

How To Build Effective Data Pipeline For Audio Annotation


Table of Contents
- Introduction
- Who should read this?
- Use Cases in Audio and Speech Models for Different Scenarios
- Setting Up an Annotation Pipeline
- Setting Up Audio Annotation Pipeline in Labellerr
- Conclusion
- FAQs
Introduction
In audio and speech processing, the accuracy and performance of models heavily depend on the quality of annotated data. Setting up a robust data annotation pipeline is crucial for training models that can effectively understand and interpret audio inputs.
The complexity of audio data, with its diverse range of features such as pitch, tone, duration, and context, demands a well-structured annotation pipeline. This pipeline must ensure that data is annotated with high precision and consistency to train models that can handle the nuances of human speech and various audio environments.
Who should read this?
To ensure the relevance and applicability of the content, we are making a few key assumptions that readers are-
- AI Teams: This guide is tailored for AI teams mostly working from the U.S., considering the specific challenges and opportunities present in this market.
- Focus on NLU and Speech Models: Your primary focus is on developing Natural Language Understanding and speech models, including generative AI models. This guide will address the unique needs and considerations for these types of models.
- Fast-Growing Company: You are part of a rapidly expanding company where the success of your business heavily relies on the performance and accuracy of your AI models.
- Importance of Model Experimentation and Tuning: Quick iteration and effective tuning of your models are critical components of your development process.
This blog will help you understand how a well-structured data annotation pipeline can support these efforts, allowing you to iterate faster and more efficiently.
