

Evaluation and Fine-Tuning for Image Captioning Models - A Case Study


Table of Contents
- Evaluation Metrics
- Fine-Tuning Strategies for Image Captioning Models
- Challenges in Image Captioning
- Case Study
- Conclusion
- FAQ
Image captioning models are sophisticated AI systems designed to generate descriptive text for images automatically. These models play a crucial role in various applications, such as enhancing accessibility for visually impaired users, enriching content for social media, and improving image search and retrieval systems. Below is an example of what image captioning looks like.

By convert visual content into natural language descriptions, image captioning models bridge the gap between visual data and human understanding, making vast amounts of visual information more accessible and understandable.
Evaluating and fine-tuning these models is essential to ensure they generate accurate, relevant, and coherent captions. The process of evaluation helps identify areas where the models excel and where they need improvement, while fine-tuning allows for the enhancement of model performance by adjusting them to specific tasks or datasets.
Effective evaluation and fine-tuning can significantly enhance user satisfaction and the overall utility of image captioning systems, making them more reliable and effective in real-world applications.
Evaluation Metrics
Image captioning models automatically generate descriptive text for images, transforming how we interact with visual content across various applications such as accessibility tools, content creation, and more.
Evaluating these models involves a rigorous analysis using multiple metrics to ensure the generated captions are precise and contextually relevant.
The table outlines the evaluation results for several image captioning models on the COCO caption "Karpathy" test split and the NoCaps validation set, using a range of metrics to assess performance.
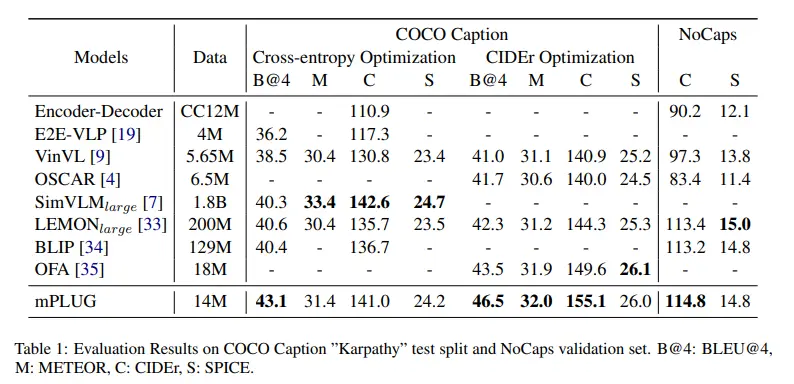
The mPLUG model demonstrates superior performance across multiple metrics, particularly in the CIDEr optimization category, indicating its robustness in generating high-quality, human-aligned captions.
SimVLM_large and LEMON_large also exhibit strong performance, especially in generalization tasks as seen in the NoCaps results. OFA shows high scores in the CIDEr optimization, reflecting its alignment with human consensus and semantic content accuracy.
Quality Assessment Metrics
BLEU Score(B@4)
The BLEU (Bilingual Evaluation Understudy) score is a fundamental metric for evaluating the quality of text generation, especially in contexts like machine translation and image captioning. It measures the overlap between generated captions and reference captions by comparing n-grams.
By calculating the precision of these n-grams, the BLEU score provides a quantitative assessment of how closely the generated text matches the human-annotated references.
Despite its utility, the BLEU score has limitations, such as its focus on precision without accounting for recall, and its insensitivity to the fluency and grammatical correctness of the text.
METEOR(M)
METEOR (Metric for Evaluation of Translation with Explicit ORdering) is designed to address some of the BLEU score's shortcomings by incorporating precision, recall, and synonym matching. METEOR aligns words in the generated caption with words in the reference caption using exact matches, synonyms, stemming, and paraphrases.
It calculates the harmonic mean of precision and recall, giving a balanced view of the model's performance. METEOR's higher correlation with human judgments makes it a valuable tool for evaluating the quality and meaning of generated captions.
ROUGE
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) focuses on recall, measuring the overlap between the generated and reference texts in terms of n-grams, word sequences, and word pairs.
This metric ensures that the generated captions capture as much of the reference content as possible, complementing precision-focused measures like BLEU. ROUGE is particularly useful for applications that prioritize the completeness of the information conveyed by the generated text.
