

Matcher: Segment Anything with One Shot For Faster Annotation

Vision foundation models (VFMs) have become a cornerstone in the field of computer vision. These models, which are trained on large-scale datasets, have demonstrated remarkable capabilities in a wide range of visual perception tasks.
The primary advantage of VFMs lies in their ability to generalize across different domains, making them highly versatile for various applications such as image classification, object detection, and semantic segmentation.
Despite their impressive performance, VFMs face several significant challenges. One of the primary issues is the reliance on extensive annotated data for training.
Collecting and annotating such data is both time-consuming and costly, limiting the accessibility of these models for many research and industrial applications.
Additionally, VFMs often struggle with tasks that require fine-grained recognition or segmentation of objects in complex scenes. This limitation arises from the fact that these models tend to learn coarse-grained features that are effective for broad classification tasks but insufficient for detailed segmentation.
Furthermore, VFMs can exhibit performance degradation when applied to novel domains or environments that differ significantly from the training data, indicating a lack of robustness and adaptability.
Let's deep dive into it!
Table of Contents
- Introduction to Matcher
- Conceptual Framework of MATCHER
- Using MATCHER to Fine-tune SAM Model in Data Annotation Workflow
- Step-by-step Workflow for Fine-tuning SAM Model
- Applications of Fine-tuned MATCHER Model
- FAQs
Introduction to Matcher
Matcher is a novel framework designed to enable one-shot segmentation of objects using all-purpose feature matching. This approach significantly reduces the dependency on large annotated datasets by leveraging pre-trained vision foundation models (VFMs) in a more efficient and adaptable manner.
Matcher introduces a unique bidirectional matching strategy, a robust prompt sampler, and instance-level matching to facilitate detailed and accurate segmentation.
Conceptual Framework of MATCHER
Bidirectional Matching Strategy
The bidirectional matching strategy is central to Matcher’s functionality. This strategy involves the simultaneous consideration of both the reference and target images during the matching process.
By evaluating the correspondence in both directions—reference to target and target to reference—Matcher ensures a comprehensive understanding of the similarities and differences between the images.
This approach enhances the accuracy of object segmentation, particularly in complex scenes where fine-grained details are crucial.
Robust Prompt Sampler
The robust prompt sampler is designed to generate a diverse set of prompts that guide the segmentation process. These prompts can be categorized into part-level, instance-level, and global prompts.
Part-level prompts focus on specific regions of the image, instance-level prompts target entire objects, and global prompts encompass the overall image context. By using a variety of prompts, Matcher can effectively address different levels of granularity in object segmentation, ensuring precise and detailed results.
Instance-Level Matching
Instance-level matching in Matcher is achieved through the use of the Earth Mover's Distance (EMD) and specific metrics like purity and coverage. EMD measures the dissimilarity between two distributions, enabling Matcher to match instances across images accurately.

