

Maximizing Data Ingestion Performance for High-Volume Data Sources


In 2020, 64 zettabytes of data were generated in total!
According to estimates, this amount will climb to 180 zettabytes by 2025 as the number of individuals working from home increases.
With important system sources like smartphones, power grids, stock markets, and healthcare integrating more data sources as storage capacity rises, the volume and diversity of data recorded have also grown quickly.
More businesses are finding effective ways to collect and process data as a result of the increase in data and the rising demand for quick analytics.
Data engineers excel at this! For data engineers and data analysts to execute models of machine learning and data analytics, they need clean datasets, which data engineers are in charge of processing after ingesting raw data from various sources.
An effective data ingestion strategy is the first step in every data engineering effort. Because all machine learning models and analytics are constrained by the quality of data received, ingesting high-quality data is crucial. After all, the quality of your finished product depends on the raw materials.
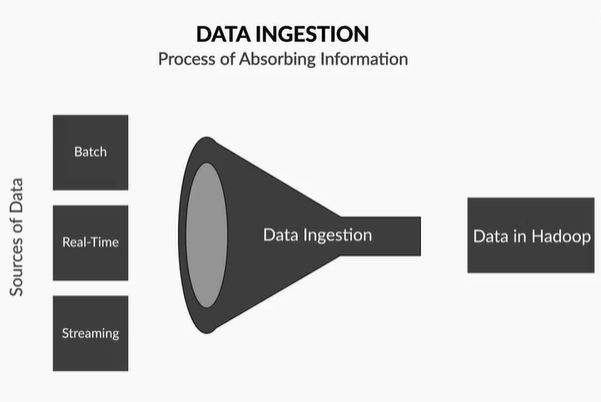
What is data ingestion?
The initial phase of a data engineering project is often data ingestion. It involves gathering data from many sources and moving it to a data warehouse or database wherein analytics and data transformations can be carried out.
The 3Vs architecture of big data, which stands for volume, acceleration, and variety of data getting absorbed, holds the key to comprehending data ingestion. Volume describes how much data is being swallowed; Velocity describes how quickly data enters the pipeline; and Variety describes the many sorts of data, like unstructured and structured data.
Types of Data Ingestion
Batch processing
Batch processing refers to the later processing of data in batches after it has been ingested in an encrypted form for a specified period. The timing of this processing is determined by an interval, such as a certain time each day, intervals of the day, such as 12-hour intervals, or based on a specified condition using event trigger functions. The most popular form of data intake is batch processing.
Processing in real-time
Real-time processing occurs when data can be ingested in an interactive, real-time mode in which it is immediately processed after being ingested. When data is ingested, data engineers create action-taking pipelines that begin working immediately (within seconds).
How does the Data Pipeline's data ingestion process work?
The process of transmitting this ingested data from various sources to various destinations is one of the essential components of the data ingestion pipeline. Excel, databases, JSON data via APIs, system logs, and CSV files are examples of common data sources.
The term "destination" describes the location where the data is delivered. Data lakes, analytical data warehouses, and relational databases are common destinations.
Data ingestion is the process of transferring data from a source to a target location. The primary function of data pipelines is a data ingestion, which has several technologies designed for different purposes. A solid data intake strategy is built on knowing when to employ these technologies.
Let's examine data ingestion processes in more detail.
The gathering of data from multiple sources is the first step in the data ingestion lifecycle. Prioritizing data sources will help ensure that the business-critical data is ingested first. Multiple discussions with stakeholders & product managers are necessary to understand the effective data intake process, prioritize the data being ingested, and comprehend core business data.
The data must then be validated to ensure that it is accurate and suitable for the demands of the business. Tools like Talend and Informatica can be used to validate data. Accepting data from many sources will be made simpler by a sound data validation method, which will also apply unique validation criteria for every data source.
Tools for Data Ingestion Every Data Engineer Should Examine
Each tool has a unique way of ingesting data. Data engineers must therefore be well-versed in the most widely used data ingestion techniques. The processing speed of data, low latency, high throughput, and the sorts of data sources used—such as site clicks, financial activity, social networking feeds, IT logs, and global positioning events—are just a few that should be taken into consideration when evaluating all data input solutions.
Apache Kafka
Kafka is an open-source software distributed streaming technology that is mostly used to create applications and pipelines for real-time streaming data intake. These pipelines use event-based elements like message posting and subscribing to make the data accessible to the destination systems. There can never be two identical incidents in a Kafka story. One of the most often used data engineering solutions to address data ingestion issues is Apache Kafka.
With Kafka, each event is appended to the end of the log, just like it would be in a queue, a feature known as the "Message queue architecture" or log commit architecture.
Apache Nifi
NSA produced Apache Nifi, which was given to the Apache open-source software foundation in 2014. Nifi is a technology for managing data flow that distributes and processes data. It allows users to import data from different sources and output it to numerous destinations by utilizing directed graphs to form a data flow. Users may view the modification of the data at each stage of the data flow thanks to audit logging and visualizations.
AWS Kinesis
Real-time data processing over huge dispersed data streams is offered via AWS Kinesis. A data stream is a rapid data transport.
Kinesis works well with continuous, high-speed data that is in real-time, such as stock market data, application logs, and social network feeds like Twitter. When an application needs real-time measurements and data analytics, Kinesis is also used. The aggregate data is loaded into a database system to accomplish this. Using data ingested from application logs to see website user interaction or analyze real-time Twitter trends are two examples of use cases.
Conclusion
In conclusion, any data pipeline must include data ingestion, especially when working with large-scale data sources. Building an efficient data ingestion strategy can be done using the methods covered in this blog, such as batch processing, streaming analytics, and data integration tools. It's critical to select the best strategy depending on your organization's unique demands and the features of your sources of data. Whether you are working with big bulk data transfers or real-time data streams.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
