

How to manage the quality of training data while doing data labeling


Are you someone who deals with training data for their AI and Machine learning project? If yes, then you must be aware of the fact that quality data plays an important role. The caliber of the training datasets affects how well a machine-learning model performs. In machine learning, the consistency and accuracy of the labeled data are used to judge quality. When you are performing data labeling, then it becomes essential to manage the quality of training data.
Among the most intriguing recent developments in technology is machine learning. Most crucially, AI and machine learning systems develop new skills on their own. The caliber of the training datasets affects how well a machine-learning model performs. In machine learning, the quality of labeled data is evaluated using its consistency and accuracy.
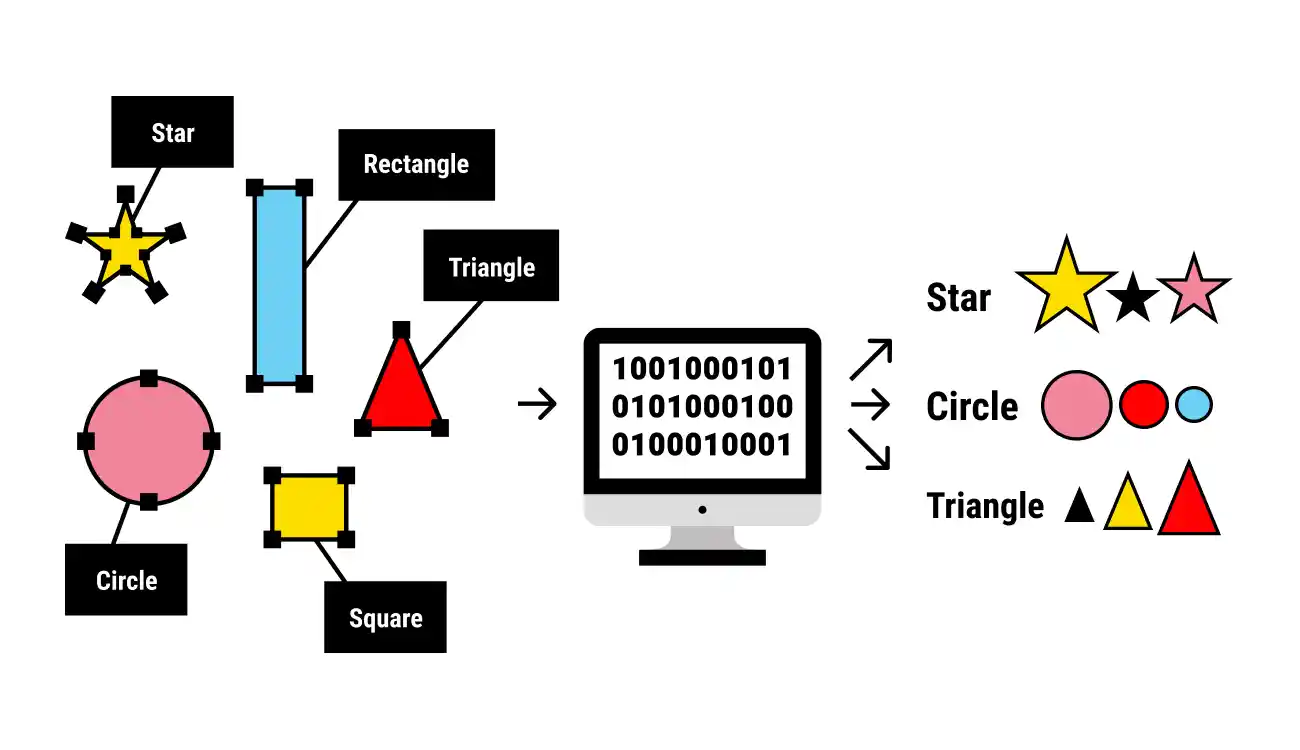
Some of the methods used in the industry to judge the quality of training data include benchmark consensus, review, and Cronbach's alpha test. When you have labeled data in machine learning, it indicates that your data has been marked up or labeled to represent the goal, which is the prediction you want the machine-learning model to make. Data tagging, data annotation, data classification, data moderation, data transcription, and processing are all examples of jobs that fall under the general category of data labeling.
Table of Contents
- How Can the Quality of Data Labeling Be Determined?
- Data Quality Measurement Techniques
- What Can Be the Best Data Labeling Approach?
How can the quality of data labeling be determined?
Different occupations require different data quality controls. There are a few qualities of high-quality training datasets that are used in big data initiatives that several data scientists and researchers tend to agree upon. The set of data itself is crucial in the first place. The proportion and diversity of the data points inside the algorithm determine its capacity to predict future related points and patterns.
Second, the quality of datasets for training the model is often determined by the accuracy with which categories and labels are assigned to each data point. However, the consistency of the data labeling is just as important as its quality. Both data consistency and correctness are evaluated throughout the process of quality assurance which involves various steps that can be completed manually or automatically.