CIDEr(C)
CIDEr (Consensus-based Image Description Evaluation) is specifically tailored for evaluating image captioning models. It calculates the Term Frequency-Inverse Document Frequency (TF-IDF) weighted n-gram similarity between the generated caption and multiple human-annotated reference captions.
CIDEr places a strong emphasis on the consensus among human annotators, rewarding captions that align well with the common content and structure of the reference captions. This human-centered approach makes CIDEr particularly effective in assessing the quality and relevance of generated captions, reflecting real-world expectations more accurately.
SPICE (S)
SPICE(Semantic Propositional Image Caption Evaluation), is a metric designed to assess the quality of image captions based on their semantic content. Unlike other evaluation metrics that primarily focus on n-gram overlap, SPICE delves deeper into the meaning and structure of the captions.
It breaks down both the generated and reference captions into a set of tuples that represent the scene's objects, attributes, and relationships. This process allows SPICE to evaluate how well the generated captions capture the essential details and meanings conveyed by the reference captions.
Human Evaluation
Despite the effectiveness of automated metrics, human evaluation remains crucial for assessing the relevance, coherence, and naturalness of generated captions. Human evaluators can provide nuanced judgments that capture subtleties and context that automated metrics might miss.
They assess how well the captions describe the content of the image, their grammatical correctness, and their overall fluency and readability. Human evaluation is indispensable for validating the performance of image captioning models and ensuring that the generated text meets user expectations and standards.
Temporal Consistency
Temporal consistency is particularly relevant for models that generate captions for video frames or sequences of images. It evaluates how well the model maintains context and coherence across different parts of the image or video frames.
This involves ensuring that the descriptions remain consistent with the temporal flow of events and that the narrative continuity is preserved.
Temporal consistency is essential for applications like video summarization, where the generated captions need to provide a seamless and accurate account of the visual content over time. Assessing temporal consistency helps in refining models to handle dynamic visual content effectively.
Fine-Tuning Strategies for Image Captioning Models
Fine-tuning strategies play a pivotal role in enhancing the performance of image captioning models. These strategies help adapt the models to specific scenarios, improve accuracy, and ensure relevance and robustness across various domains. Below are detailed explanations of some effective fine-tuning strategies.
One-shot Learning
One-shot learning refers to the process of fine-tuning a model using a single image-caption pair to adapt it for specific scenarios or domains. This approach is particularly useful in situations where acquiring a large dataset is impractical or impossible.
By leveraging a single example, the model can learn and generalize patterns to similar contexts, making it adaptable and flexible. For instance, in a niche domain like medical imaging, a single annotated example can provide significant insights, helping the model to generate accurate captions for other similar images.
Domain Adaptation
Domain adaptation involves adjusting the model to perform well on specific domains or types of image content. This technique ensures that the captions generated are relevant and accurate for the target domain.
Methods such as domain-specific training, where the model is trained on a dataset relevant to the target domain, and domain-invariant feature learning, where the model learns features that are consistent across different domains, are commonly used.
For example, adapting a general image captioning model to work specifically for architectural images would involve training it with a dataset containing various architectural structures and their descriptions.
Data Augmentation
Data augmentation enhances the robustness of the model by generating synthetic data or modifying existing data. Techniques like rotation, cropping, flipping, and color adjustments are used to create diverse training samples, helping the model to generalize better to unseen data.
In the context of image captioning, augmenting the dataset with variations of the same image can expose the model to different perspectives and lighting conditions, thereby improving its ability to generate accurate and varied captions. This approach is particularly valuable in domains with limited annotated data.
Transfer Learning
Transfer learning leverages the knowledge gained from pre-trained models to improve performance on specific image captioning tasks. By starting with a model that has been pre-trained on a large and diverse dataset, such as ImageNet, the fine-tuning process can focus on adapting the model to the specific characteristics of the target dataset.
This method significantly reduces the amount of data and computational resources required. For instance, a model pre-trained on a general image dataset can be fine-tuned using a smaller dataset of fashion images to generate high-quality captions for clothing and accessories.
Hyperparameter Tuning
Hyperparameter tuning involves adjusting the model’s parameters, such as learning rate, batch size, and number of layers, to optimize its performance. This process is crucial for finding the best configuration that maximizes the model’s accuracy and efficiency.
