

OpenSeeD Framework Explained!


Are you struggling with balancing segmentation and detection tasks in your computer vision projects? Does your model often misclassify background elements or struggle to detect smaller objects in complex scenes?
If so, you're not alone. Many practitioners in the field of computer vision face significant challenges when trying to perform both segmentation and detection using traditional models.
In fact, studies reveal that over 60% of machine learning developers report issues with cross-task interference, where shared model architectures fail to generalize effectively across both tasks. This results in lower accuracy for both segmentation and detection, especially when applied to unseen data.
But what if there was a model that could overcome these challenges?
That’s where OpenSeeD comes in. OpenSeeD addresses these problems through decoupled decoding, which separates the processing of foreground and background elements.
By doing so, it minimizes task interference and improves performance across both segmentation and detection. This approach ensures more accurate segmentation masks and precise object detection, solving the discrepancies that often arise in traditional models.
That’s where OpenSeeD comes into play. It’s an open-vocabulary segmentation and detection framework designed to address the specific challenges of managing segmentation and detection tasks simultaneously, delivering state-of-the-art performance without the need for extensive fine-tuning.
Table of Contents
Overview of OpenSeeD
OpenSeeD is an innovative model that bridges the gap between segmentation and detection tasks.
Built on a unified semantic space, it decouples object queries into foreground and background categories, allowing the model to handle segmentation and detection in a more balanced and accurate manner.
It further refines this process using conditioned mask decoding, where bounding box information from object detection guides and improves segmentation masks.
Key Contributions of the Research
- Unified Framework for Segmentation and Detection: OpenSeeD introduces a shared semantic space that allows the same model to excel in both segmentation and detection tasks.
- Decoupled Object Queries: The model separates foreground and background elements, significantly reducing interference between tasks, and leading to better object detection and segmentation precision.
- State-of-the-Art Results: OpenSeeD achieves competitive performance across several datasets, demonstrating superior zero-shot transferability, and sets new benchmarks in panoptic and instance segmentation tasks.
Challenges Addressed by OpenSeeD
Traditional models often face significant challenges when tasked with both segmentation and detection.
Challenges in Segmentation and Detection Tasks
These tasks require different approaches: segmentation focuses on pixel-level precision, while detection works with bounding boxes for entire objects.
In most models, a shared processing architecture causes interference between these tasks, leading to compromised performance.
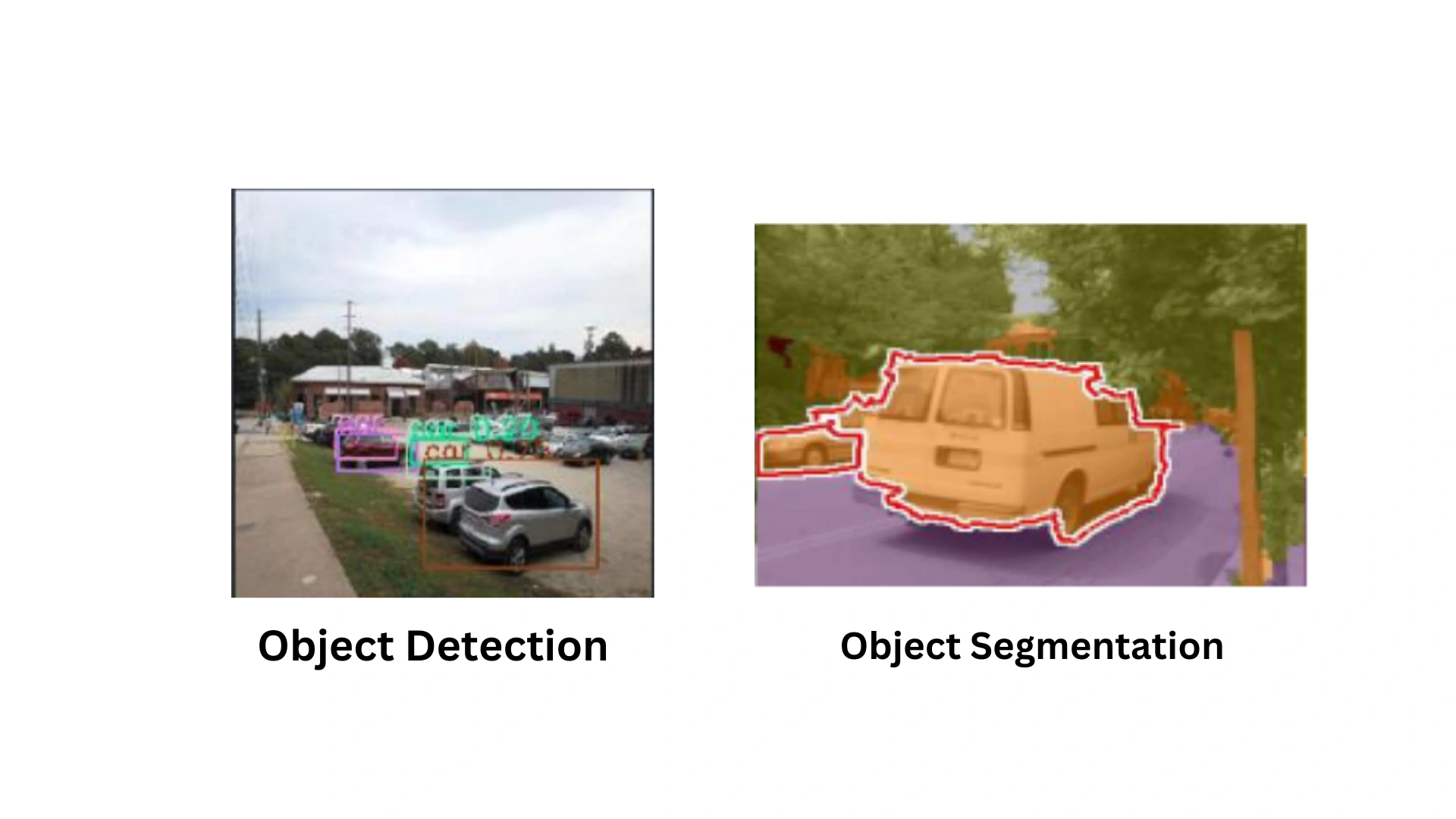
- Segmentation Discrepancies: In segmentation, background elements are often misclassified, and the model struggles to separate objects from complex backgrounds. Without task-specific adaptations, these models fail to generate accurate masks.
- Detection Discrepancies: For detection, foreground objects may be affected by segmentation errors, especially when detecting smaller or occluded objects. The same architecture used for both tasks results in suboptimal object localization and inaccurate bounding boxes.
OpenSeeD addresses these issues through a decoupled decoding approach, which separates the processing of foreground and background elements. Decoupling object queries for segmentation and detection minimizes interference between tasks and improves performance in both areas.
Limitations of Traditional Models
Traditional multi-task models struggle with generalization across diverse datasets. Segmentation and detection models are typically trained on domain-specific data, making it difficult for them to perform well on unseen data categories.
This results in poor cross-task generalization, where models trained for one task or dataset (e.g., COCO) underperform when applied to others (e.g., ADE20K).
Traditional models also rely on bounding box annotations for detection and pixel-wise mask annotations for segmentation, but they lack a unified approach to bridge the gap between these types of annotations.
This limits their flexibility and makes them inefficient for real-world applications that require both segmentation and detection.
OpenSeeD overcomes these limitations with a unified semantic space that uses a single text encoder to align visual tokens across tasks.
Additionally, conditioned mask decoding leverages bounding box information from detection to refine segmentation masks, leading to more precise object shapes and significantly improved generalization across datasets.
OpenSeeD Architecture
OpenSeeD is a sophisticated open-vocabulary segmentation and detection model that introduces a more unified approach to handling both tasks. This architecture solves key challenges through three primary features: Unified Semantic Space, Decoupled Object Queries, and Conditioned Mask Decoding.

