

MiniGPT-4: ChatGPT for Your Images


In today's digital age, images have become integral to our lives. Thanks to the growth of social media and rising smartphone usage, we are taking and sharing more visuals than ever before. Although a wealth of visual data is available, comprehending and analyzing visuals can still be difficult.
MiniGPT-4 can help with that. MiniGPT-4 is a cutting-edge machine learning model that analyses and comprehends photos using the same technology as ChatGPT. With MiniGPT-4, you can create descriptions in natural language, respond to inquiries, and even engage in conversation about any image.
In this blog, we'll explore the capabilities of MiniGPT-4 and how it can be used to enhance your image analysis and understanding. Is it like a chatgpt image captioning version? Don't worry! We'll also discuss some image processing challenges and how MiniGPT-4 overcomes them. So, sit back, relax, and let's dive into the exciting world of MiniGPT-4!
What is MiniGPT-4?
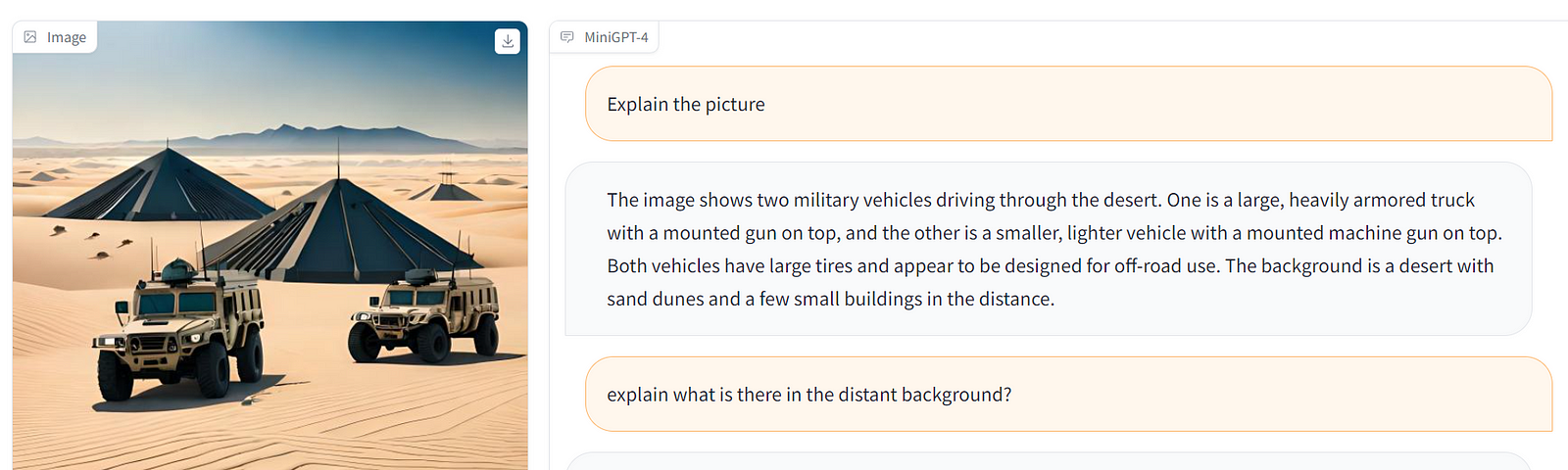
A machine-learning model called MiniGPT-4 is made to analyze and comprehend photos. It is a scaled-down variation of the GPT-4 language model, one of the most sophisticated AI language models currently on the market.
MiniGPT-4 processes and comprehends visual data in a manner that resembles how people process information by employing a method known as self-attention. Because it enables the model to concentrate on specific regions of images and comprehend the links between various objects and attributes, this technique is especially effective for image analysis.
With MiniGPT-4, you can take any image and generate natural language descriptions, answer questions, and even have a conversation about it. This makes it a powerful tool for various applications, including visual search, image captioning, and image retrieval.
The open-source MiniGPT-4 model is developed by a group of Ph.D. students from the King Abdullah University of Science and Technology in Saudi Arabia. It is designed to complete challenging vision-language tasks similar to OpenAI's GPT-4. Vicuna, an advanced LLM in MiniGPT-4, is the language decoder, and it requires a strong, aligned dataset to train on.
One of the most exciting aspects of the system is its extraordinary computational efficiency, which requires only around 5 million aligned image-text pairs to train a projection layer. Co-founder and publisher of THE DECODER Matthias believe that MiniGPT-4 is just another example of how open-source AI is gaining popularity.
Capabilities of MiniGPT-4
MiniGPT-4 is an open-source model that possesses many of the capabilities of GPT-4. It is made to carry out challenging vision-language tasks like generating image descriptions, building websites from scratch, and crafting stories based on given images.
A top-notch, well-aligned dataset is needed for training MiniGPT-4, an advanced LLM known as Vicuna, which serves as the language decoder. The remarkable computational efficiency of MiniGPT-4, which needs just about 5 million aligned image-text pairs to train a projection layer, is one of the technology's most encouraging features.
MiniGPT-4 has demonstrated excellent results in problem identification from image input, for example, by offering a solution based on a user-provided image input of a diseased plant with a prompt asking about what was wrong with the plant. It sounds more like a chatgpt image captioning version. However, MiniGPT-4 must be trained using a high-quality, well-aligned dataset to get beyond the restriction of producing repeated phrases or fragmented sentences.
Technology behind MiniGPT-4

