

How Computer Vision Powers Autonomous Vehicles
Computer vision helps self-driving cars “see” and understand their surroundings using AI, cameras, LiDAR, and radar. It powers object detection, lane tracking, and decision-making in real time, making autonomous vehicles smarter, safer, and ready for complex road conditions.


Can a car actually see the world better than a human?
And if so, how does it do that in rain, fog, or total darkness?
In 2024 alone, over 110 million vehicles worldwide were equipped with some form of advanced driver-assistance system (ADAS), projected to double by 2030 as full autonomy edges closer to reality.
But behind every lane-keeping assist, emergency brake, or fully autonomous vehicle is one critical component: computer vision.
As AI engineers, robotics developers, and autonomous systems researchers, we know that “seeing” in a machine context isn’t about eyes; it’s about data.
It’s about turning streams of raw pixels into meaningful insights, actionable decisions, and ultimately safe navigation.
But how does a self-driving car parse that data?
How does it distinguish a child running from a rolling shadow?

How does it recognize traffic signs across an intersection, even when covered in mud or graffiti?
The answer lies in a powerful combination of deep learning, sensor fusion, and real-time visual inference, an entire perception stack designed to mimic (and often surpass) human vision.
As a team who are experts in computer vision, we’ve seen firsthand how object detection, semantic segmentation, and object tracking come together to create intelligent driving decisions in split seconds.
In this guide, we will learn;
- Technologies used to understand their surroundings
- Which is better, LIDAR or Vision
- Method Used To Understand Their Surroundings Using Vision
- Integrating Various Data Sources for Accurate Perception
- The Future of Computer Vision for Autonomous Vehicles
Technologies Used To Perceive Environment
Autonomous vehicles must see better than humans to drive better than us.
Engineers face major challenges in building reliable vision for self‑driving cars, but they overcome these challenges by using many different sensors together.
This sensor diversity and redundancy let the car double‑check its surroundings and capture details even better than human eyes.
Self‑driving cars rely mainly on three sensors: cameras, radar, and lidar.
These sensors work together to give the car a clear view of its surroundings.
They help the car measure how fast nearby objects move, how far away they are, and even reveal their 3D shapes.
Let's see what each sensor does in perceiving the environment.
LiDAR (Light Detection and Ranging):
LiDAR sends out laser beams that bounce off objects.

It builds a detailed 3D map of the area, measures distances, and helps the car detect objects, even when the light is low.
Radar:
Radar sends radio waves to find out how far objects are and how fast they move. It works well in fog, rain, or snow and provides strong long-range detection.

Cameras:
Cameras take clear, high-resolution pictures that show lane markings, traffic signs, and obstacles.

The car’s computer then analyzes these images to identify objects and understand its surroundings.
Which is better, LIDAR v Vision
Self-driving cars rely on advanced sensor systems to perceive and navigate the world around them.
Two of the most important technologies are LiDAR and camera-based vision.
While both help the vehicle "see" its surroundings, they work in very different ways and have their own strengths and limitations.
LiDAR in Self-Driving Cars
LiDAR helps self-driving cars "see" by sending out laser beams to map the environment in 3D.
It measures distances very accurately and works well in both day and night since it doesn’t rely on light. It can detect small objects like road debris and gives reliable depth data that supports other sensors.
However, LiDAR can struggle in bad weather like rain or snow, and it’s quite expensive and power-hungry. Its range is shorter than radar, and the high cost makes it less practical for mass-market vehicles.
Camera-Based Vision in Self-Driving Cars
Cameras help autonomous vehicles understand the world visually, much like human eyes.
They recognize traffic signs, lane markings, and even subtle cues like brake lights. Cameras are cheap, capture high-resolution images, and allow AI models to classify different objects like pedestrians and cars.
But cameras depend heavily on good lighting and can get blinded by glare, darkness, or fog.
They also don’t measure depth directly, so they need help from other sensors or extra cameras to judge distances.
Plus, processing camera data in real-time needs powerful AI chips.
Method Used To Understand Their Surroundings Using Vision
Self-driving cars actively use computer vision (CV) to perceive and interpret their environment, enabling them to make intelligent and safe driving decisions in real time.
By processing visual data from cameras and other sensors, these autonomous vehicles identify and track objects such as pedestrians, other vehicles, traffic signs, lane markings, and road obstacles.
Computer vision systems help the car recognize and understand complex scenes, predict the movement of dynamic objects, and assess the overall driving context.
To achieve this, self-driving cars employ a combination of CV techniques:
Object Detection and Recognition
A big part of making self-driving cars work is teaching them to detect multiple objects on the road around them.
The car uses cameras and sensors to distinguish between elements like other vehicles, pedestrians, road signs, and obstacles.
The car uses advanced computer vision methods to quickly and accurately recognize these objects in real time.
Image Classification and Localization: Convolutional Neural Networks (CNNs) classify objects (e.g., vehicles, pedestrians, traffic signs) and pinpoint their locations within an image.

