

Insurance Lead Prediction Using Machine Learning


Introduction
In today's fast-paced world, the insurance industry is continually seeking innovative ways to enhance its operations, boost sales, and improve customer satisfaction. One area that has gained significant attention in recent years is the utilization of machine learning (ML) and natural language processing (NLP) techniques for lead prediction.
By harnessing the power of data and advanced algorithms, insurance companies can gain valuable insights into customer behavior, preferences, and likelihood to purchase, thus streamlining their sales processes and maximizing revenue.
The insurance industry faces a constant challenge: identifying and reaching potential customers with the right products at the right time.
Traditionally, this has involved broad marketing campaigns and a hit-or-miss approach. However, the rise of machine learning (ML) and natural language processing (NLP) is revolutionizing the way insurance companies find and convert leads.
The Importance of Machine Learning in Lead Prediction
Lead prediction plays an important role in the success of insurance sales strategies. Identifying potential customers who are most likely to purchase a policy allows agents to focus their efforts efficiently, resulting in higher conversion rates and increased revenue.
However, traditional lead scoring methods often rely on manual assessment or simplistic criteria, leading to inefficiencies and missed opportunities.
ML models present a major shift in lead prediction by enabling insurance companies to analyze vast amounts of data, including customer demographics, browsing history, social media interactions, and more.
By extracting meaningful patterns and insights from unstructured data, ML models can accurately predict which leads are most likely to convert, empowering agents to prioritize their outreach efforts and tailor their sales pitches accordingly.
Machine learning algorithms, particularly supervised learning techniques such as classification and regression, lie at the heart of lead prediction models.
These algorithms learn from historical data to identify patterns and relationships that correlate with successful sales outcomes.
By training on labeled datasets containing information about past leads and their conversion status, ML models can generalize this knowledge to make predictions on new leads.
Let’s create a health insurance lead prediction using machine learning. For this tutorial, we will be using the Kaggle dataset Insurance Lead Prediction Raw Data
1.Let’s import the required libraries:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt2. Now let’s read the dataset and see the columns present in the dataset.
data_Health = pd.read_csv('Health Insurance Lead Prediction Raw Data.csv')
data_Health.info()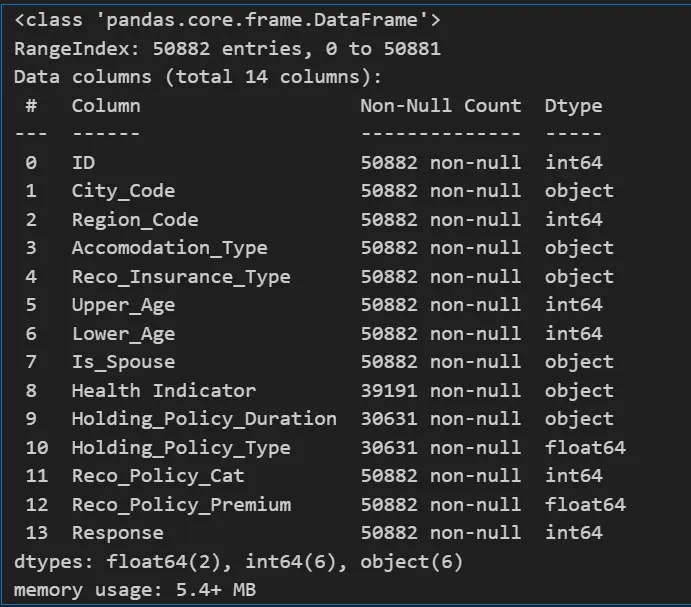
As we can see from the above output we have 13 columns which contain both numerical and categorical columns.
3. Now Let’s check for Null values
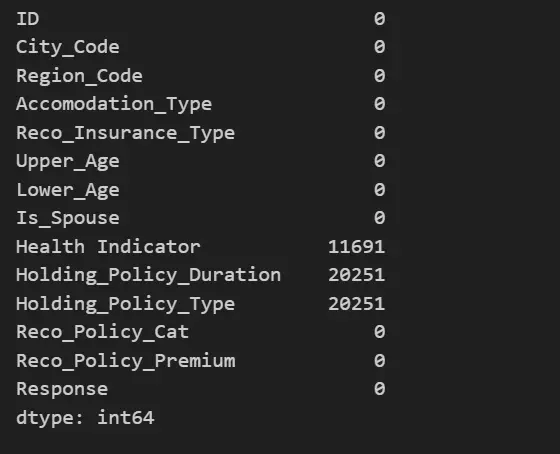
We can see that we have null values present in three columns Health Indicator, Holding_Policy_Duration ,Holding_Policy_Duration , and Holding_Policy_Type. We will deal with all three columns separately.
