

Leveraging Matching Anything by Segmenting Anything (MASA) For Object Tracking

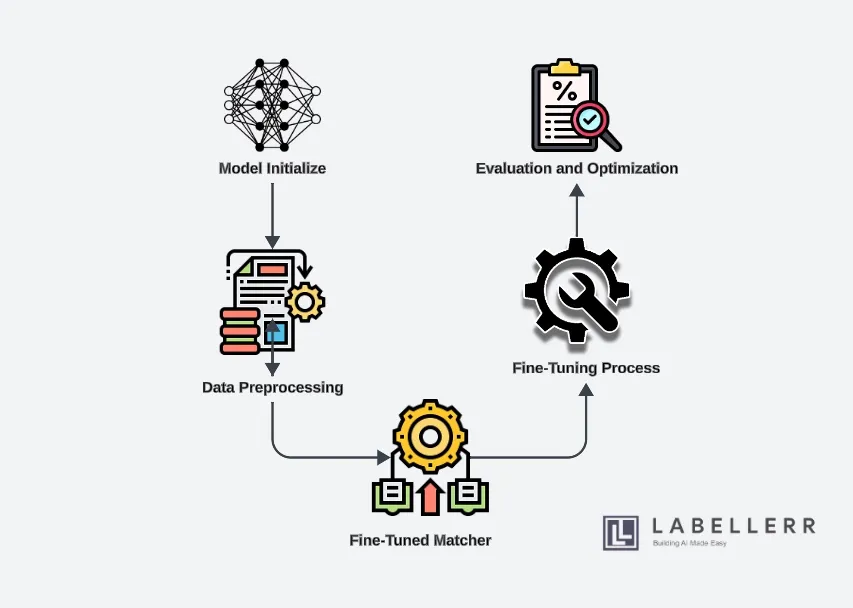
Table of Contents
- Overview of Multiple Object Tracking (MOT)
- Importance of MOT in Various Applications
- What is SAM?
- Benefits of using MASA
- How MASA works?
- Finetuning Process Leveraging MASA's Capability
- Applications of the Fine-Tuned Model
- Conclusion
- Frequently Asked Questions (FAQs)
Overview of Multiple Object Tracking (MOT)
Multiple Object Tracking (MOT) refers to the process of detecting and tracking multiple objects within a video or a sequence of frames. The primary objective of MOT is to consistently identify and follow various targets, ensuring that each object is correctly tracked across consecutive frames.

This involves not only recognizing the objects but also maintaining their identities over time, even when they overlap or temporarily disappear from the view. MOT is a complex task that requires robust algorithms capable of handling occlusions, varying object appearances, and changes in lighting conditions.
The field has evolved significantly over the years, with advancements in computer vision and machine learning driving the development of more accurate and efficient tracking methods.
Importance of MOT in Various Applications
The significance of Multiple Object Tracking extends across a wide range of applications, making it a critical area of research and development. In surveillance systems, MOT enables continuous monitoring of multiple individuals or vehicles, enhancing security and situational awareness.
In autonomous driving, it is essential for detecting and tracking pedestrians, other vehicles, and obstacles to ensure safe navigation. Sports analytics benefit from MOT by providing detailed tracking of players, facilitating performance analysis, and generating advanced statistics.
Additionally, MOT is used in robotics for navigation and interaction with dynamic environments, in video editing for special effects and scene composition, and in healthcare for monitoring patient activities and behaviors.
The ability to accurately track multiple objects simultaneously not only improves the functionality of these applications but also opens up new possibilities for innovation and automation.
What is SAM?
The Segment Anything Model (SAM) represents a significant advancement in the field of image segmentation and object tracking. SAM is designed to segment and identify objects within an image with remarkable precision.
Unlike traditional segmentation models that require extensive training on specific datasets, SAM leverages a versatile architecture capable of adapting to various segmentation tasks with minimal fine-tuning.
The model comprises three main components: the image encoder, the prompt encoder, and the mask decoder.

