

Unlocking Multimodal AI: LLaVA and LLaVA-1.5's Evolution in Language and Vision Fusion
LLaVA merges language and vision for advanced AI comprehension, challenging GPT-4V with chat capabilities and Science QA. Discover LLaVA-1.5's enhanced multimodal performance with a refined vision-language connector.

In the realm of artificial intelligence, Microsoft's recent introduction of LLaVA represents a groundbreaking leap into multimodal models. LLaVA, an abbreviation for Large Language and Vision Assistant, is a revolutionary solution that merges a vision encoder with Vicuna.
This amalgamation sets a new standard for AI comprehension, particularly in understanding both visual and language components. Surpassing the capabilities of OpenAI's multimodal GPT-4, LLaVA excels in chat capabilities and significantly raises the bar for Science QA accuracy.
The amalgamation of natural language and computer vision has unlocked vast potential in the field of artificial intelligence. While fine-tuning techniques have significantly bolstered large language models' (LLMs) performance in adapting to various tasks, their application to multimodal models remains relatively unexplored.
The introduction of "Visual Instruction Tuning" in a research paper lays the groundwork for a novel approach. LLaVA, born from this innovative research, ushers in a new paradigm by seamlessly integrating textual and visual components to comprehend instructions effectively.
Table of Contents
- Understanding Visual Instruction Tuning
- LLaVA vs. LLaVA-1.5
- The Core Infrastructure: CLIP’s Visual Encoder Meshed with LLaMA’s Linguistic Decoder
- Principle Features of LLaVA
- Comparison: GPT-4V vs LLaVA-1.5
- Testing LLaVa’s Capabilities
- Recent Developments
- Key Takeaways
Understanding Visual Instruction Tuning
Visual Instruction Tuning stands as a technique for fine-tuning large language models to interpret and execute instructions reliant on visual cues. This technique establishes a critical link between language and vision, enabling AI systems to comprehend and act upon human instructions encompassing both modalities.
Imagine tasking a machine learning model to describe an image, execute actions in a virtual environment, or respond to questions based on a scene in a photograph. Visual instruction tuning equips models with the ability to effectively perform these diverse tasks.

LLaVA vs. LLaVA-1.5
LLaVA
Initially trained on a relatively small dataset, LLaVA showcases exceptional abilities in comprehending images and responding to associated questions. Its proficiency in tasks that demand deep visual comprehension and instruction-following is particularly impressive.
Despite its training on a limited dataset, LLaVA exhibits behaviors similar to sophisticated multimodal models like GPT-4, even excelling with previously unseen images and instructions.
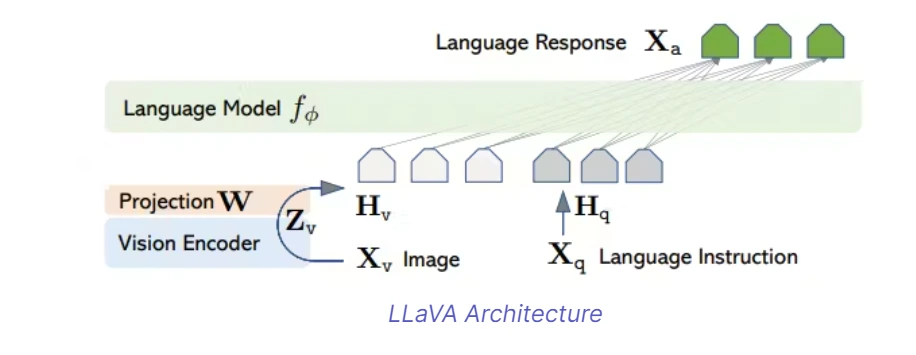
LLaVA Architecture
LLaVA utilizes the renowned LLaMA model for language tasks and relies on the CLIP visual encoder ViT-L/14 for visual comprehension. This integration effectively bridges the gap between textual and visual components, enabling seamless interactions.