4. Let’s begin with ‘Health Indicator’ and check its value counts to see the data present in the column.
data_Health['Health Indicator'].value_counts()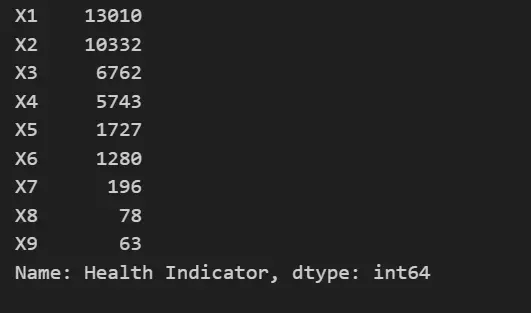
The value_counts() function returns a Series that contains counts of unique values. It returns an object that will be in descending order, so that its first element will be the most frequently- occurring element.
5. Now, we will deal with the null values present in the ‘Health Indicator’ column by imputing all the missing values with the most common values present in that column.
data_Health['Health Indicator'].fillna (data_Health['Health Indicator'].mode()[0], inplace=True)
data_Health['Health Indicator'].isnull().sum()
6. Now we will deal with 'Holding_Policy_Duration' column by converting it to numerical format and imputing all the missing values with the median of the column.
data_Health['Holding_Policy_Duration'].replace(('14+'), (14.0), inplace=True)
data_Health['Holding_Policy_Duration'] =
data_Health['Holding_Policy_Duration'].astype('float32')
data_Health['Holding_Policy_Duration'].fillna(data_Health['Holding_Policy_Duration']
.median(), inplace=True)
data_Health['Holding_Policy_Duration'].isnull().sum()7. Now we will deal with ‘Holding_Policy_Type’ column similarly we will replace all the missing values with the most occurring element in the column.
data_Health['Holding_Policy_Type'].value_counts()
data_Health['Holding_Policy_Type'].fillna(data_Health['Holding_Policy_Type']
.mode()[0], inplace=True)
data_Health['Holding_Policy_Type'].isnull().sum()8. Now let’s check over Null values
data_Health.isnull().sum()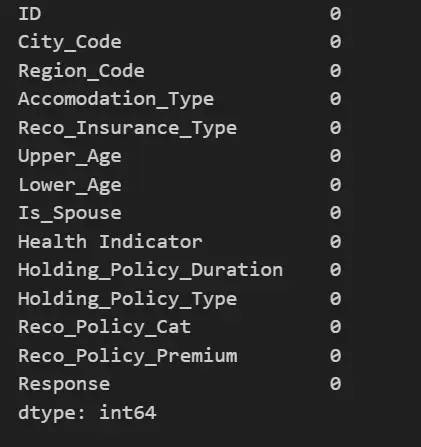
9. Let’s create a correlation matrix to see the correlation between all the features present.
plt.figure(figsize=(10, 8))
corr = data_Health.corr()
sns.heatmap(corr, annot=True, linewidths=0.7, cmap='Greens')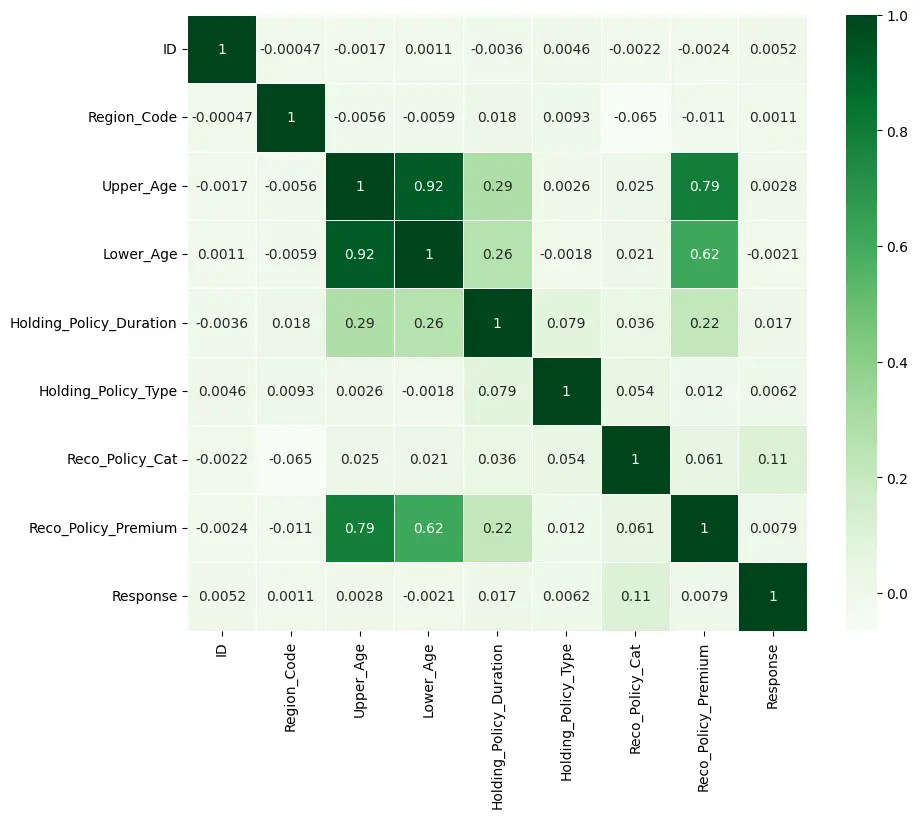
10. Certain features are dropped ('ID', 'Lower_Age') as they might not contribute significantly to the prediction task.
data_Health.drop(['ID', 'Lower_Age'], axis=1, inplace=True)
11. 'Health Indicator' and 'City_Code' are transformed to group specific categories for better representation.