Data quality measurement techniques
Without quality assurance, the process of data labeling is insufficient. For the machine-learning model to function successfully, the labels on the data must indicate an accuracy level that is close to the ground truth, be distinct from one another, and be of some benefit. This is valid for all uses of machine learning, including processing natural language and creating computer vision models.
The procedures for data labeling are listed below:
Collection of data
The model's training data are collected in their raw form. This data is cleaned up and processed to provide data that can be directly inserted into the model.
Data Tagging:
A variety of data labeling approaches are used to identify the data and connect it to a pertinent context that the technology may use as the source of truth.
Assurance of Quality
The quality of the coordinates for bounding boxes and key point annotations, as well as the clarity of the tags for a particular data point, are frequently used to assess the quality of the annotations. QA processes like the Consensus algorithm, Cronbach's alpha test, benchmarks, and reviews are very helpful for determining the general correctness of these annotations.
Algorithm of Consensus
This technique involves getting multiple systems or people to agree on a single point of information in order to demonstrate data dependability. Consensus can be obtained by either employing a fully automated method or by allocating a specific number of evaluators to every data point (which is more typical with open-source data).
Cramer's alpha
It measures the degree of a group of things' interconnectedness or reliability. This statistic measures scale dependability. A "high" alpha number does not always indicate that the measure is one-dimensional. If you wish to demonstrate that the scale is single-dimensional in addition to evaluating internal consistency, you can conduct further investigations.
Benchmarks
When evaluating how well a group or individual's annotations adhere to a verified standard created by knowledge specialists or data scientists, benchmarks, also referred to as gold sets, are utilized. Since benchmarks need the smallest number of overlapping efforts, they are the most economical QA solution. As you continue to evaluate the caliber of your work throughout the project, benchmarks may be useful. They could also be utilized to filter test data set choices for annotating.
Review
Conducting a review is another technique to evaluate the quality of the data. This tactic is based on an analysis of label correctness conducted by a domain expert. Although a few projects go through every label, the evaluation is frequently performed by visually evaluating a small sample of labels.
The first step in collecting high-quality training data is identifying the appropriate methods and platforms to classify your training data. Success with your models will depend on your ability to prioritize and recognize the importance of high-quality training data.
What can be the best data labeling approach?
Manual Labeling
Manual labeling of visual data is the oldest and most well-known method. Individuals are entrusted with manually selecting objects that are interesting in each image and applying metadata to each one that describes the type and/or location of these objects. In general, manual data labeling entails a single annotator identifying specific items inside still or moving picture frames. It takes a lot of time and effort to complete this process.
Even while it may just take just a few seconds for each instance of labeling, the result of labeling hundreds of photos at once could create a backlog and hinder a project. Because of this, more and more AI engineers are turning to qualified data annotators. In fact, some businesses nowadays are completely dedicated to offering data set labeling services.
Well-trained human annotators continue to set the bar for accuracy and precision in training datasets. The edge instances that automated systems miss are captured by manual marking, and skilled human managers can guarantee data consistency across enormous data sets.
Automated Labeling
Any data point labeling that is not done by humans is referred to as automatic labeling. This could refer to labeling using heuristic methods, machine learning models, or a mix of the two. A heuristic technique entails processing a single data point via a set of criteria that have been established in advance to decide the label. These guidelines are frequently created by human experts who are aware of the underlying variables that affect how a data piece is labeled.
Since only one or a small number of human experts can establish the rules for each sort of data item, heuristic techniques have the benefit of being cost-effective. Since just a small number of criteria will be applied to each data point, the labeling process is also rather efficient.
Moreover, if the format of the relevant data shifts over time, such rules might stop making sense or even turn out to be flawed, which would reduce the label accuracy or even make the algorithm useless until the changes were taken into account. The experts may not be aware of the specific algorithmic procedures they employ themselves to analyze a data point, or the information may be of a form that makes it impossible to describe these principles.
These two steps—first, data labeling and another checking and confirming to assure the accuracy of annotations—are extremely important in manual data labeling. Compared to manual annotation, automated data labeling requires less time for labeling and verification.
Although the automated data labeling process can label data up to ten times quicker than a human can, and technological advancements have increased efficiency and quality, it is still crucial to have a human in the loop to guarantee accuracy and quality when labeling data for machine learning.
If you are looking for an end to end platform to train your data while not compromising quality and security, then Labellerr is the right platform for you. We are a training data platform with high level of automation and smart assistive feature making your AI production ready faster. In order to scale your AI and Machine learning project, we highly recommend you use high-quality data. And if you have a feeling about whether your dataset will be supported by our platform or not while performing data labeling, then don’t worry. Labellerr supports annotation for various forms of data from image, and video. Still confused, then visit our website and check it for yourself!
To know more about data training and related information, stay updated with us!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