LLaVA-1.5
The upgraded iteration, LLaVA-1.5, introduces notable improvements. It incorporates an MLP (Multi-Layer Perceptron) vision-language connector, significantly enhancing its multimodal capabilities. Additionally, the integration of academic task-oriented data amplifies its performance across various applications, encompassing text recognition and precise localization of fine-grained visual details.
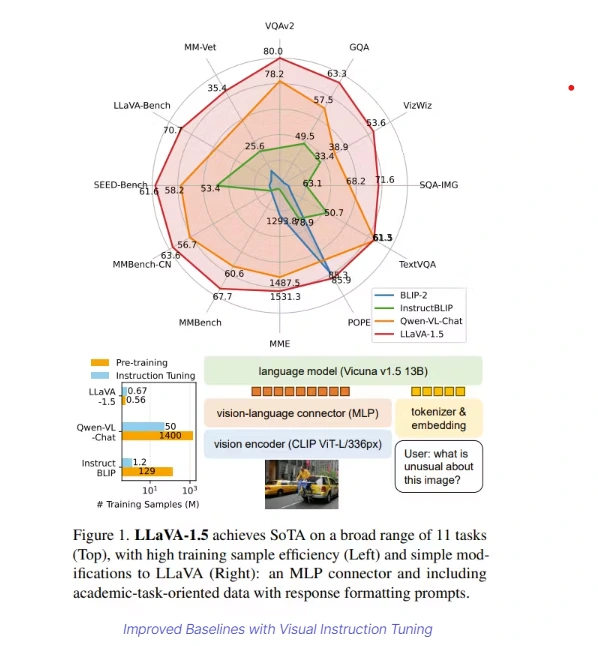
Comparative Analysis with State-of-the-Art (SOTA) Models
LLaVA's performance closely rivals state-of-the-art models, especially in ScienceQA tasks. Its exceptional proficiency in handling out-of-domain questions underscores its strength in comprehending visual content and delivering accurate responses. Notably, LLaVA outshines other models in conversational contexts, showcasing robust reasoning capabilities.
The Core Infrastructure: CLIP’s Visual Encoder Meshed with LLaMA’s Linguistic Decoder
LLaVA represents an innovative fusion of visual and linguistic intelligence, combining a visionary encoder with Vicuna, an advanced language model. This groundbreaking amalgamation empowers LLaVA to understand visual data and generate rich content that encompasses both visual and linguistic dimensions.
One key aspect of LLaVA's approach involves using auto-generated data aligned with specific instructions, enhancing its ability to comprehend and produce content in diverse multimodal environments.
The foundational structure of LLaVA rests on merging a CLIP visual encoder with a LLaMA language decoder. LLaMA, a sophisticated language model developed by Meta, is highly regarded for its exceptional text comprehension capabilities.
Tailored for tasks requiring image analysis, LLaMA's decoder processes a combination of image and textual tokens to produce the final output. LLaVA's utilization of language-only models to create pairs of language and image instructions further strengthens its ability to comply with multimodal instructions.
LLaVA’s Open-Source Nature and Consistent Updates
LLaVA isn't a static creation; it evolves continuously. Its open-source framework encourages contributions from a diverse community of AI developers and specialists. Collaborative efforts have propelled LLaVA to achieve remarkable accuracy in various tasks, such as answering science-based questions.
Additionally, the model has shown outstanding performance when faced with previously unseen images and instructions.
With its unique blend of capabilities and an open-source structure facilitating ongoing improvements, LLaVA represents a significant advancement in the realm of artificial intelligence and the generation of multimodal content.
Principle Features of LLaVA
(i) LLaVA utilizes text-based algorithms to generate paired language and image instructions, enhancing its adaptability in environments necessitating both data types.
(ii) It integrates a visual processing unit with an advanced language algorithm, enabling the handling and creation of textual and visual content.
(iii) LLaVA allows tailored adjustments to address specific challenges, like responding to science-related queries, and enhancing its performance in specialized fields.
(iv) The tuning data for visual instructions from GPT-4 and the fundamental LLaVA model along with its code are openly available, fostering continuous research and collaboration in multimodal AI.