Use Cases in Audio and Speech Models for Different Scenarios
1. Voice Bots
Voice bots have become a staple in customer service, automating interactions and improving efficiency. Multiple customer interaction automation companies use voice bots to handle customer inquiries, reservations, and orders in the hospitality industry.
The key to the success of these voice bots lies in accurately annotated audio data, which allows the models to understand and respond to a wide range of customer queries effectively.
Scenario: The model is already trained and live in production, but the accuracy is low, leading to ineffective customer interactions.
It required annotated audio files to go into the labeling pipeline to improve the transcription by humans in the loop.
Solution with Labellerr:
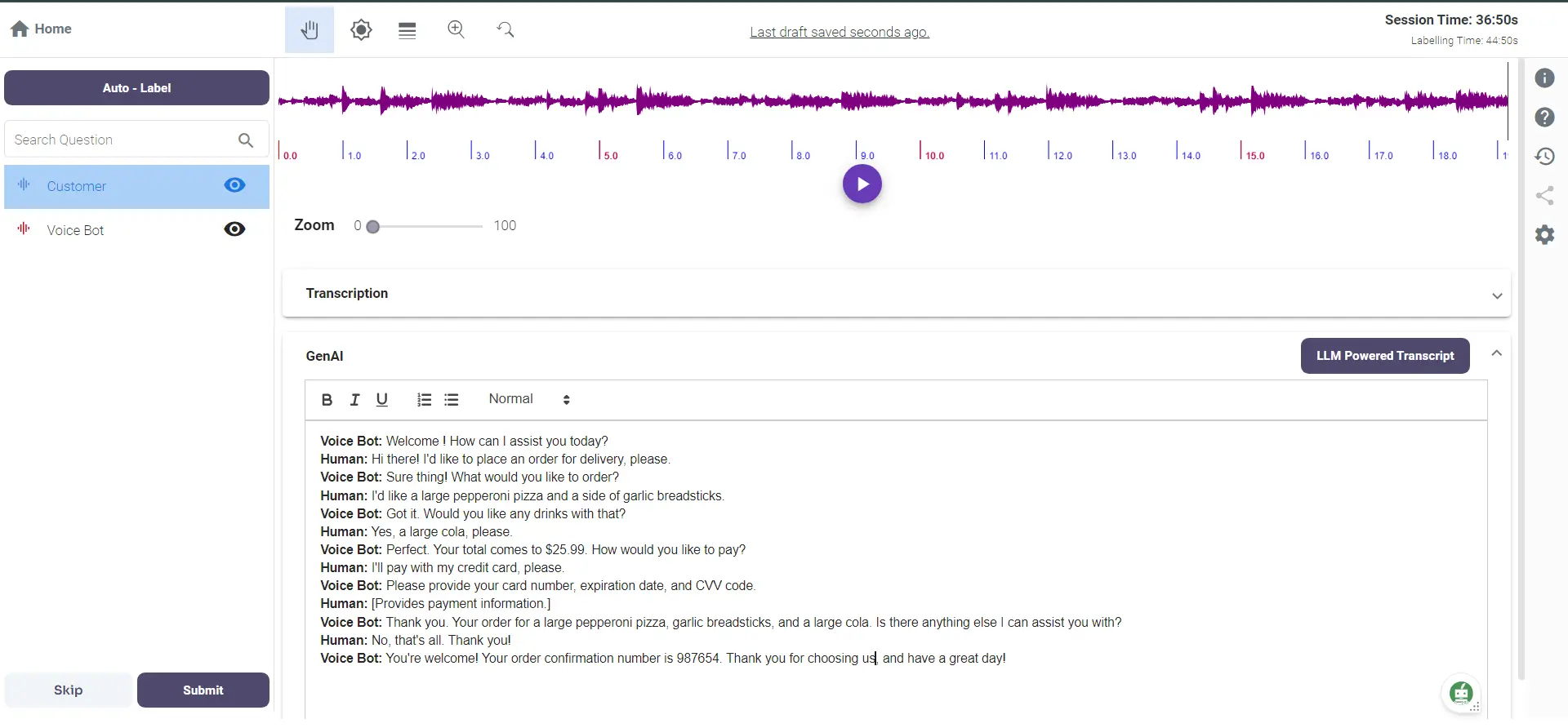
Labellerr can significantly enhance the accuracy of these models through a structured QC process.
Initially, Labellerr conducts a comprehensive analysis of the current annotations and model performance to identify specific areas where accuracy is lacking, such as misinterpreted customer queries.
Following this, a new batch of audio data from customer interactions is collected and meticulously annotated, focusing on problematic areas identified during QC.
This includes annotating speech-to-text and customer intent and marking special features like background noise and accent variations.
The voice bot model is then retrained with this newly annotated data, improving its accuracy in understanding and responding to queries.
2. Digital Assistants in Toys and Conversational Hardware
Scenario: Interactive Toys and Elderly Assistance
Digital assistants embedded in toys or devices like Alexa can engage children and assist the elderly by responding to voice commands and engaging in conversations.
