

Everything You Need To Know About OpenAI's New Luanched GPT 4o


OpenAI introduces GPT-4o in May 2024, a new language model pushing the boundaries of AI capabilities. This groundbreaking model surpasses its predecessors by reasoning across audio, vision, and text, making it a true multimodal model.
While still under development, the GPT-4o boasts impressive efficiency, achieving faster speeds and lower costs compared to the previous model GPT-4 with Vision (GPT-4T). This development paves the way for a future with useful AI applications.
Table of Contents
- What does "multimodal" mean?
- What are the benefits of this multimodality?
- Key Improvements introduced in GPT-4o
- Exploring Potential Use Cases
- Conclusion
- FAQ
- References
What does "multimodal" mean?
Imagine interacting with a computer that not only understands your written text, but can also interpret visual information like images and even respond to your spoken questions and instructions. That's the power of GPT-4o's multimodality. Here's a breakdown of the different modalities it can handle:
Text
This remains a core strength, allowing users to interact with GPT-4o through natural language prompts and questions.
.webp)
The image above represents the evaluation of several LLM models compared across multiple benchmarks for textual data, which shows GPT-4o's better performance.
In the following areas, GPT-4o consistently receives the highest scores: Massive Multitask Language Understanding (88.7%), General Purpose Open Question Answering (53.6%), Mathematical Problem Solving (78.6%), Human-Level Task Evaluations (90.2%), Multi-Genre Shared Tasks (90.5%), and Discrete Reasoning Over Paragraphs (86.0%).
This shows that GPT-4o outperforms other models including GPT-4T, Claude 3 Opus, and Gemini Ultra 1.0 in a variety of tasks, demonstrating its robustness and versatility.
Images
GPT-4o can analyze images and respond accordingly. Imagine asking it to describe the content of a photo, answer questions about objects within it, or even generate creative text formats inspired by the image.
The above image shows a table comparing the performance of several AI models (GPT-4o, GPT-4T, Gemini 1.0 Ultra, Gemini 1.5 Pro, and Claude Opus) across various evaluation sets.