By emphasizing these fundamental aspects, LLaVA strives to push the boundaries of possibilities at the intersection of language and vision in artificial intelligence.
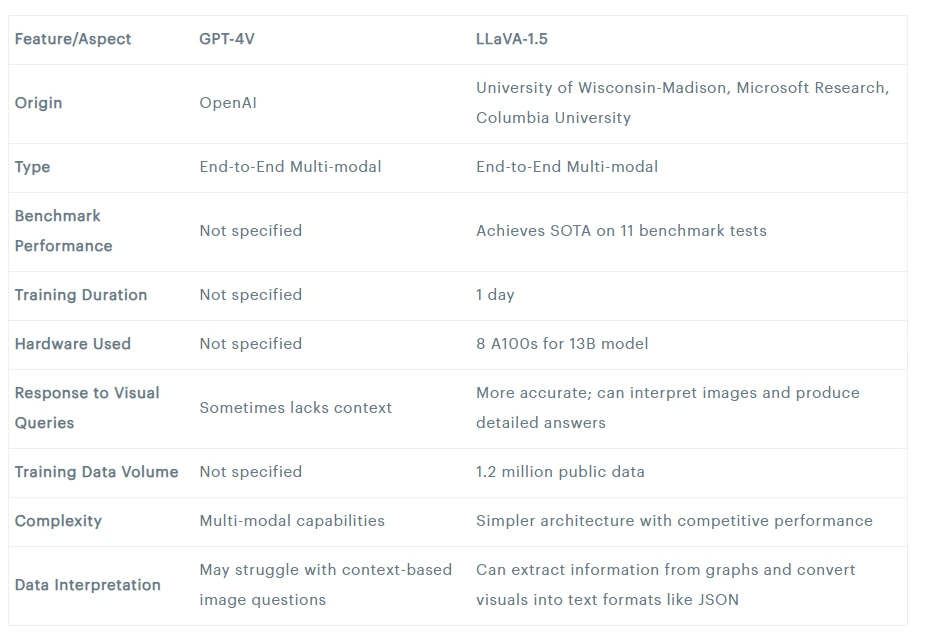
Comparison: GPT-4V vs LLaVA-1.5

Testing LLaVa’s Capabilities
Evaluation Round #1: Object Identification Without Special Training
A fundamental test for assessing a new multi-modal model involves determining its ability to identify objects in photos without prior specific training, known as unsupervised object localization.
In our initial test with LLaVA-1.5, we tasked it with identifying a dog in one photo and a straw in another. The goal was to evaluate the model's capacity to recognize these objects without tailored preparation. Impressively, LLaVA-1.5 successfully pinpointed the dog and the straw in their respective images. This showcases the model's adaptability in handling diverse data types, such as visual and textual inputs.