Techniques such as grid search, random search, and Bayesian optimization are commonly used to explore different hyperparameter settings. Effective hyperparameter tuning can lead to significant improvements in the model’s ability to generate accurate and coherent captions.
Reinforcement Learning
Reinforcement learning, particularly Reinforcement Learning with Human Feedback (RLHF), is used for iterative improvements in image captioning models. In this approach, human feedback is utilized to guide the learning process, allowing the model to refine its captions based on real-world judgments.
This method involves rewarding the model for generating high-quality captions and penalizing it for poor performance, thereby continuously improving its output. RLHF can significantly enhance the model’s ability to produce captions that are not only accurate but also contextually relevant and natural-sounding.
Challenges in Image Captioning
The development and deployment of image captioning models come with several significant challenges that need to be addressed to ensure the creation of effective and reliable systems. These challenges span computational complexity, data scarcity, ethical considerations, and the need for generalization.
Computational Complexity
Training and fine-tuning image captioning models require substantial computational resources. These models typically utilize deep learning architectures, such as Convolutional Neural Networks (CNNs) for feature extraction and Recurrent Neural Networks (RNNs) or Transformers for generating descriptive text.
These architectures involve millions of parameters, necessitating powerful GPUs and extensive computational time. The process of training these models from scratch can take days or even weeks, depending on the dataset size and model complexity.
Fine-tuning, while somewhat less demanding, still requires considerable resources, especially when adapting the model to specific domains or improving its performance on diverse datasets. Efficient management of computational resources is crucial to balance performance and feasibility.
Data Scarcity
Obtaining sufficient labeled data for training and evaluating image captioning models is another significant challenge. High-quality datasets with accurate image-caption pairs are essential for training robust models.
However, creating such datasets is labor-intensive and time-consuming, often requiring manual annotation by human experts. This scarcity of labeled data can hinder the development of models that generalize well to various contexts and domains.
Furthermore, the diversity and complexity of real-world images necessitate large and varied datasets to cover different scenarios, objects, and environments.
Addressing data scarcity involves strategies such as data augmentation, synthetic data generation, and transfer learning to maximize the utility of available data.
Ethical Considerations
Ethical issues in image captioning encompass bias in training data, the risk of misinformation, and the need for responsible content moderation. Biases in the training data can lead to skewed or prejudiced outputs, reflecting and perpetuating stereotypes.
For example, a model trained on biased data might generate captions that reinforce gender, racial, or cultural biases. The risk of misinformation arises when models generate inaccurate or misleading captions, potentially causing harm or misunderstanding.
Responsible content moderation is essential to ensure that the outputs of image captioning models are accurate, fair, and appropriate for all users. Implementing bias detection and mitigation strategies, along with human oversight, can help address these ethical concerns.
Generalization
Ensuring that image captioning models perform well on unseen data is a critical challenge. Models need to maintain accuracy across diverse datasets, which requires them to generalize beyond the specific examples they were trained on.
This involves capturing a wide range of visual and contextual features, enabling the model to generate relevant and coherent captions for new images. Overfitting, where the model performs well on the training data but poorly on new data, is a common issue that needs to be mitigated.
Techniques such as cross-validation, regularization, and using diverse training datasets can help improve the model's generalization capabilities. Continuous evaluation of varied and representative test datasets is also essential to ensure robust performance.
Case Study
A prominent news company encountered a significant issue with its image captioning system. The AI models used for generating captions often produced biased or inappropriate text, particularly in contexts involving sensitive social and political topics.
These biased captions not only risked misinforming the public but also damaged the company's reputation for neutrality and reliability in news reporting. To maintain their credibility and ensure ethical reporting, the company needed a solution that would produce accurate, unbiased, and contextually appropriate captions.
Solution
To tackle this challenge, the news company collaborated with our team of AI specialists who implemented Reinforcement Learning with Human Feedback (RLHF) to refine their image captioning model.

The process involved several key steps:
Initial Assessment and Data Collection: The team first assessed the extent and nature of the bias in the captions. They collected a diverse set of images along with the corresponding captions generated by the existing model, identifying patterns of bias or inappropriate language.
Human Feedback Integration: Human annotators, including journalists and content specialists, reviewed the generated captions and provided feedback on their accuracy, relevance, and potential biases. This feedback was used to create a dataset of high-quality, unbiased captions.