Unified Semantic Space
The core of OpenSeeD’s architecture is its Unified Semantic Space, which allows both segmentation and detection tasks to operate within a shared framework. This is achieved by using a single text encoder that aligns visual tokens (representations of objects in the image) with semantic concepts (labels or classes) across both tasks.
- Concept Alignment: In traditional models, segmentation and detection tasks often use separate pipelines, causing inefficiencies. OpenSeeD bridges this gap by unifying the way it processes visual data.
For example, whether the task is segmentation or detection, the visual token for an object like "dog" is aligned with the corresponding semantic label, ensuring consistent representation across both tasks. - Transferability: This unified space allows for improved zero-shot transferability, meaning that the model can generalize better to unseen categories, as it doesn’t need to be retrained on new classes.
This feature enables OpenSeeD to perform well across a wide range of datasets without losing accuracy, making it an adaptable solution in real-world scenarios.
Decoupled Object Queries
A major architectural advancement in OpenSeeD is its use of Decoupled Object Queries.

Traditional models tend to use the same set of queries for both foreground (objects) and background elements, which often leads to interference between the two, lowering overall accuracy.
- Foreground Queries: These are dedicated to identifying the primary objects of interest within an image, such as cars, animals, or people. These queries are designed to work for both detection (drawing bounding boxes) and segmentation (creating masks).
- Background Queries: These queries are focused on identifying and segmenting background elements like the sky, trees, or roads.
Background queries are used exclusively for segmentation tasks to ensure that the model can more accurately separate foreground objects from their surroundings.
By separating the queries for foreground and background tasks, OpenSeeD reduces task interference, leading to better object detection and more precise segmentation. This decoupling enhances the model’s ability to differentiate between objects of interest and their environments, particularly in complex scenes.
Conditioned Mask Decoding
The third critical feature of OpenSeeD’s architecture is Conditioned Mask Decoding, which refines segmentation by using detection information (bounding boxes) to guide the mask generation process.
- Bounding Box Assistance: Traditional models often generate segmentation masks directly from pixel-level data, which can lead to inaccuracies when objects are small or partially occluded.
OpenSeeD introduces a novel approach where the bounding box generated during object detection is used to condition (or guide) the segmentation process.
This ensures that the segmentation mask fits accurately within the detected bounding box, improving the shape and precision of the object mask. - Precision and Accuracy: By conditioning mask generation on bounding boxes, OpenSeeD significantly reduces the chances of errors, such as masks that spill over into adjacent objects or background areas.
This process ensures a more precise segmentation outcome, particularly in complex images with multiple overlapping objects.
Features of OpenSeeD
OpenSeeD introduces several features that significantly enhance the efficiency and accuracy of open-vocabulary segmentation and detection.
Below are three key features: Mapping Hypothesis Verification, Interactive Segmentation, and Unified Loss Function, all of which help OpenSeeD overcome common challenges in the field.
Mapping Hypothesis Verification
Mapping Hypothesis Verification is a testing approach employed by OpenSeeD to assess how well its model generalizes to unseen categories.
This is crucial for open-vocabulary tasks, where the model must handle objects or concepts it has not encountered during training.
- Hypothesis: OpenSeeD's hypothesis is that if the model is trained on well-annotated datasets (such as COCO), it should still perform well on completely new datasets (like ADE20K) without additional retraining.