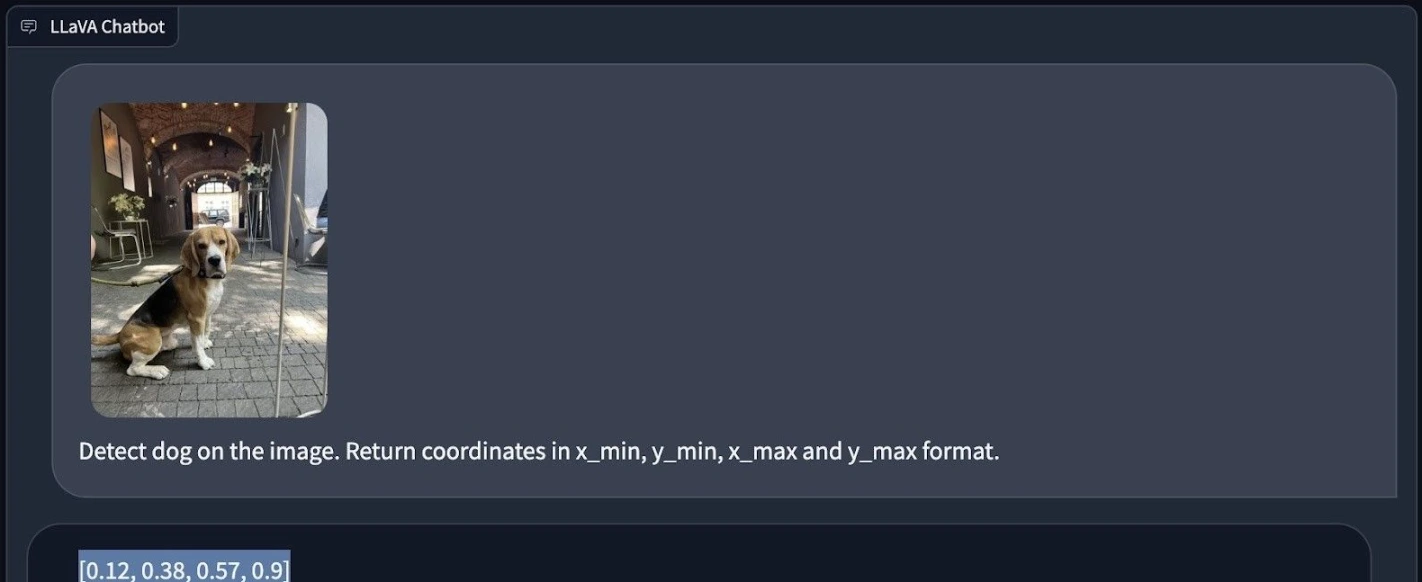
Test 1
We employed LLaVA-1.5 to locate a dog in a picture and requested the model to provide the dog's location using x_min, y_min, x_max, and y_max coordinates.
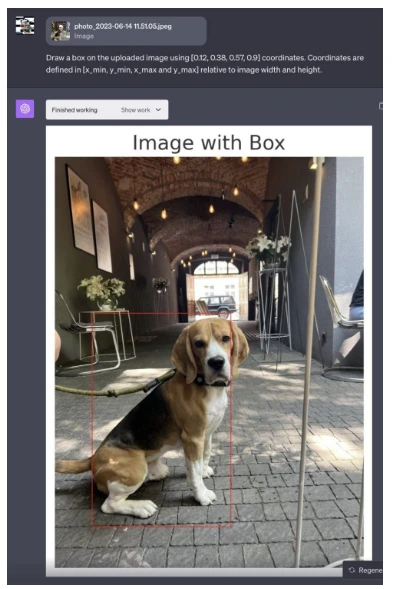
Test 2
Through ChatGPT’s Code Interpreter, a bounding box was generated around the dog's coordinates for visual representation.
Test 3
LLaVA-1.5 was utilized to identify a straw within a visual frame.
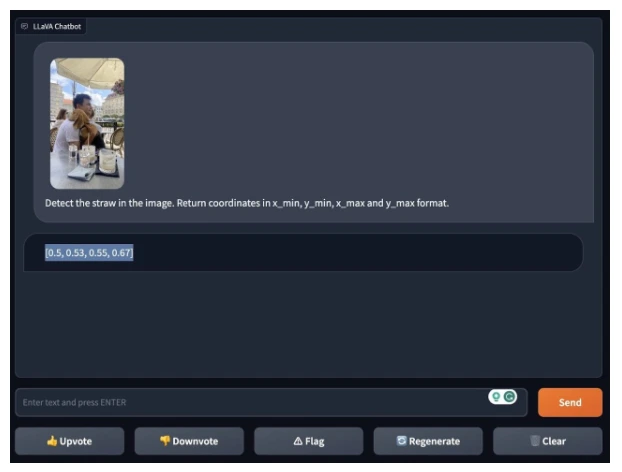
Test 4
Using LLaVA-1.5's identified positional data for the straw, ChatGPT’s Code Interpreter rendered these coordinates on an image.