Vicuna is an open-source LLM (Large Language Model) used as the language decoder in MiniGPT-4. According to the GPT-4 evaluation, it is based on LLaMA and achieves 90% of ChatGPT's quality. Vicuna only has 13B characteristics, yet it has amazing linguistic skills2. Using just one projection layer, MiniGPT-4 aligns a frozen visual encoder from BLIP-2 with a frozen LLM, Vicuna.
MiniGPT-4's model architecture is based on BLIP-2. It takes advantage of BLIP-2's pre-trained vision component. It freezes all other vision and language components and adds a single projection layer to align the recorded visual information with the Vicuna language model. When asked to identify issues from photo input, MiniGPT-4 performed admirably. It offered a remedy in response to a user's input of a photograph of a sick plant and a prompt inquiring what was wrong with the plant.
How can MiniGPT -4 be used to enhance your image analysis and understanding?
Using an advanced language model called MiniGPT-4, images can be interpreted, understood, and given text descriptions. It is possible to improve image analysis and comprehension by combining verbal and visual processing.
Many of MiniGPT-4's features are comparable to those of GPT-4, including the ability to produce thorough image descriptions and build websites from handwritten draughts.
Additionally, it can make captions and social media ads, solve problems using image input, and write stories and poems inspired by the images provided. To increase productivity and accuracy in image and language processing activities, MiniGPT-4 can be used in various industries, including e-commerce, healthcare, and manufacturing.
Its open-source solution enables businesses to analyze and understand images efficiently, enhance customer experience, and improve their products and services.
How will MiniGPT -4 help computer vision technology?
MiniGPT-4 is an open-source model that combines language comprehension with visual processing to comprehend images and produce written descriptions.
By increasing its skills in unstructured qualitative comprehensions, such as captioning, question-and-answer, and conceptual understanding, MiniGPT-4 can aid computer vision technology. Using a hand-drawn user interface, MiniGPT-4 can generate in-depth image descriptions, write stories and poems based on provided images, and create websites.
The language decoder in MiniGPT-4 is an advanced LLM named Vicuna, and it needs a good, aligned training dataset. Many new vision-language capabilities, similar to those shown in GPT-4, are produced by MiniGPT-4.
The most recent GPT-4 has shown exceptional multi-modal capabilities, including the ability to recognize hilarious characteristics in photos and create webpages straight from the handwritten text.
The main source of GPT-4's enhanced multi-modal generating capabilities is MiniGPT-4's ability to align a frozen visual encoder with a frozen LLM, Vicuna, using just one projection layer.
Conclusion
In conclusion, MiniGPT-4, chatgpt image captioning is a powerful tool that utilizes the GPT-3.5 architecture to generate captions for images. With its ability to understand the context and content of images, MiniGPT-4 is able to generate accurate and descriptive captions that can enhance the understanding and accessibility of visual media. Its versatility and user-friendliness make it an excellent addition to any AI toolkit for image analysis and captioning.
Want to learn how MiniGPT-4 can help in data curation, EDA and to reduce data preparation lifecycle get on a call with our ML expert.
If you want to know more about such amazing and recent technologies, read here!
FAQs
- What is MiniGPT-4?
To comprehend images and provide written descriptions about them, the AI model MiniGPT-4 combines linguistic and visual processing. It is a kind of computer program that has been taught to spot specific visual elements in pictures and use that knowledge to describe what is in the picture.
2. What is the capability of MiniGPT-4?
In-depth image descriptions, object recognition, scene recognition, caption generation, and social media ad creation are all possible with MiniGPT-4. It can also be used to generate a webpage from a handwritten draught and provide information about an image.
3. How is the use of MiniGPT-4?
A linguistic model and a visual model are trained independently in MiniGPT-4's two-step training procedure before being combined to form a multimodal model. The visual model is trained on a large dataset of images, whereas the linguistic model is developed on a large corpus of text data. On a smaller dataset of image-caption pairings 1, the two models are then integrated and refined.
4. Is it free to use MiniGPT-4?
Yes, MiniGPT-4 is presently available for free download on the group's main website. Users have the option of uploading an image and creating a written description of the image by typing a question into the search box.
5. What are some alternatives to MiniGPT-4?
ChatGPT, AgentGPT, Poet.ly, Golem-GPT, QuickGPT, GPT Android Chat Image Generator, and BabyAGI are a few alternatives to MiniGPT-4. These programs create text descriptions from images using a similar method.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