GPT-4o consistently outperforms other models in most benchmarks, achieving the highest scores in MMU (69.1%), MathVista (63.8%), AI2D (94.2%), ChartQA (85.7%), DocVQA (92.8%), ActivityNet (61.9%), and EgoSchema (72.2%).
GPT-4T and Claude Opus follow closely in several metrics, while Gemini 1.0 Ultra and Gemini 1.5 Pro generally score lower, highlighting GPT-4o's superior performance across diverse evaluation criteria.
Audio
This opens up exciting possibilities for voice interaction. Users can potentially speak questions or prompts to GPT-4o and receive spoken responses in real-time, similar to a human conversation.
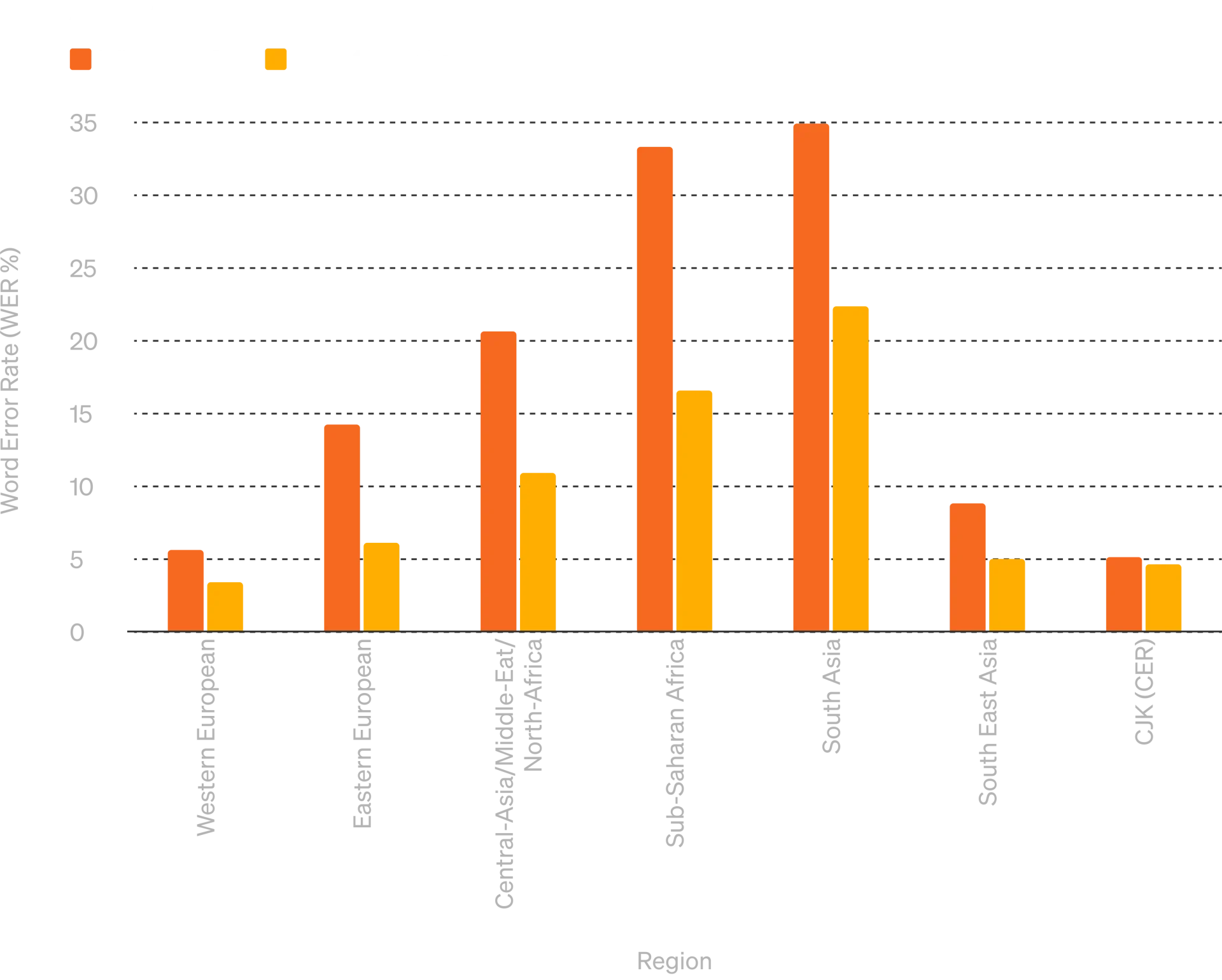
The image presents a bar graph comparing the Word Error Rate (WER%) of Whisper-v3 and GPT-4o (16-shot) in audio ASR (Automatic Speech Recognition) across various parts of the world. Lower WER% indicates better performance.
GPT-4o consistently outperforms Whisper-v3 in most regions, including Eastern European, Central Asia/Middle-East/North Africa, Sub-Saharan Africa, and South East Asia, demonstrating significantly lower error rates.
While both models perform well in Western European and CJK regions, Whisper-v3 has notably higher error rates in challenging regions like South Asia and Sub-Saharan Africa, where GPT-4o shows a marked improvement, indicating its superior accuracy and robustness in diverse linguistic contexts.
Here is an example of real-time translation posted by OpenAI.
What are the benefits of this multimodality?
The ability to understand and respond to information across different formats offers several advantages:
Richer Understanding
Accessing information through diverse formats allows GPT-4o to develop a more comprehensive understanding of a topic. For instance, combining textual descriptions with visual data from an image can provide a richer context for generating responses.
Enhanced User Experience
The ability to interact with AI through text, voice, and images caters to different user preferences. This makes GPT-4o more approachable and user-friendly, allowing people to interact with AI in ways that feel natural to them.