Evaluation Round #2: Image Interpretation Analysis
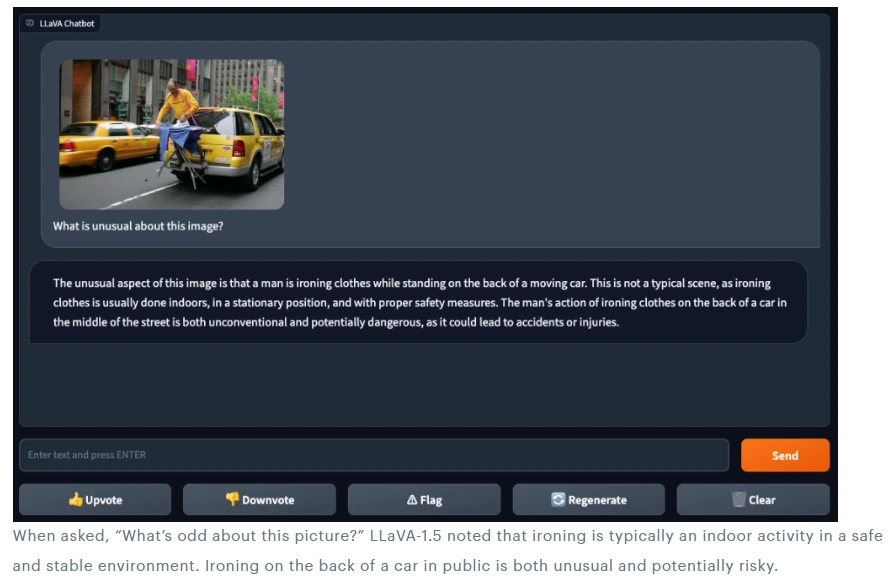
Presenting LLaVA-1.5 with an image of someone ironing clothes on an ironing board attached to the back of a yellow car in a city setting—a peculiar scenario.
Test 5
When questioned about what's unusual in the picture, LLaVA-1.5 noted the unconventional nature of ironing in a public and potentially risky setting, typically considered a safe, indoor activity.
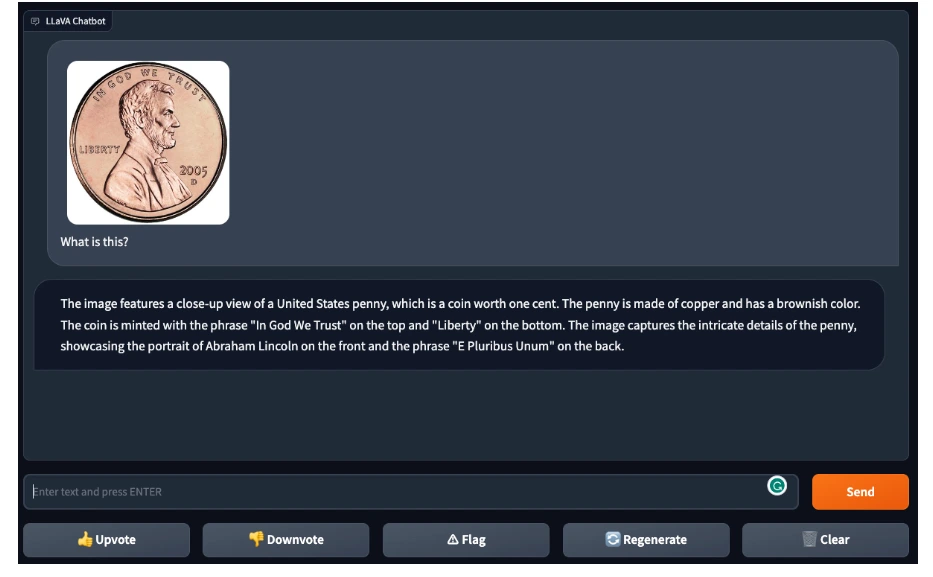
Continuing, LLaVA-1.5 accurately identified and described a U.S. penny when presented with an image of the coin.