Companies like UG Labs and Miko develop these interactive systems, requiring extensive annotation of child and elderly voices to ensure the assistant can understand and interact appropriately.
Existing Issue: High rates of false positives and challenges in speaker diarization, particularly understanding kid's voices.
Solution with Labellerr
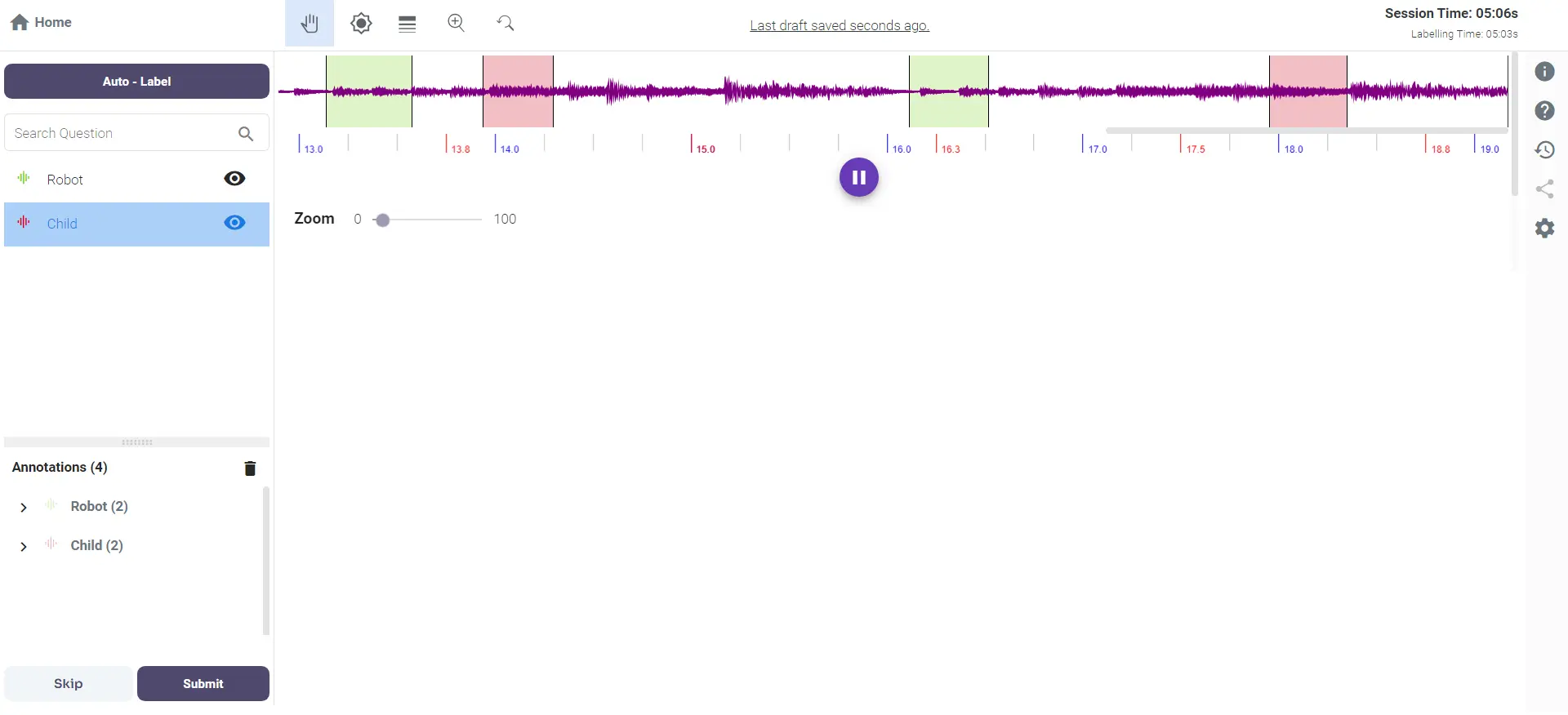
Labellerr addresses these challenges by first conducting an initial evaluation to pinpoint the sources of false positives and errors in speaker diarization.
Following this, a comprehensive dataset of child and elderly voices is collected, encompassing various scenarios such as commands, questions, and conversational turns. This data is annotated for speech-to-text, speaker identification, and emotion recognition.
The existing audio pipeline is then adjusted to incorporate advanced speaker diarization techniques and filters to reduce false positives. Labellerr also implements model-assisted labeling for more efficient and accurate annotations, with human reviewers validating the model's suggestions to prevent bias.
The digital assistant models are retrained with the new annotated dataset, fine-tuning them to better distinguish between different speakers and reduce false positives.
Finally, the improved models are deployed in the live environment, with continuous performance monitoring and data collection for ongoing enhancements.
3. Patient-Doctor Conversations and Therapy Sessions
Scenario: Medical Transcription and Analysis by Healthcare Companies
In the medical field, accurately transcribing patient-doctor conversations and therapy sessions is crucial for maintaining comprehensive medical records and providing quality care. Several companies specialize in developing models for this purpose, ensuring confidentiality and precision.
Existing Issue: No existing pipeline; the process needs to be set up from scratch using raw data.