Broader Applications
The multimodal capabilities open doors to a wider range of applications. Consider using GPT-4o for:
Image-based search engines: Ask questions about an image and get relevant answers.
Educational tools: Combine text, images, and audio to create interactive learning experiences.
Improved chatbots: Create chatbots that understand complex queries across different modalities, leading to more helpful interactions.
Key Improvements introduced in GPT-4o
GPT-4o boasts several advancements compared to its predecessors, making it a more powerful and efficient multimodal model. Here's a closer look at the key improvements and features it offers:
1. Blazing Speed
OpenAI claims GPT-4o to be twice as fast as GPT-4 with Vision (GPT-4T). This translates to quicker processing times for user requests.
Imagine asking GPT-4o a complex question that requires analyzing an image and generating a text response. With its increased speed, GPT-4o can deliver the answer in a shorter timeframe, making the interaction feel more natural and real-time.
2. Reduced Costs
Good news for developers! GPT-4o is said to be 50% cheaper for both input and output tokens compared to GPT-4T. This means it costs less to process information and generate responses, making it a more accessible option for a wider range of users and projects.
3. Increased Processing Power
The five times higher rate limit in GPT-4o signifies a significant boost in processing power. Think of it like having access to more lanes on a highway. This allows GPT-4o to handle more requests simultaneously, leading to faster response times and improved overall performance.
4. Expanded Context Window
The context window refers to the amount of information GPT-4o considers when generating a response. GPT-4o boasts a larger context window of 128K tokens, allowing it to take into account a wider range of information from previous interactions or prompts.
This can lead to more comprehensive and relevant responses that are better aligned with the overall context.
5. Unified Model Architecture
Unlike previous versions that relied on separate models for handling text, images, and audio, GPT-4o operates as a single, unified model. This eliminates the need to switch between different models for different tasks, resulting in a seamless user experience.
Imagine interacting with one interface that can understand your requests regardless of whether you use text, voice, or images. This unified approach simplifies interaction and streamlines the workflow
Exploring Potential Use Cases
The innovative multimodal capabilities of GPT-4o open up a wide range of possible applications in numerous fields. Let's explore some interesting use cases and practical examples to demonstrate its revolutionary potential:
1. Computer Vision Applications in Real-Time
GPT-4o's ability to combine speed with visual processing makes it perfect for real-time computer vision applications. Consider the following situations:
On-the-Go Navigation: During your journey, aim the camera on your phone toward a notable landmark. In addition to identifying the location and offering directions or historical details, GPT-4o is capable of real-time image analysis.
Visual data analysis in real-time: picture law enforcement officers utilizing GPT-4o equipped with body cameras. Real-time scene analysis can be used to notice suspicious activities, translate foreign-language signage, and even identify objects.