Semantic Segmentation: Each pixel in an image is labeled to distinguish between road, lane markings, obstacles, and other elements

Instance Segmentation: Identifies individual objects within a group (e.g., multiple pedestrians)

Object Tracking
After the car detects something, it needs to monitor it, especially if it's moving.
This is important for understanding where things like other cars and people might go next, which is crucial for path planning and collision avoidance.
The car looks at how these objects move over time to guess where they will be next. Computer vision algorithms accomplish it.
There are mainly two algorithms used for object tracking:
Deep SORT
Deep SORT (Simple Online and Realtime Tracking with a Deep Association Metric) is a tracking algorithm that combines object motion and visual appearance to associate objects across video frames.
It uses a Kalman filter for motion prediction and augments it with deep CNN-based appearance embeddings (ReID features) to improve robustness.
This makes it especially effective in urban driving scenarios with pedestrians or cyclists where objects may be temporarily occluded or move unpredictably.
Deep SORT excels at re-identifying objects even after occlusion, ensuring stable tracking IDs, but requires more computation due to the feature extraction step.
ByteTrack
ByteTrack is a lightweight and high-performance object tracking algorithm that relies solely on motion cues and IoU matching but introduces a clever mechanism of incorporating both high-confidence and low-confidence detections during tracking.
This makes it highly suitable for dense traffic or crowded environments where occlusions or noisy detections are common.
ByteTrack does not require deep appearance models, making it faster and ideal for real-time applications in self-driving cars.
Although it doesn't explicitly handle re-identification, its ability to maintain stable tracks with minimal computational cost makes it a great fit for highway and urban traffic scenarios.
Integrating Various Data Sources for Accurate Perception
Self-driving cars don’t rely on just one type of object detection to understand their environment.
They use a combination of detection methods to get a complete and accurate picture.
These include 2D object detection from cameras, 3D object detection from LiDAR, radar-based detection, and sometimes even segmentation-based detection.
Each method brings unique strengths: cameras provide rich visual details for recognizing objects like traffic signs or pedestrians, LiDAR offers precise depth information for measuring distances, and radar can detect objects reliably even in poor visibility conditions like fog or rain.
To make sense of all this data, self-driving systems use a process called sensor fusion and multi-modal perception.
This is like assembling a puzzle where each detection method fills in a different part of the scene.
By intelligently merging 2D, 3D, and radar-based detections, the car builds a more reliable and robust understanding of its surroundings.