Solution with Labellerr:
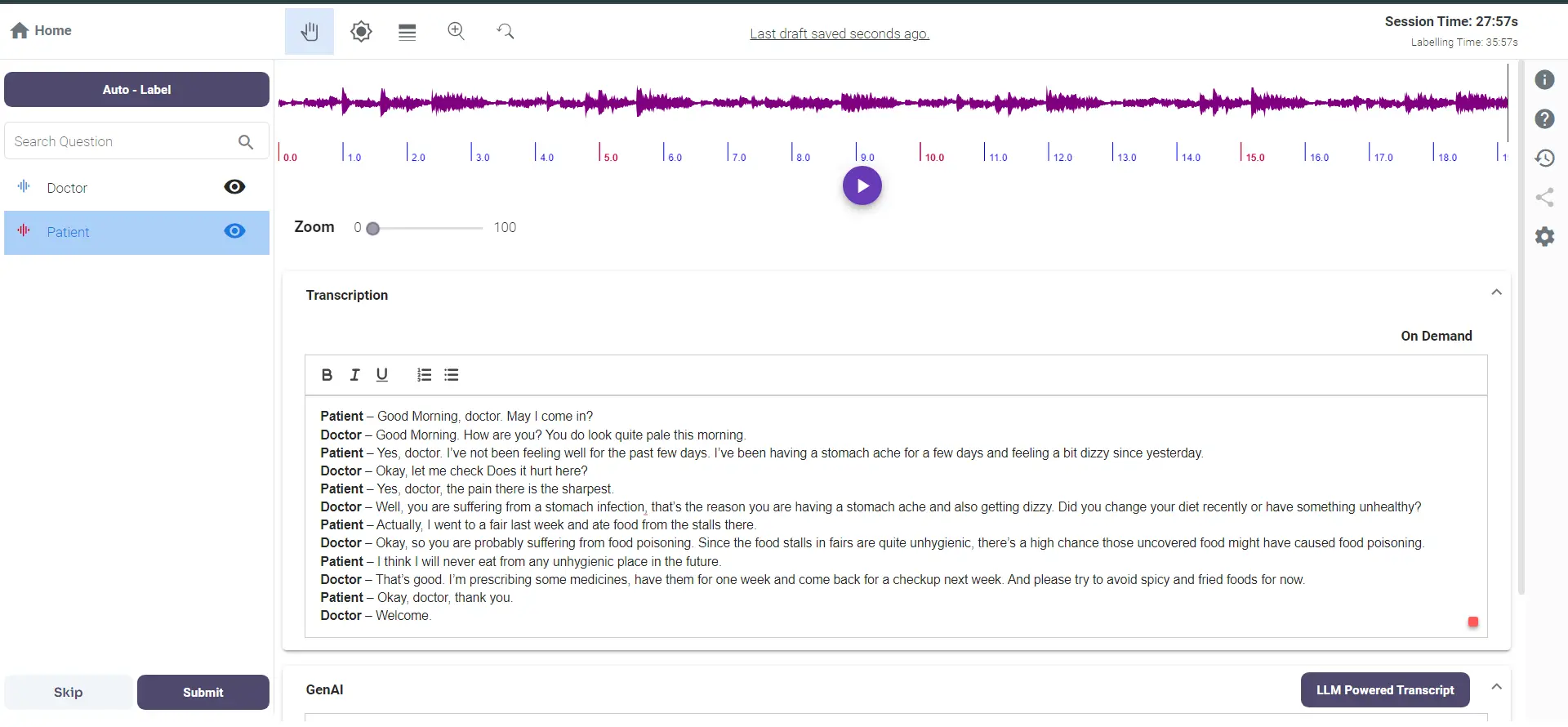
Labellerr can set up a comprehensive audio annotation pipeline from scratch. The process begins with creating a workspace in Labellerr and connecting it to the raw data storage.
Raw audio data is collected from patient-doctor interactions, and specific annotation requirements are defined, including speech-to-text transcription, and speaker identification.
Annotators are trained on these guidelines, focusing on understanding medical terms, maintaining confidentiality, and ensuring accurate speaker diarization. The collected audio data is then annotated according to these requirements using Labellerr's tools to ensure consistency and quality.
Initial models are trained with this annotated dataset, focusing on tasks like ASR (Automatic Speech Recognition), medical entity recognition, and speaker diarization.
The model's performance is evaluated using metrics such as Word Error Rate and medical term recognition accuracy, and areas needing improvement are identified for further iterations.
Once the model achieves the desired accuracy, it is deployed in a controlled environment, with continuous performance monitoring and adjustments as needed. An ongoing data collection and annotation pipeline is established to keep the models updated with new data, ensuring they adapt to new medical terminologies and evolving conversation patterns.
It is pertinent that you need to have a data annotation and model evaluation pipeline in place which can ensure that your models get updated as fast as possible while improving accuracy upwards.