2. Multimodal One-Device Interaction
User experience is streamlined when multiple modalities can be used for interaction on a single device. How to do it is as follows:
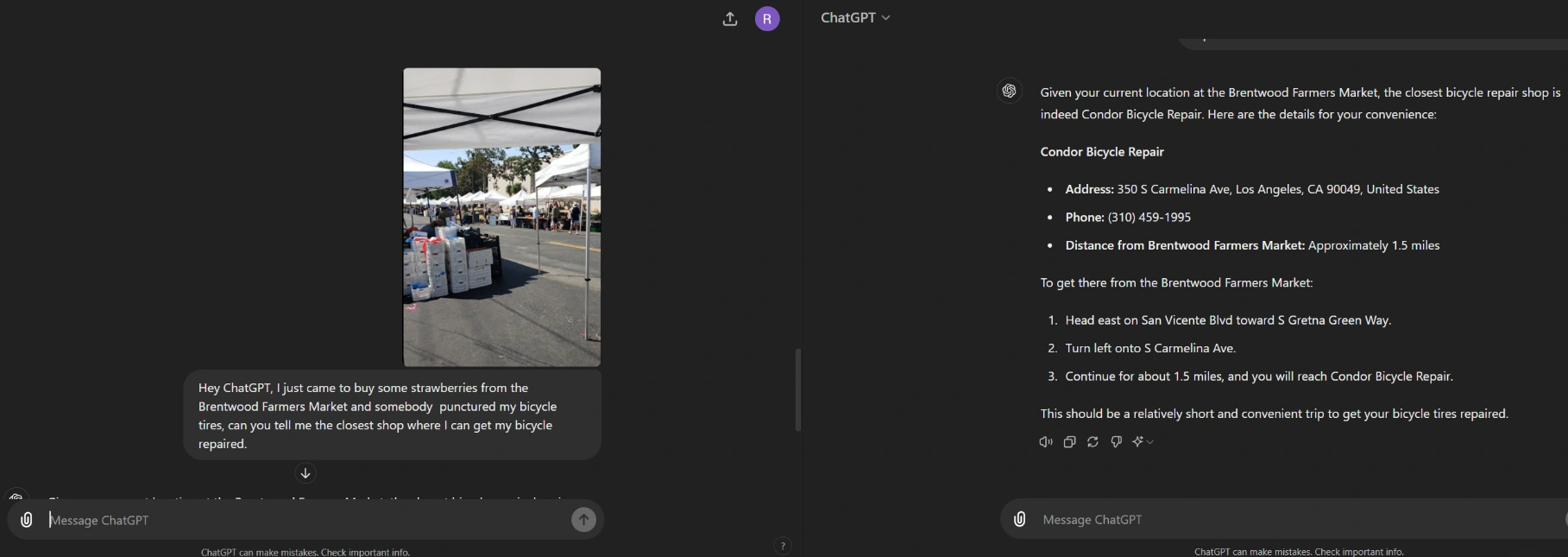
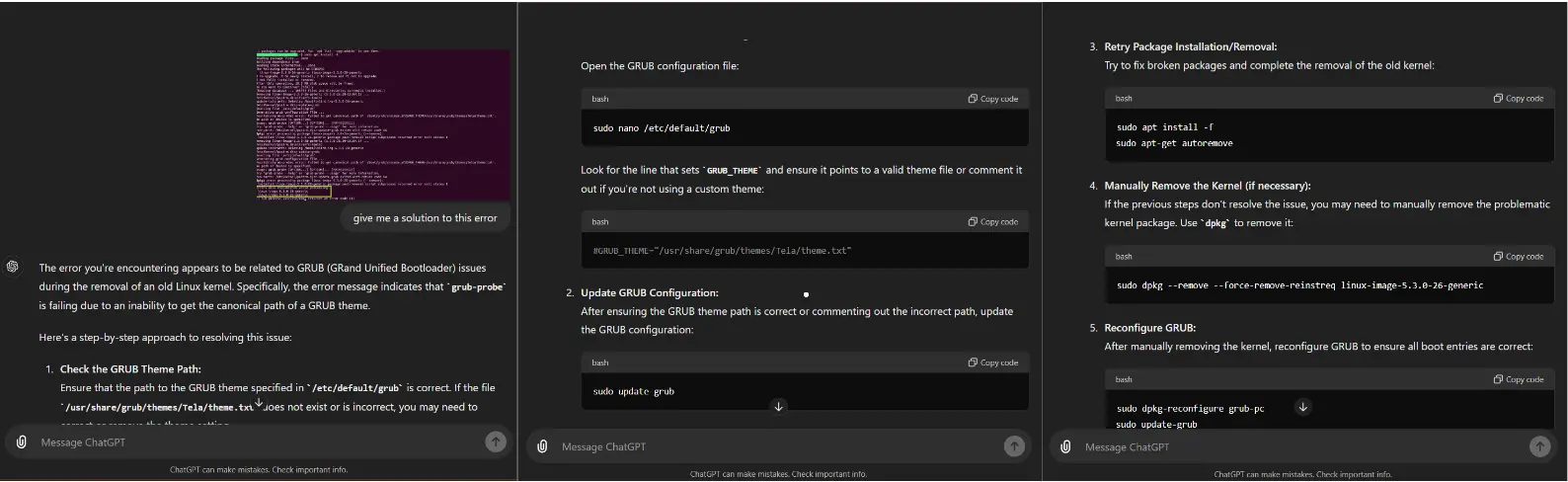
Multimodal Troubleshooting: Is your PC having technical problems? Ask a query and display the error message on GPT-4o's screen in place of written descriptions. This integrates textual and visual data to provide a more precise diagnosis.