Test 6
However, when confronted with a photo showing four coins and asked about the total value, LLaVA-1.5 could discern the number of coins but couldn't accurately determine their cumulative value, revealing limitations in handling more complex visual scenarios.
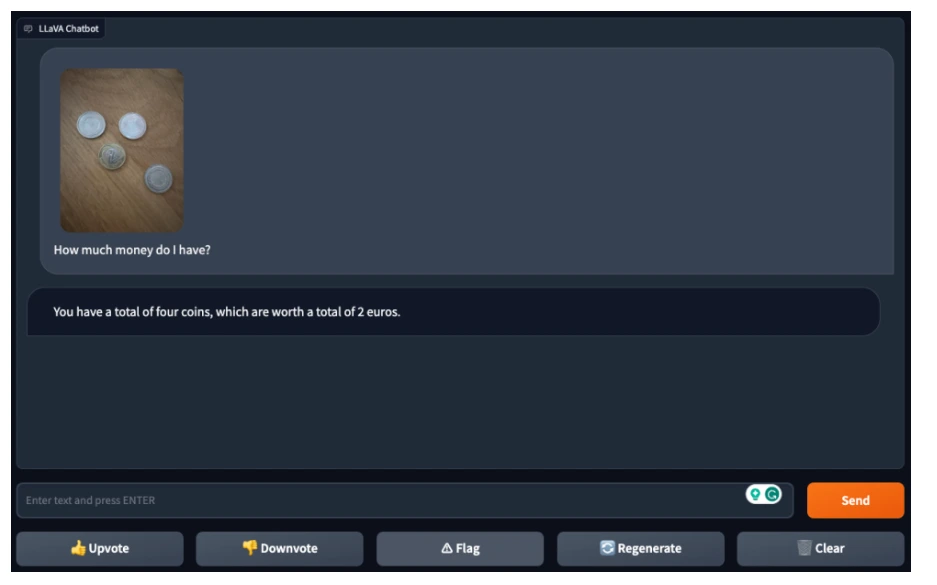
Test 7
Evaluation Round 3: Text Recognition from Images
Assessing LLaVA-1.5's Optical Character Recognition (OCR) capabilities included a comparison with another model, GPT-4V. When presented with an image of readable text from a website, GPT-4V accurately read all the text, while LLaVA-1.5 encountered errors and got stuck on the word “repeat.”
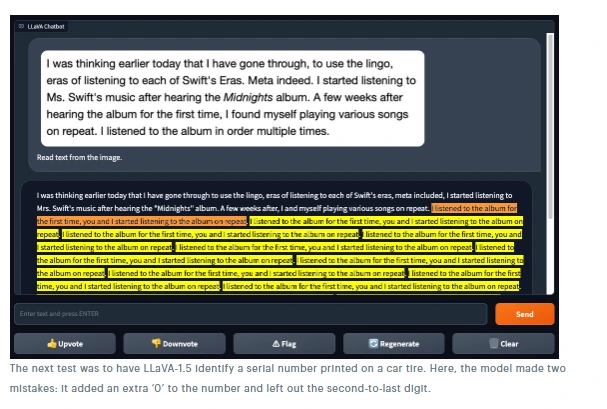
Test 8
In identifying a serial number on a car tire, LLaVA-1.5 made two mistakes: adding an extra digit and omitting the second-to-last digit, indicating room for improvement.