Purity and coverage metrics further refine this process by ensuring that the matched segments are both pure (homogeneous) and comprehensive (covering the entirety of the object). This combination of techniques allows Matcher to produce high-quality masks that accurately represent the objects in the images.
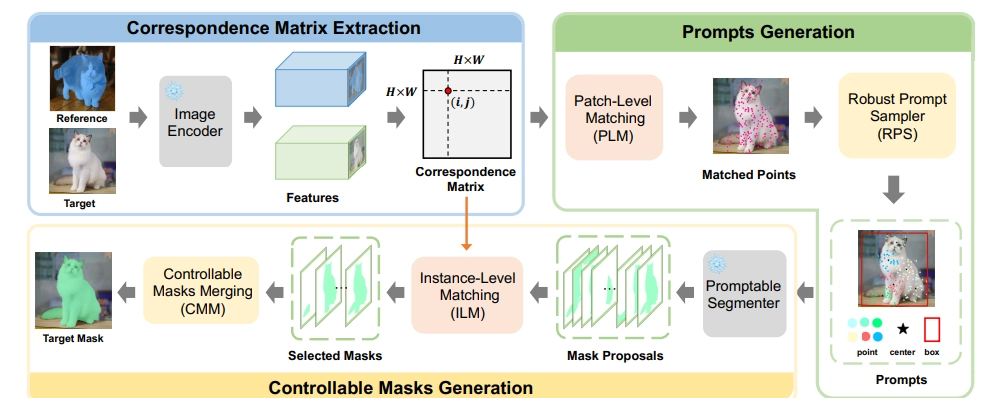
Correspondence Matrix Extraction
Feature Extraction for Reference and Target Images
Feature extraction is the first step in the correspondence matrix extraction process. Matcher uses pre-trained VFMs to extract features from both the reference and target images.
These features represent various visual characteristics of the images, such as edges, textures, and shapes. By leveraging the rich feature representations learned during pre-training, Matcher can effectively capture the similarities and differences between the reference and target images.
Calculation of the Correspondence Matrix
Once the features are extracted, Matcher calculates the correspondence matrix, which represents the degree of similarity between features in the reference and target images.
This matrix serves as the foundation for identifying corresponding regions between the images. By analyzing the correspondence matrix, Matcher can determine which parts of the reference image match with the target image, facilitating accurate segmentation.
Prompts Generation
Bidirectional Patch-Level Matching
In bidirectional patch-level matching, Matcher divides both the reference and target images into smaller patches. By comparing patches in both directions, Matcher can identify correspondences at a finer granularity.
This approach ensures that even small but significant details are captured during the matching process, enhancing the accuracy of the segmentation.
Robust Prompt Sampler
The robust prompt sampler generates prompts at three levels:
- Part-level prompts: These prompts focus on specific regions or parts of the image. They are useful for segmenting detailed features that may not be easily captured by larger prompts.
- Instance-level prompts: These prompts target entire objects within the image. They help in segmenting whole instances, ensuring that the model captures the complete object rather than just parts of it.
- Global prompts: These prompts encompass the overall context of the image. They provide a broader view, helping the model understand the general layout and context of the objects within the image.
By using these varied prompts, Matcher can address different segmentation needs, from fine-grained details to whole-object recognition.
Controllable Masks Generation
Instance-Level Matching
Instance-level matching in Matcher is refined using the Earth Mover's Distance (EMD), which measures the dissimilarity between the distributions of features in the reference and target images. This approach ensures that the matched instances are accurate and representative of the objects in the images.
- Earth Mover's Distance (EMD): EMD calculates the minimal cost required to transform one distribution into another. In the context of Matcher, it is used to measure the similarity between the feature distributions of the reference and target images, facilitating precise instance-level matching.
- Purity and coverage metrics: These metrics ensure that the matched segments are pure and comprehensive. Purity ensures that each segment is homogeneous, containing only one type of object or feature, while coverage ensures that the entire object is represented in the matched segment.
Merging High-Quality Masks
After instance-level matching, Matcher merges the high-quality masks generated from the matched instances.
This merging process combines the strengths of the individual masks, resulting in a final segmentation mask that is both accurate and detailed.
By leveraging the robustness of the bidirectional matching strategy and the diversity of the robust prompt sampler, Matcher produces segmentation masks that are of high quality and suitable for a wide range of applications.
Using MATCHER to Fine-tune SAM Model in Data Annotation Workflow
Labellerr is a leading data annotation company specializing in providing high-quality annotated data for various machine learning applications. The company's workflow involves the systematic processing and annotation of data, ensuring accuracy and consistency across different datasets.
Labellerr utilizes advanced tools and frameworks to enhance the efficiency of its annotation processes, catering to a diverse range of industries including autonomous driving, healthcare, and surveillance.