This assumption tests the model’s ability to "map" learned semantic representations to new data.
For example, if the model has learned to recognize "dog" from bounding boxes and masks, it should still be able to recognize and segment new animal categories like "deer" in different datasets.
- Verification Process: To verify this hypothesis, the researchers trained OpenSeeD on one dataset (such as COCO) and evaluated its segmentation and detection performance on a different dataset (ADE20K).
The results demonstrated that OpenSeeD could generate high-quality masks even for unseen categories, highlighting its strong zero-shot generalization capabilities.
Interactive Segmentation
Interactive Segmentation is another powerful feature of OpenSeeD, designed to enhance user experience and efficiency in annotating images.
Traditional models require pixel-wise annotations, which can be time-consuming and error-prone.
- Simplified User Interaction: In OpenSeeD, the user can draw a simple bounding box around an object, and the model automatically generates a high-quality segmentation mask for the object.
This greatly reduces the time and effort required for manual image labeling, making the process much more user-friendly. - High-Quality Annotations: OpenSeeD’s interactive segmentation is particularly effective for scenarios where only bounding boxes are provided, yet precise masks are needed.
This feature is made possible by the Conditioned Mask Decoding technique, which uses bounding box information to refine mask generation, ensuring that the mask aligns accurately with the object’s shape.
Impact: This feature has substantial practical implications, especially in industries where large-scale image annotation is required.
It accelerates the process while maintaining the accuracy needed for high-quality datasets in fields like medical imaging, autonomous driving, and retail product recognition.
Unified Loss Function
The Unified Loss Function is a critical feature that allows OpenSeeD to seamlessly handle both segmentation and detection tasks using a single framework.
Traditional models often use separate loss functions for these tasks, which can lead to suboptimal performance as the tasks conflict with one another.
Combining Multiple Loss Components: OpenSeeD’s unified loss function incorporates different components:
- Mask Prediction Loss: Penalizes the model for incorrect or imprecise segmentation mask predictions.
- Bounding Box Loss: Encourages accurate prediction of bounding box coordinates in detection tasks.
- Class Prediction Loss: Ensures the correct identification of object classes during detection and segmentation.
Handling Diverse Annotations: A major challenge in training multi-task models is that segmentation tasks require detailed mask annotations, while detection tasks only provide bounding box annotations.
OpenSeeD’s unified loss function bridges this gap by converting bounding boxes into a format that the model can use to generate masks. This allows the model to learn segmentation from bounding boxes even in detection datasets.
Benefits: This unified approach not only simplifies the training process but also ensures that the model performs both tasks efficiently without needing separate training pipelines.
It helps OpenSeeD achieve state-of-the-art performance in both segmentation and detection, significantly reducing training complexity while improving accuracy across different datasets.
Conclusion
OpenSeeD has made a significant impact in computer vision by solving long-standing challenges in open-vocabulary segmentation and detection.
Its architectural features have raised the bar for multi-task models, particularly in terms of generalization, efficiency, and user interaction.
As future research continues to refine these capabilities, OpenSeeD is poised to become a foundational model for real-world applications requiring both segmentation and detection across various domains.
FAQs
1. What is open-set object detection and segmentation?
Open-set object detection and segmentation refer to the ability of a model to identify and segment objects that belong to classes it has never seen during training.
Unlike traditional models that can only classify objects from a fixed set of categories, open-set models can generalize to novel categories in real-world environments without requiring retraining.
2. How does OpenSeeD handle unseen object categories in open-set detection and segmentation?
OpenSeeD utilizes a unified semantic space and decoupled object queries, which allow it to generalize across different datasets.
The unified semantic space ensures that both known and unseen objects are mapped to consistent visual and semantic representations, while decoupled queries separate background and foreground objects, minimizing interference between tasks and improving generalization to new categories.
3. Can OpenSeeD be used in real-time applications for open-set segmentation and detection?
Currently, OpenSeeD is optimized for high accuracy in segmentation and detection tasks, but real-time performance would require further optimizations.
Future research may focus on improving the model's processing speed to support real-time applications, such as autonomous driving or robotics while maintaining its state-of-the-art accuracy.
References

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
