
It also logs intermediate steps in complex workflows, helping you see exactly how the model makes decisions.

This makes debugging easier, especially when working with multiple AI components.
Improving LLM response
Opik checks how accurate, relevant, and clear the chatbot’s responses are.
It finds unclear training data and weak prompts, helping developers improve the chatbot's behavior.

Real-time monitoring of LLM performance
Opik helps you track your LLM’s performance live.
You can monitor key metrics like response quality, speed, and cost, ensuring smooth operations in production environments.

How does Opik help industry-wise?
Opik provides industry-specific solutions by addressing key challenges in Large Language Model (LLM) applications.
Here’s how Opik helps various industries.
| Industry | How AI is Used | Problems AI Faces | How Opik Helps |
|---|---|---|---|
| Healthcare | Medical chatbots, diagnosis assistants | Incorrect answers, missing important details | Finds mistakes in responses, ensures accuracy |
| Legal | Contract review, legal research assistants | Misinterpreted legal terms, inconsistent wording | Tracks errors, ensures legal accuracy |
| E-Commerce | Customer support bots, product recommendations | Wrong product suggestions, inaccurate descriptions | Checks if responses match customer needs |
| Finance | Fraud detection, financial reports | False alerts, incorrect summaries | Reduces errors, ensures correct financial insights |
| Education | AI tutors, study material generators | Incorrect facts, poor explanations | Evaluates content for accuracy and relevance |
| Technology | Code generation, debugging assistants | Wrong or buggy code, poor error handling | Checks code quality, finds patterns in errors |
| Retail | Personalized shopping assistants | Irrelevant product recommendations | Improves recommendations, checks for accuracy |
| Research & Development | Scientific summarization, hypothesis generation | Hallucinated facts, misleading summaries | Finds and flags false or misleading information |
Future scope of Opik
Opik is continuously evolving to provide better evaluation, monitoring, and debugging tools for Large Language Models (LLMs).
Benchmarking Across Diverse Metrics
- Current Challenge: Many LLMs are not evaluated on nuanced benchmarks like hallucination detection, moderation, or context consistency.
- Future Direction: Opik will enable developers to define custom evaluation metrics tailored to specific tasks, industries, or use cases.
Automated Evaluation Pipelines
- Current Challenge: Manual evaluation is time-consuming and prone to human error.
- Future Direction: Opik automates the testing process by integrating evaluation pipelines into CI/CD workflows. Developers can run large-scale tests using pre-configured metrics or create their own via Opik’s SDK.
Multi-Agent System Evaluation
- Current Challenge: Complex workflows involving multiple LLMs or agents are difficult to benchmark effectively.
- Future Direction: Opik’s ability to trace and log interactions step-by-step allows developers to evaluate each component individually and as part of a system. This ensures better benchmarking for multi-agent architectures like Retrieval-Augmented Generation (RAG) systems.
Conclusion
AI models are smart, but they can still make mistakes.
Without proper testing and monitoring, they can give wrong answers, forget important details, or lose context in long conversations.
That’s why over 60% of AI projects fail, not because the models are bad but because companies don’t track and evaluate them properly.
Opik fixes this problem. It helps developers automatically test LLMs, catch errors in real time, and improve responses without wasting hours on manual debugging. With Opik, you can:
✅ Find and fix hallucinations before they cause problems
✅ Track LLM performance live and catch issues as they happen
✅ Debug conversations to make sure AI doesn’t lose context
✅ Optimize prompts and automate evaluation instead of doing it by hand
If you work with LLMs, Opik makes your job easier and helps you build AI that’s more accurate, reliable, and ready for the real world.
FAQ
How does Opik facilitate the debugging of complex LLM workflows?
Opik simplifies LLM debugging by logging every step, detecting hallucinations, and monitoring real-time performance. It enables fast troubleshooting with minimal code, automated evaluations, and CI/CD integration for seamless AI deployment.
How does Opik's UI improve the data collection and annotation process for LLMs?
Opik's UI simplifies data collection and annotation with intuitive uploads, interactive feedback, and built-in evaluation tools. It streamlines LLM development by automating scoring, versioning datasets, and integrating real-world feedback for continuous improvement.
Reference

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