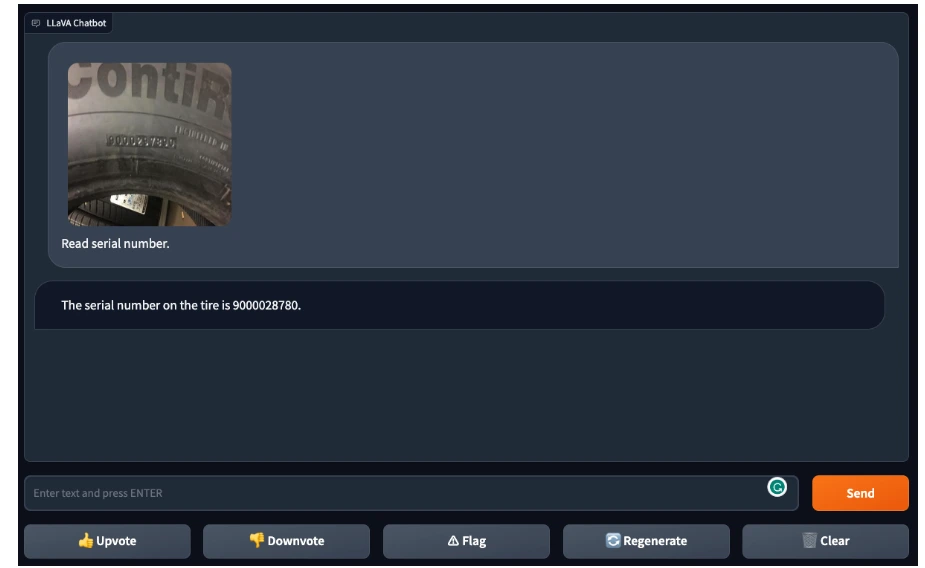
Overall, while LLaVA-1.5 displays promise in text recognition from images, it encountered errors and difficulties, necessitating further improvements to enhance reliability.
LLaVA-1.5 is an impressive new multimodal software capable of answering image-based questions, such as identifying anomalies in pictures or discerning coin values. However, it faces challenges in OCR tasks where models like GPT-4V perform better, as observed in reading serial numbers. Notably, each model, including Google’s Bard and Microsoft’s Bing Chat, showcases distinct strengths and weaknesses in tasks involving object identification, image-based question answering, and OCR.
Recent Developments
Microsoft's strides in AI innovation continue with recent developments like LLaVA-Med, a groundbreaking multimodal assistant tailored for the healthcare sector. Remarkably, LLaVA-Med showcases exceptional capabilities in understanding biomedical images, providing valuable support to biomedical practitioners in their research endeavors. Moreover, LLaVA-Interactive demonstrates the boundless versatility inherent in multimodal models, highlighting their interactive and generative capabilities beyond language interaction.
Key Takeaways
(i) LLaVA Challenges GPT-4: Microsoft's LLaVA emerges as a formidable competitor to GPT-4, excelling in chat capabilities and Science QA.
(ii) Visual Instruction Tuning Drives AI Advancements: LLaVA's innovative approach empowers AI to comprehend and execute complex instructions involving both text and images.
(iii) LLaVA-1.5 Enhancements: The upgraded version, LLaVA-1.5, with its enhanced connectors and datasets, further boosts interaction between language and visual content.
(iv) Bridging Language and Vision: LLaVA's architecture seamlessly merges language tasks and visual understanding, setting new standards in multimodal interactions.
The evolution of LLaVA and its iterations signifies a remarkable fusion of language and vision that paves the way for new possibilities in AI development. As we delve into this fascinating journey, the exploration of larger datasets and integration with powerful vision models, among other avenues, promises continued advancements in the exciting field of multimodal AI.
Frequently Asked Questions
1. What is LLaVA & how does it work?
LLaVA is an innovative comprehensive multimodal model that integrates a vision encoder and Vicuna to deliver broad visual and language comprehension. It excels in chat functionalities reminiscent of the multimodal GPT-4, establishing a new benchmark in Science QA accuracy.
2. Can LLaVA integrate with other computer vision models?
Expanding its integration with additional computer vision models, LLaVA has exhibited encouraging outcomes, occasionally rivaling the capabilities of the latest ChatGPT. To progress even further, a compelling direction involves incorporating robust vision models like SAM.
3. Is LLaVA a good multimodal model?
The outcomes derived from LLaVA 1.5, particularly the 13B model, are remarkable. Across the 12 most widely recognized multimodal benchmarks, LLaVA 1.5 has set a new standard of excellence, achieving state-of-the-art (SOTA) status in 11 out of the 12, surpassing other prominent open-source models by a significant margin.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