Setting Up an Annotation Pipeline
Building high-performing audio and speech models requires a continuous cycle of data preparation, training, evaluation, and improvement. The high-level process would look like the following:
- Label an Initial Dataset of Audios According to Guidelines: Begin by annotating a diverse set of audio samples following predefined guidelines to ensure consistency and accuracy.
- Train Your Speech AI Models: Use the labeled dataset to train your models for various tasks such as Automatic Speech Recognition (ASR), emotion recognition, dialogue, speech synthesis, keyword spotting, and speaker diarization.
- Evaluate Performance with Model Performance Metrics: Assess the performance of your models using metrics like word error rate for ASR, ensuring that the models meet the desired accuracy standards.
- Identify Low-Performance Cases: Detect instances where the model's performance is subpar. This is typically done by evaluating model confidence scores and comparing predictions against ground truths or evaluation sets.
- Collect More Representative Unlabeled Data: Gather additional unlabeled data representing the identified challenging cases. Techniques such as unsupervised learning, embedding matching, heuristics, and generative AI can be used to identify relevant data.
- Label the Incremental Dataset: Annotate the newly collected data to expand and diversify the training dataset.
- Update the Model and Test: Retrain the model with the augmented dataset, then test it again using data unit tests or evaluation sets to verify improvements.
- Deploy the Updated Model: Implement the updated model in your production environment.
- Repeat from Step 3: Continuously monitor performance, identify new low-performance cases, and iterate on the process to continually enhance model accuracy and robustness.
How To Decide Pipeline
Here are the 3 big factors that contribute to deciding the pipeline setup-
- What is the volume of data?
- Is it a one-time or recurring task?
- Is data raw or coming from models already deployed in production?
Volume of Data
If a team is running multiple projects with a smaller volume of data set then semi-automatics approach make more sense.
Here the data inflow is not regular and also the volume of data remains smaller. It can easily uploaded to cloud storage that can be integrated into an annotation tool that provides a full pipeline where humans in the loop can use some model-assisted labeling to do the task.
For bigger volumes, an active learning-based labeling pipeline can save time and give better results. It also ensures with more data inflow the cost and effort do not increase linearly, rather it provides a cost reduction with every iteration.
One-Time vs Recurring Need
Again, in one-time need generally team collect their data at once that can connect to labeling pipeline with semi automated labeling approach is enough, as it generally have low volume of data.
However, for recurring needs, especially with a fast-growing company requiring constant model fine-tuning, an automated pipeline is highly recommended.
Scoping Performance Issues:
Can you identify specific scenarios where your speech-to-text model struggles?
For example, is your voicebot failing to understand menu items for new restaurants or encountering unfamiliar dialects from expanding customer bases?
- Performance Measurement: Are you currently quantifying your model's performance using metrics like Word Error Rate (WER) or others specific to your application?
- Model Control: Do you have control over the underlying model architecture? Open-source models like OpenAI Whisper, wave2vec, or Deepspeech offer extensive fine-tuning capabilities. At the same time, third-party APIs like AssemblyAI, Google Speech-to-Text, AWS Transcribe, or Azure Speech Services may have limited fine-tuning options. You can explore more here.
- Existing Processes: Do you have established procedures for:
- a) Quality Assurance (QA) on your live model performance?
- b) Labeling completely new data for onboarding new customers, especially for new languages, use cases (keyword spotting), or specific voice types (age groups, genders)?
Based on your answers to the previous questions, if you decide to set up or optimize an efficient data annotation pipeline, follow these steps-
1) Find a Data Annotation Tool:
- Selection Criteria: Consider parameters such as data security and compliance, handling PII data, cloud connectivity or local upload options, configurable labeling, QA interfaces, workflow fit to your business, and the ability to automate the labeling process. Automation should include automatically loading data, creating weekly tasks, and connecting to your model for model-assisted labeling.
- Resource: Some of the top speech to text annotation tool . These tools have been reviewed for their capabilities and fit for various speech-to-text annotation needs.
2) Hire Annotators:
- Criteria: Look for annotators with experience in handling similar voice projects. Consider their strength, location, and costs.