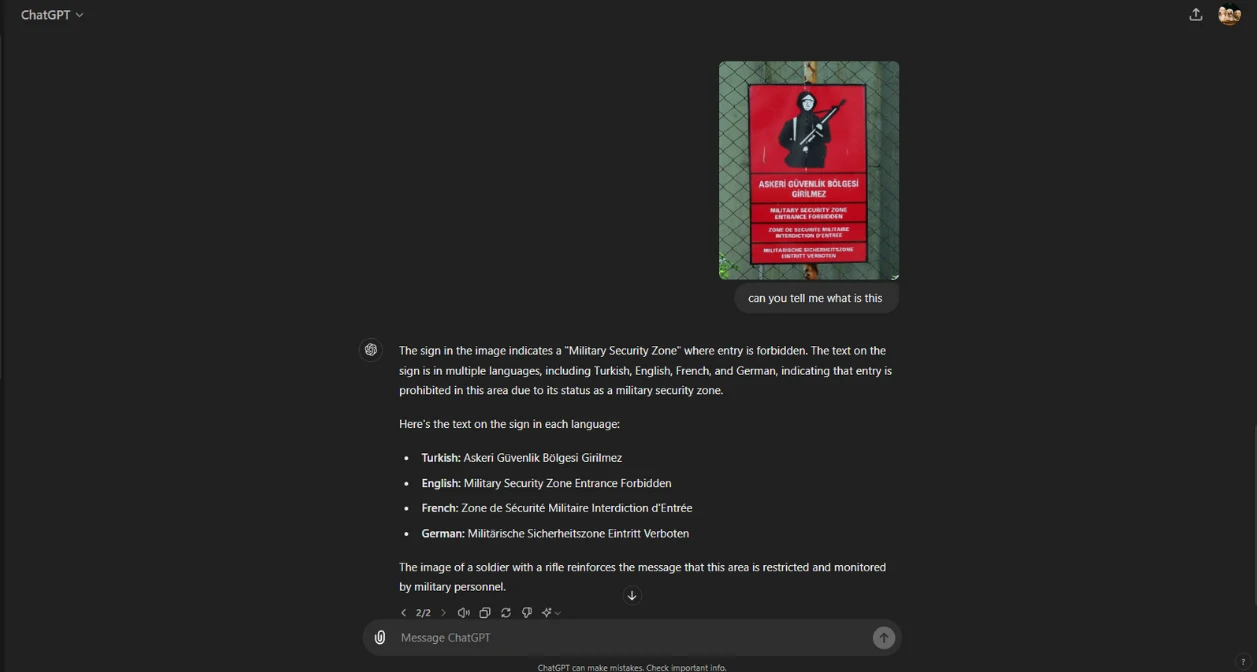
Smooth Processing of Content: Eliminate all copying and pasting! You can interact with visual material on your device directly using GPT-4o. Consider marking text in a picture and asking it to provide a translation or an overview of the content.
3. Business Software
The enhanced performance of GPT-4o can be incorporated into enterprise applications, while it is not a full substitute, particularly when:
When it comes to activities where appropriate open-source models are unavailable, GPT-4o can serve as a valuable foundation. In an e-commerce application, for instance, a business might employ GPT-4o for classifying images while they have the resources to create their own image classifier.