The integration of innovative models like Matcher into Labellerr’s workflow can significantly improve the quality and speed of data annotation, particularly for tasks requiring detailed and accurate segmentation.
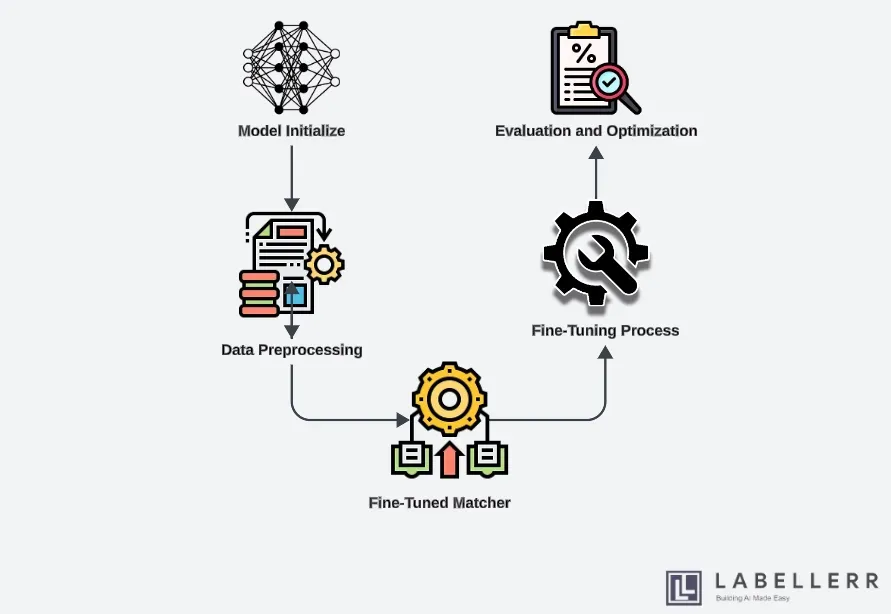
Step-by-step Workflow for Fine-tuning SAM Model
Model Initialization
The first step in fine-tuning the SAM (Segment Anything Model) using Matcher is model initialization. This process involves setting up the pre-trained SAM model as the base for further enhancement.
The SAM model, pre-trained on large-scale datasets, provides a strong foundation with its extensive feature representations and segmentation capabilities.
Initializing the SAM Model
To initialize the SAM model, Labellerr loads the pre-trained weights and configurations into their computational environment. This involves importing necessary libraries, defining the model architecture, and loading the pre-trained weights.
The initialized SAM model serves as the starting point for incorporating Matcher’s enhancements, setting the stage for more precise and efficient segmentation tasks.
Data Preprocessing
Data preprocessing is a crucial step in preparing the dataset for training. This step involves various operations such as data cleaning, normalization, augmentation, and splitting the dataset into training, validation, and testing sets.
Proper preprocessing ensures that the data fed into the model is of high quality and suitable for training.
Preparing Data for Training
Labellerr employs a series of preprocessing techniques to prepare the data for fine-tuning the SAM model. Initially, any noisy or irrelevant data is filtered out to ensure a clean dataset.
Next, the images are normalized to standardize the pixel values, which helps in achieving consistent model performance. Data augmentation techniques, such as rotation, flipping, and scaling, are applied to increase the diversity of the training data, thereby enhancing the model’s generalization capabilities.
Finally, the dataset is split into training, validation, and testing sets to facilitate effective model evaluation and optimization.
Fine-tuning Process
The fine-tuning process involves applying Matcher’s enhancements to the SAM model, enabling it to perform more precise and detailed segmentation tasks.
Matcher’s bidirectional matching strategy and robust prompt sampler are integrated into the SAM model to refine its segmentation capabilities.
Applying Matcher Enhancements
To apply Matcher enhancements, the SAM model is equipped with a bidirectional matching strategy, which considers both reference and target images during the matching process.
This strategy improves the model’s ability to accurately segment objects by leveraging comprehensive feature correspondences. The robust prompt sampler generates various prompts—part-level, instance-level, and global prompts—that guide the segmentation process at different levels of granularity.
These prompts ensure that the model can handle both fine-grained and coarse-grained segmentation tasks effectively. Additionally, instance-level matching using Earth Mover's Distance (EMD) and purity and coverage metrics further refine the segmentation masks, ensuring high accuracy and consistency.
During the fine-tuning process, Labellerr continuously monitors the model’s performance on the validation set, making necessary adjustments to the learning rate, batch size, and other hyperparameters to optimize the training process.
The integration of Matcher’s components allows the SAM model to achieve superior segmentation performance, significantly enhancing Labellerr’s data annotation capabilities.
Applications of Fine-tuned MATCHER Model
The fine-tuned MATCHER model has a wide range of applications across various industries due to its enhanced ability to perform detailed and accurate segmentation tasks.
By integrating advanced feature matching and segmentation techniques, MATCHER significantly improves the performance and efficiency of object detection and recognition systems. Here are some of the key applications of the fine-tuned MATCHER model:
Improved Detection in Surveillance Systems
In the realm of surveillance systems, accurate and reliable object detection is crucial for ensuring security and monitoring activities. The fine-tuned MATCHER model enhances surveillance systems by providing precise detection and segmentation of objects and individuals in real-time video feeds.