The image encoder processes the input image to extract detailed features, the prompt encoder interprets user-defined prompts to guide the segmentation process, and the mask decoder generates precise object masks based on the extracted features and prompts.
SAM's adaptability and precision make it an ideal candidate for extending into multiple object-tracking applications. By integrating SAM with additional tracking mechanisms, it becomes possible to develop a system that can not only segment objects within each frame but also maintain their identities across a sequence of frames.
Benefits of using MASA
This integration is the foundation of the Matching Anything by Segmenting Anything (MASA) pipeline, which enhances SAM's capabilities to support robust and accurate multiple object tracking.
Through innovative training techniques and data augmentation, the MASA pipeline aims to transform SAM into a powerful tool for tracking objects in diverse and dynamic environments, thereby addressing many of the challenges faced by traditional MOT methods.
Matching Anything (MASA) is an innovative technique designed to address the challenges of object tracking in dynamic and complex environments.
The primary objective of MASA is to ensure consistent and accurate identification of objects across multiple frames, thereby enhancing the robustness and reliability of the tracking process.
This technique leverages advanced matching algorithms that analyze and correlate object features between frames, making it possible to track objects seamlessly even when they undergo significant transformations or are partially occluded.
One of the key strengths of MASA lies in its ability to maintain the continuity of object identities across frames. In traditional object-tracking approaches, the model might struggle to consistently identify and track objects, especially when they move rapidly, change appearance, or overlap with other objects.
MASA overcomes these limitations by implementing sophisticated matching algorithms that can accurately associate the same object across different frames, thus reducing the likelihood of identity switches or tracking failures.
This makes MASA particularly valuable in scenarios where precise and reliable object tracking is critical, such as in surveillance, autonomous driving, and sports analytics.
How MASA works?
MASA operates by meticulously analyzing the features and spatial relationships of objects across consecutive frames. The process begins with the extraction of distinctive features from objects in the initial frame.

These features could include shape, color, texture, and other visual attributes that uniquely define each object. Once the features are extracted, MASA employs advanced matching algorithms to compare these features with those in subsequent frames.
By identifying the best matches based on feature similarity, the technique establishes correspondences between objects across frames.
In addition to feature analysis, MASA also considers the spatial relationships between objects. This involves understanding the relative positions and movements of objects within the scene.
By integrating both feature-based and spatial information, MASA creates a robust framework for tracking objects. This dual approach helps the model to accurately predict the movement and appearance of objects over time, even in the presence of occlusions or dynamic changes in the scene.
One of the significant advantages of MASA is its ability to handle complex scenes with multiple moving objects. In such scenarios, traditional tracking methods often encounter difficulties due to the high likelihood of occlusions and interactions between objects.
MASA addresses these challenges by maintaining a comprehensive understanding of the scene's spatial dynamics, allowing it to track objects reliably despite these complexities.
This capability is particularly beneficial in applications like crowd monitoring, wildlife observation, and urban traffic management, where accurate and continuous object tracking is essential.
Finetuning Process Leveraging MASA's Capability