Rapid prototyping: Development cycles can be completed more quickly thanks to the faster processing speed. Before spending money on specialized models, businesses can use GPT-4o to prototype complex workflows including visual components.
Personal Experience
Text Understanding and Generation
Advantages: The exceptional text understanding and generating capabilities of GPT-4o are impressive. It performs similarly to GPT-4 Turbo in code and English, but its real power is in non-English languages. Up to 25,000 words of text can be processed by it, making it an effective tool for producing original material and comprehending natural language.
Disadvantages: Although GPT-4o does well in most situations, occasional "hallucinations" are still a cause for concern. In these cases, the model produces information that is inaccurate but believable. It is vital to guarantee precision and understanding of context, particularly in sensitive domains.
Image Interpretation
Advantages: GPT-4o outperforms current models in terms of vision understanding. It can even create captions and provide answers to questions about images. What distinguishes the model is its capacity to process fine-grained features in images.
Disadvantages: It can be difficult to manage complex visual situations and keep consistency across several image domains. A significant factor in the model's performance is the quality and variety of the training set.
Audio Interaction
Advantages: GPT-4o's real-time audio response is remarkable. The average delay is only 320ms, which is close to the speed of human speech. Its smooth interaction improves user experience and is perfect for interactive apps and voice assistants.
Disadvantages: GPT-4o can understand audio quite well, it is unable to directly observe tone, many speakers, or background noise. It's still difficult to capture subtle emotional nuances and ensure appropriate context.
Integrated Multimodal Experience
Advantages: GPT-4o integrates all inputs and outputs using a single neural network, as contrast to earlier fragmented methods. A more seamless user experience is produced by the more seamless transitions between text, image, and audio made possible by this comprehensive approach.
Disadvantages: We’re still exploring the limits of GPT-4o’s multimodal capabilities. Balancing accuracy, speed, and context across different modalities requires ongoing research and fine-tuning.
Conclusion
GPT-4o's potential goes much beyond these initial situations. Future developments should see even more ground-breaking applications appear as OpenAI continues to enhance its AI capabilities. Think about these more general implications:
Lower Cost Barriers: As technology develops, GPT-4o should become more affordable to run, opening it up to a larger user base and additional applications.
Improved AI-Human Interaction: Increased productivity and creativity result from the natural collaboration between humans and AI fostered by seamless voice, text, and visual interaction.
AI has a bright future ahead of it, and GPT-4o is a big step toward that future, when intelligent technologies interact with our vision and audio world in a seamless way, enhancing human skills and improving lives in many areas.
FAQ
1. What is GPT-4o and how is it different from GPT-4?
The GPT-4 with Vision (GPT-4T) has been replaced by GPT-4o. GPT-4o is a true multimodal model, which means it can understand and reply to data presented in a variety of media, including text, images, and audio, in contrast to GPT-4T, which focused on text and vision. Further enhancements offered by GPT-4o include a larger context window, quicker processing speeds, and a single architecture for all modalities.
2.What are the key features and advantages of GPT-4o?
Multimodal capabilities: For a natural user experience, communicate with AI via text, speech, or visuals. Quicker processing Receive real-time interactions and faster replies when working with audio and visual data.
Improved output: Increased understanding and accuracy as a result of a more unified model architecture and bigger context window.Economical: Reduced prices per token in comparison to earlier models.
3.What are the use cases for GPT-4o?
Applications for real-time computer vision include image-based search engines, real-time visual data analysis, and mobile navigation.
One-device multimodal interaction: Use your device to display visuals, send text messages, or converse with AI.
Enterprise applications: Workflow prototypes, image classification assignments, and scenarios in which open-source models fall short.
References

Simplify Your Data Annotation Workflow With Proven Strategies
Download the Free Guide