This capability is particularly useful in crowded or complex environments where traditional detection models may struggle. MATCHER’s bidirectional matching strategy and robust prompt sampler enable it to distinguish between different objects and track their movements accurately.
This improvement leads to better identification of potential security threats, unauthorized activities, and other anomalies, thereby enhancing overall safety and security.
Enhanced Wildlife Monitoring
Wildlife monitoring involves tracking and observing animals in their natural habitats to study their behavior, population, and health.

The fine-tuned MATCHER model significantly improves wildlife monitoring by providing detailed segmentation and identification of animals in diverse environments. Traditional models often face challenges in distinguishing animals from their surroundings, especially in dense foliage or under low-light conditions.
MATCHER’s advanced feature matching techniques allow it to accurately segment animals, even in complex backgrounds. This capability aids researchers in collecting precise data on animal populations, behaviors, and movements, contributing to better wildlife conservation and management efforts.
Precision Agriculture
Precision agriculture relies on accurate data about crops, soil, and environmental conditions to optimize farming practices and increase yields. The fine-tuned MATCHER model enhances precision agriculture by providing detailed segmentation of crops, weeds, and other elements in agricultural fields.
By accurately distinguishing between crops and weeds, MATCHER enables automated weeding systems to target and eliminate weeds more effectively, reducing the need for chemical herbicides.
Additionally, the model can segment different parts of plants, such as leaves, stems, and fruits, facilitating more precise monitoring of crop health and growth. This level of detail helps farmers make informed decisions about irrigation, fertilization, and pest control, ultimately improving productivity and sustainability.
Autonomous Driving
Autonomous driving systems rely on accurate perception of the surrounding environment to navigate safely and efficiently. The fine-tuned MATCHER model enhances autonomous driving by providing detailed segmentation of road elements, vehicles, pedestrians, and other objects.

This capability allows the autonomous system to accurately identify and track objects in various driving conditions, including urban environments, highways, and rural roads.
MATCHER’s ability to handle complex scenes and provide fine-grained segmentation helps improve the system’s understanding of the environment, leading to better decision-making and safer navigation.
Enhanced object detection and segmentation also contribute to improved performance of advanced driver-assistance systems (ADAS), such as lane-keeping assistance, collision avoidance, and adaptive cruise control.
FAQs
What are Vision Foundation Models (VFMs) and how do they work?
Vision Foundation Models (VFMs) are large-scale pre-trained models designed to handle a variety of visual perception tasks such as image classification, object detection, and semantic segmentation. These models are trained on extensive datasets to learn generalizable visual features that can be applied across different domains. VFMs work by extracting and processing visual features from images to recognize and segment objects based on patterns learned during training.
What challenges do VFMs face despite their impressive performance?
Despite their strengths, VFMs encounter several challenges:
- Data Dependency: They require large amounts of annotated data for training, which is costly and time-consuming to collect.
- Fine-Grained Recognition: VFMs often struggle with tasks needing fine-grained recognition or segmentation in complex scenes due to their tendency to learn coarse-grained features.
- Domain Adaptability: VFMs may experience performance degradation when applied to new domains or environments significantly different from their training data, indicating a lack of robustness and adaptability.
How does the Matcher framework improve the segmentation capabilities of VFMs?
Matcher enhances the segmentation capabilities of VFMs through:
- Bidirectional Matching Strategy: It considers both reference and target images simultaneously, ensuring comprehensive feature correspondence for accurate segmentation.
- Robust Prompt Sampler: Generates diverse prompts (part-level, instance-level, and global) to guide segmentation at different levels of granularity.
- Instance-Level Matching: Utilizes Earth Mover's Distance (EMD) and metrics like purity and coverage to ensure precise and detailed segmentation of objects.
References

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