1. Model Initialization
The first step in fine-tuning the Segment Anything Model (SAM) with Matching Anything (MASA) and Temporal-Spatial Prompt Learning (TSPL) involves setting up the development environment. This includes ensuring that all necessary libraries and dependencies are installed.
Once the environment is ready, load the pre-trained SAM model, which serves as the foundation for further fine-tuning. The pre-trained SAM model already has a strong capability for object segmentation, providing a solid starting point.
2. Data Preprocessing
Next, it's crucial to gather and prepare a diverse video dataset that will be used for training and fine-tuning the model.
This dataset should include various scenarios to ensure the model learns to handle different conditions effectively. Annotate the collected dataset meticulously, labeling all objects of interest across the video frames.
To enhance the dataset's robustness, apply data augmentation techniques such as flipping, rotation, and scaling. These techniques help the model generalize better by exposing it to different variations of the same objects.
3. Integration of MASA
In this step, the MASA framework is designed to be tailored to specific requirements. MASA's primary goal is to ensure consistent and accurate object matching across frames, improving the overall tracking performance.
Integrate MASA with the SAM model by modifying the architecture to incorporate advanced matching algorithms.
This integration allows SAM to leverage MASA's capabilities, enhancing its object-tracking performance, particularly in complex scenes with multiple objects and occlusions.
4. Fine-Tuning Process
Define a comprehensive training strategy outlining the objectives, learning rate, batch size, and other hyperparameters for fine-tuning. Train the fine-tuned model using the prepared dataset, ensuring that both MASA and TSPL components are utilized effectively.
Including TSPL helps the model maintain object consistency and accuracy across frames by incorporating temporal and spatial prompts. Monitor the training process closely to ensure the model is learning effectively and adjust the strategy as needed based on intermediate results.
5. Evaluation and Optimization
After the training process, evaluate the model's performance using appropriate metrics such as accuracy, precision, recall, and Intersection over Union (IoU).
These metrics provide insights into how well the model is performing in different aspects of object tracking and segmentation. Analyze the evaluation results to identify any areas where the model might be underperforming.
Based on this analysis, optimize the model by fine-tuning the hyperparameters, modifying the training strategy, or incorporating additional data augmentation techniques. The goal is to achieve the best possible performance before deploying the model in Labellerr's workflow.
Applications of the Fine-Tuned Model
The fine-tuned Segment Anything Model (SAM) enhanced with Matching Anything (MASA) and Temporal-Spatial Prompt Learning (TSPL) has numerous practical applications.
One prominent use case is in surveillance, where accurate and reliable object tracking is crucial for monitoring and security purposes. The enhanced model can seamlessly track individuals and objects across multiple camera feeds, improving the effectiveness of surveillance systems.

Another significant application is in autonomous driving. The fine-tuned SAM model can accurately track vehicles, pedestrians, and other objects on the road, contributing to safer and more reliable autonomous navigation.
By ensuring precise object detection and tracking, the model enhances the decision-making process of autonomous vehicles, reducing the risk of accidents and improving overall traffic safety.
Conclusion
Integrating Temporal-Spatial Prompt Learning (TSPL) and Matching Anything (MASA) with the Segment Anything Model (SAM) brings significant advancements in the field of object tracking.
This enhanced model provides more accurate annotations by leveraging the strengths of TSPL and MASA, which improve the consistency and reliability of object tracking across frames.
The fine-tuning process ensures that the model can handle complex and dynamic environments, reducing errors and increasing the overall quality of annotations.
For data annotation companies like Labellerr, these enhancements translate to increased efficiency, reduced manual effort, and improved productivity. The automated segmentation and tracking capabilities allow annotators to focus on more nuanced tasks, leading to higher-quality data and better-performing models.
Frequently Asked Questions (FAQs)
What is Multi-Modal Object Tracking?
Multi-modal object tracking involves using various data types, such as visual, spatial, and temporal information, to track objects accurately across frames. This approach is essential in dynamic environments where relying on a single type of data might not be sufficient for reliable object tracking.
What is the Segment Anything Model (SAM)?
The Segment Anything Model (SAM) is a versatile deep-learning model designed to segment objects in images and videos with high accuracy. It leverages advanced neural network architectures to identify and delineate objects, reducing the need for extensive manual annotation and increasing efficiency in data annotation processes.
What are the real-world applications of the fine-tuned SAM model?
The fine-tuned SAM model can be applied in various fields, including:
- Surveillance: Enhancing the accuracy of object tracking in security footage.
- Wildlife Monitoring: Improving the tracking and study of animal behavior in their natural habitats.
- Autonomous Driving: Enhancing the safety and reliability of autonomous navigation systems by accurately tracking objects on the road.
References

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