Reinforcement Learning Process: The RLHF approach involves using human feedback to guide the learning process of the model. The AI model was trained iteratively, with human feedback serving as a reinforcement signal to reward accurate and unbiased captions while penalizing biased or inappropriate ones.
The model's reward function was adjusted to prioritize captions that were not only accurate but also fair and contextually appropriate, reflecting the ethical standards of the news organization.
Continuous Monitoring and Adjustment: Even after the initial fine-tuning, the system was continuously monitored. Human reviewers regularly audited the captions generated by the model, providing ongoing feedback to ensure the model's performance remained aligned with the company's standards.
Outcome
The implementation of RLHF led to significant improvements in the performance of the news company's image captioning system:
Reduced Bias: The captions generated by the model showed a marked reduction in biased or inappropriate language. The system was better able to handle sensitive topics with the necessary neutrality and accuracy.
Improved Accuracy and Relevance: The quality of the captions improved, with more accurate and contextually relevant descriptions being produced. This enhancement was particularly noticeable in complex news scenarios where precision in language is crucial.
Enhanced User Satisfaction: The improvements in caption quality and neutrality led to higher satisfaction among the company's readership. Users reported increased trust in the news platform, appreciating the accurate and unbiased presentation of information.
Reputation Management: By addressing the bias in its AI systems, the news company was able to protect and even enhance its reputation for fair and balanced reporting. This case also served as a demonstration of the company's commitment to ethical AI practices.
Improve your image captioning with Labellerr’s easy-to-use SaaS platform! Get high-quality data to fine-tune your AI models quickly. Book a demo with us now.
Conclusion
Evaluating and fine-tuning image captioning models are crucial steps in enhancing the performance and accuracy of these systems. By systematically assessing these models using robust evaluation metrics such as BLEU, METEOR, SPICE, CIDEr, and human evaluations, we can ensure that the captions generated are relevant, coherent, and contextually appropriate.
Fine-tuning, through methods like one-shot learning, domain adaptation, data augmentation, transfer learning, hyperparameter tuning, and reinforcement learning, allows models to adapt to specific tasks, improve robustness, and ultimately provide more accurate and satisfactory user experiences.
FAQ
What are image captioning models?
Image captioning models are artificial intelligence systems designed to automatically generate descriptive text for images. These models analyze the visual content of an image and produce a relevant textual description that accurately conveys the scene, objects, and context depicted.
They utilize a combination of computer vision techniques for image analysis and natural language processing (NLP) for generating coherent and meaningful captions.
Image captioning models have a wide range of applications, including assisting the visually impaired, enhancing search engine capabilities, automating content creation, and improving user experience on social media platforms.
Why is fine-tuning important?
Fine-tuning is crucial in the development and deployment of image captioning models for several reasons:
Improving Accuracy: Fine-tuning allows models to adapt to specific datasets or tasks, leading to more accurate and contextually appropriate captions.
Enhancing Adaptability: By fine-tuning, models can better handle the nuances and variations in different types of images or domains, such as medical imaging, fashion, or news.
Optimizing Performance: Adjusting model parameters and using techniques like hyperparameter tuning can significantly improve the model's overall performance and efficiency.
User Satisfaction: Fine-tuning ensures that the generated captions meet user expectations in terms of relevance, coherence, and naturalness, thereby enhancing the user experience.
Reducing Bias: It helps in addressing and mitigating biases present in the training data, leading to fairer and more balanced outputs.
What is Reinforcement Learning with Human Feedback (RLHF)?
Reinforcement Learning with Human Feedback (RLHF) is an advanced machine learning technique where human feedback is integrated into the reinforcement learning process to improve model performance.
In the context of image captioning, RLHF involves using human evaluators to provide feedback on the quality of the generated captions. This feedback is then used to refine and adjust the model's parameters iteratively. The process helps in aligning the model's outputs more closely with human preferences and expectations, leading to more accurate, relevant, and natural captions.
RLHF is particularly effective in addressing issues related to subjective judgments and nuanced understandings that are difficult to capture through automated metrics alone.
References
1. GIT: A Generative Image-to-text Transformer for Vision and Language(Link)
2.mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections(Link)
3. RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback(Link)

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