This fusion enables the system to handle complex environments, reduce blind spots, and make safer, more informed driving decisions, especially in unpredictable real-world conditions.
What Labellerr has to offer for the automotive industry?
Companies building self-driving car technology rely a lot on machine learning.
But to make sure their models are safe and work well, they need a strong data labeling system.
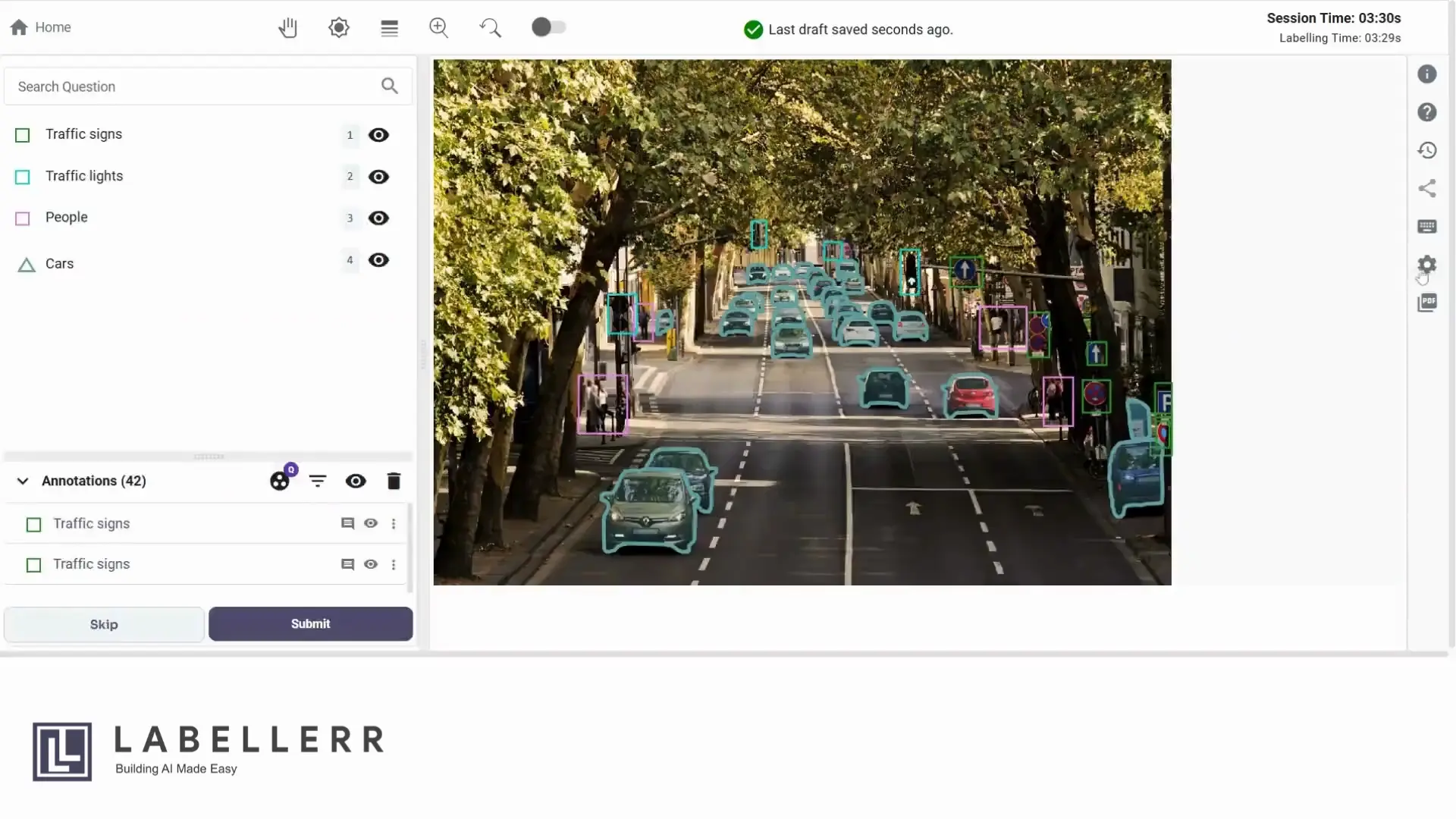
Labellerr offers a platform for data annotation of various types:
- Bounding Box
- Polyline
- Semantic Segmentation
- Polygons
- 3D Cuboids
The Future of Computer Vision for Autonomous Vehicles
Computer vision is quickly transforming self-driving cars and the way we travel. With constant improvements, this technology is solving tough problems and unlocking new possibilities.
Here are the top trends shaping its future:
1. Smarter Vehicle Perception
Cars will use real-time camera and sensor data to build 3D maps and navigate more safely. Vision systems will also adjust better to different lighting and weather conditions like fog, snow, or nighttime driving.
2. AI-powered accuracy
Advanced neural networks will boost object detection, traffic sign reading, and decision-making. Deep learning will help predict how other cars or pedestrians might move, reducing accidents and improving traffic flow.
3. Stronger Sensor Fusion
By combining vision with LiDAR, radar, and GPS, vehicles will handle tricky conditions better. These systems will also share real-time updates on road closures or traffic through smart communication with infrastructure.
4. Better Driver Assistance (ADAS)
Computer vision will make safety features like emergency braking, lane warnings, and cruise control even more reliable and responsive.
Conclusion
Self-driving cars are becoming smarter, faster, and safer, thanks to computer vision.
By combining cameras, LiDAR, radar, and powerful AI models, these vehicles can “see” and understand the world better than ever before, even at night, fog, or busy city streets.
With advanced object detection, tracking, and real-time decision-making, autonomous cars don’t just react; they predict.
They can spot a pedestrian, read a traffic sign, or track moving cars with speed and precision that rivals human ability.
As this technology improves, and with tools like Labellerr helping build high-quality training data, the road to full autonomy is getting shorter. Soon, computer vision won’t just assist you in driving; it will be the driver.
FAQ
How do self-driving cars see in bad weather or at night?
They use a combination of sensors—cameras for visual cues, LiDAR for 3D mapping, and radar for object detection in rain, fog, or darkness.
What role does AI play in computer vision for vehicles?
AI models process sensor data to recognize patterns, classify objects, and make real-time driving decisions, mimicking how humans perceive and react.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