- Resource: Refer to this list of the best audio annotation services in 2024 to find suitable candidates or services.
3) Training Annotators:
- Training Plan: It is beneficial to hire a Learning & Development (L&D) person, ideally from your internal team, who is a domain expert and familiar with your end-to-end workflow. This ensures the training is tailored to your specific needs and standards.
4) QA Process:
Methods: Implement a robust QA process to ensure the quality of annotations. Some methods include:
- Inter-Annotator Agreement: Measure consistency between different annotators.
- Evaluation Sets-Based QA: Use predefined evaluation sets to assess the quality.
- AI Models-Based QA: Leverage AI models to detect anomalies and ensure accuracy.
- Visual QA: Manually review annotations through a visual interface.
- Smart Filtering and Clustering-Based QA: Use algorithms to filter and cluster data for efficient QA.
Setting Up Audio Annotation Pipeline in Labellerr
Let us take an example, taking cues from how we set this up in general from customers with similar requirements. We will also mention any specific challenges that might occur and how they can be solved.
Assume that you have to annotate the speech data of 1000 hours with 250 hours per quarter.
1) Access Labellerr Platform:
Visit Labellerr's website or directly sign in at https://login.labellerr.com using your Google account.
2) Create a Workspace
If you haven't already, create a workspace within Labellerr to organize your projects and data.
3) Set Up Annotation Project
Navigate to create an annotation project within your workspace. This may take a moment to load the project creation page.
4) Create a Dataset
Begin by creating a dataset within Labellerr that connects to your Cloud storage for example AWS S3 storage. Follow detailed step-by-step guides provided by Labellerr's knowledge base for authenticating and setting up connections to AWS S3 where your 1000 hours of speech data is stored.
5) Specify Annotation Requirements
Define the specific annotations needed for your project. For instance, annotate speech-to-text transcriptions, identify speakers and timestamps, capture emotions depicted in audio segments, and mark any instances of Personally Identifiable Information (PII) for redaction in downstream processes.
Additional Considerations
Large Datasets and Scalability: Labellerr is designed to handle large datasets efficiently. For your 1000-hour project, consider breaking down the data into smaller batches for labeling in manageable chunks throughout your quarterly schedule (250 hours/quarter).
Quality Assurance (QA): Labellerr offers built-in QA features to ensure data accuracy. These might include:
Complex Annotation Needs: Labellerr supports detailed annotations such as speaker identification, emotion recognition, and sensitive data handling, addressing the complexities of your annotation requirements.
Data Privacy and Security: Ensure compliance with Labellerr's data privacy and security capabilities, particularly when handling sensitive data like PII within annotations.
By following these steps and leveraging Labellerr's functionalities, you can establish a secure, efficient, and scalable audio annotation pipeline for your speech data, ultimately improving the quality and performance of your audio and speech models.
Conclusion
Establishing an effective data annotation pipeline for audio and speech models is essential for maximizing their accuracy and utility. From initial dataset labeling through to continuous model refinement and deployment, each phase is critical in ensuring the performance of AI systems
Tools like Labellerr facilitate this process by allowing organizations to create structured workflows, and define specific annotation requirements like speech-to-text transcription and emotion recognition.
By integrating these steps, teams can effectively manage and optimize their annotation processes, ensuring high-quality data that drives the accuracy and adaptability of their audio and speech models in real-world applications.
FAQs
Q1) What is audio and speech data annotation?
Audio and speech data annotation involves labeling audio data with specific information. This could include transcribing spoken words, identifying speakers, tagging emotions, or redacting sensitive information. This labeled data is then used to train and improve speech recognition, sentiment analysis, and other speech-based applications.
Q2) Why is annotation important for speech models?
High-quality, accurate training data is crucial for building effective speech models. Manual annotation helps ensure the models can understand and respond to various speech patterns, accents, and nuances in human communication.
Q3) What metrics should I use to evaluate model performance in speech and audio tasks?
Common metrics include Word Error Rate (WER) for speech recognition tasks, accuracy scores for emotion detection or speaker identification, and precision-recall metrics for tasks involving sensitive data (e.g., PII recognition).

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