data_Health['Health Indicator'].replace(['X1', 'X2', 'X3', 'X4', 'X5', 'X6', 'X7', 'X8', 'X9'],
[0, 1, 2, 3, 4, 4, 4, 4, 4], inplace=True)
data_Health['City_Code'].replace(['C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8',
'C9', 'C10', 'C11', 'C12', 'C13', 'C14', 'C15', 'C16', 'C17', 'C18', 'C19', 'C20',
'C21', 'C22', 'C23', 'C24', 'C25','C26', 'C27', 'C28', 'C29', 'C30', 'C31', 'C32',
'C33', 'C34', 'C35', 'C36'], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3], inplace=True)
data_Health['Is_Spouse'].replace(['Yes', 'No'], [1, 0], inplace=True)
data_Health['Reco_Insurance_Type'].replace(['Individual', 'Joint'],
[1, 0], inplace=True)
data_Health['Accomodation_Type'].replace(['Owned', 'Rented'],
[0, 1], inplace=True)
12. We will use X as independent variables or features in dataset and y represent as target variable.
X = data_Health.drop(['Response'], axis=1)
y = data_Health['Response']
13. Now we will be using StandardScaler library to ensure all features contribute equally to the learning process regardless of the original scale.
We will also be using SMOTE to address the issue of imbalance as it problematic for machine learning algorithms, especially those relying on classification tasks.
scaler = StandardScaler()
X_scale = scaler.fit_transform(X)
sm = SMOTE(random_state=0)
X_smote, Y_smote = sm.fit_resample(X_scale, y)14. Now Let’s build and train our ML model using a random forest classifier and prints its classification report.
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
model = RandomForestClassifier(n_estimators=500, criterion='entropy', max_depth=30,
max_features=x_train.shape[1])
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(classification_report(y_test, y_pred))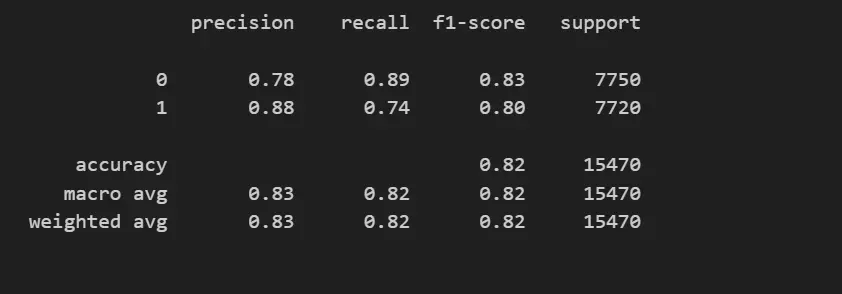
Challenges
While the potential of machine learning for insurance lead prediction is undeniable, implementing these technologies comes with its own set of challenges:
1) Data Quality and Availability
Building accurate models requires vast amounts of high-quality data, including customer demographics, past purchases, and claim history. This data needs to be clean, consistent, and free from biases to ensure reliable predictions.
2) Model interpretability and Explainability
Understanding how ML models arrive at their predictions is crucial for building trust and ensuring compliance. However, these models can be complex, making it difficult to explain their reasoning to human stakeholders.
3) Domain-Specific Challenges
Developing effective models requires domain-specific expertise in insurance, including an understanding of industry terminology, regulations, and customer behaviors. Integrating domain knowledge into model development and feature engineering is essential for building accurate and relevant predictive models.
4) Ethical Considerations and Regulatory Concerns
Utilizing personal information requires careful consideration of ethical and privacy concerns. Additionally, navigating the constantly evolving regulatory landscape surrounding AI and data usage adds another layer of complexity.
Conclusion
In conclusion, by combining the power of ML and NLP, insurance companies can gain a deeper understanding of potential customers, predict their insurance needs, and personalize their approach to lead generation.
This not only leads to increased conversion rates and improved customer experiences, but also fosters a more data-driven and effective insurance industry as a whole. As these technologies continue to evolve, their impact on lead prediction and insurance sales is ready to undergo even greater transformation.
Frequently Asked Questions
Q1) What is Insurance Lead Prediction?
Insurance Lead Prediction refers to the process of using machine learning algorithms to analyze data and predict the likelihood of a lead or prospect converting into a policyholder or customer for an insurance company. It helps insurers prioritize leads with the highest probability of conversion, thus optimizing marketing and sales efforts.
Q2) How does Machine Learning contribute to Insurance Lead Prediction?
Machine Learning algorithms analyze historical data such as customer demographics, behaviors, and interactions to identify patterns and trends. By training on this data, ML models can make predictions about the probability of a lead converting into a customer, allowing insurers to focus their resources more effectively.

Simplify Your Data Annotation Workflow With Proven Strategies
Download the Free Guide