A complete guide on object detection & its use in self-driving cars

Table of Contents
- Introduction
- What is Deep Learning?
- What are Convolutional Neural Networks?
- Single-Shot-Detector (SSD)
- Challenges
- Summary
Introduction
Self-driving cars are anticipated to have a profound and revolutionary impact on society and the way people commute. However, for these cars to become a functional reality, they need to be equipped with perception and awareness to tackle high-pressure real-life scenarios, arrive at suitable decisions, and take appropriate and safest actions at all times.
Object detection is a step in this direction and a very crucial task for any self-driving car as it helps the car identify and locate objects around it so it can understand its surroundings better. This is a very important task as it can help detect obstacles and prevent accidents ensuring a safer ride. With the recent advances in Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL), various applications of these techniques have gained prominence and come to force. One such application is object detection for self-driving cars.
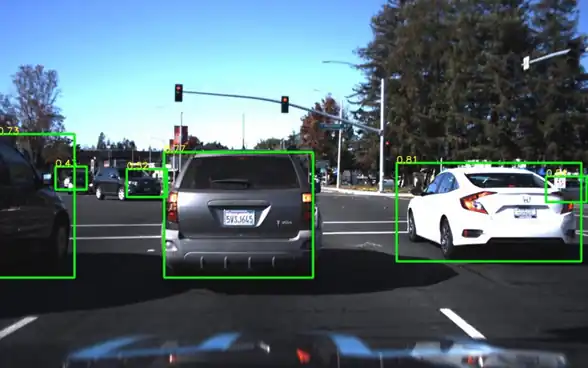
With the rise of autonomous vehicles, fast and accurate object detection systems are rising in demand. These systems involve not only recognizing and classifying every object in an image but localizing each one by drawing the appropriate bounding box around it, as we can also see in the image below. This makes object detection a significantly harder task than its traditional computer vision predecessor, image classification. We have discussed more object detection in our previous blog. (Link to the blog)
Previously, technologies like Radar, LiDAR, GPS, and various other sensors had been employed for self-driving cars for mapping the surroundings of the car. However, recently, deep neural network (DNN) algorithms like Convolutional Neural Networks (CNN) have gained more popularity for tasks like object detection in self-driving cars as they are capable of detecting objects even when live video is considered as the input, thus having the potential to be included as a part of the self-driving car systems.
Object detection using deep learning provides a fast and accurate means to predict the location of an object in an image. Deep learning is a powerful ML technique in which the object detector automatically learns image features required for detection tasks. Several techniques for object detection using deep learning are available such as Faster R-CNN, You Only Look Once (YOLO), and Single Shot Detection (SSD). We will discuss more them ahead.
But let’s try to understand a little more about Deep Learning and CNN first.
What is Deep Learning?
Deep learning is a subset of machine learning, which is essentially a neural network with three or more layers. These neural networks attempt to simulate the behavior of the human brain - but are still far from matching its ability - allowing it to learn from large amounts of data. This is also shown in the image below.
For example, let’s say that we had a set of photos of different pets, and we wanted to categorize them by cat, dog etc. Deep learning algorithms can determine which features (like ears) are most important to distinguish each animal from another. They can remember these features and later use them to classify which of these animals is present in an image. While a neural network with a single layer can still make approximate predictions, additional hidden layers can help to optimize and refine for accuracy.
Generally, a large number of labeled images are given to the machine. By looking at pixels (or groups of pixels) in each image it learns distinguishing features for each object from those images. Later, when a new image is given to the machine, it refers to what it has learned earlier and uses those learnings to identify the objects present in that image. Suppose we want to train for a car, we’ll provide the machine with thousands of images of cars, so it can learn what are the unique features of cars (like shape) and later identify cars in unseen images.
So, a Deep Learning model generally comprises the following steps:
- Create Training Data for Object Detection: This includes collecting and pre-processing large amounts of data (like images) to feed to the Deep Learning model.
- Create Object Detection Network: This includes selecting, optimizing, or creating a Deep Learning based Object Detection Network/Model according to our needs (like Faster-RCNN or YOLO)
- Train Detector and Evaluate Results: This includes training the model on the data provided and verifying the performance of our model on a test data
There are various Deep Learning algorithms present like Convolutional Neural Networks (CNNs), Long Short Term Memory Networks (LSTMs), and Recurrent Neural Networks (RNNs). In this blog, we’ll focus on CNNs only.
What are Convolutional Neural Networks?
CNNs, also known as ConvNets, consist of multiple layers and are mainly used for image processing and object detection. Yann LeCun developed the first CNN in 1988 when it was called LeNet. It was used for recognizing characters like ZIP codes and digits.
CNNs have multiple layers that process and extract features from data. A CNN can take in an input image, assign importance (learnable weights and biases) to various aspects/objects in the image and differentiate one from the other. The preprocessing required in a CNN is much lower as compared to other classification algorithms.
With the revival of deep learning, convolutional neural networks have been applied to the object detection problem resulting in significantly increased performance. We’ll discuss a few such methods in the next section.
Object Detection using CNNs
Although many CNN-based methods are proposed for the task of object detection like SSD and R-CNN (whose other variants are Fast-RCNN and Faster-RCNN). But YOLO (You Only Look Once) remains one of the most popular and widely used methods for object detection.
Let’s discuss these methods one by one.
Faster R-CNN
Faster R-CNN is now a canonical model for deep learning-based object detection. It helped inspire many detection and segmentation models that came after it. Unfortunately, we can’t really begin to understand Faster R-CNN without understanding its own predecessors, R-CNN and Fast R-CNN, so let’s take a quick dive into its ancestry.
1. R-CNN: R-CNN, or Region-based Convolutional Neural Network, consists of 3 simple steps:
- Scan the input image for possible objects using an algorithm called Selective Search
- Run a convolutional neural net (CNN) on top of each of these region proposals
- Take the output of each CNN and feed it into a) an Support Vector Machine (SVM) algorithm to classify the region and generate the bounding box of the object if such an object exists.
The three steps are also shown in the image below:
In other words, we first propose regions, then extract features, and then classify those regions based on their features. In essence, we have turned object detection into an image classification problem. R-CNN was very intuitive but very slow.
2. Fast-RCNN: R-CNN’s immediate descendant was Fast-R-CNN. Fast R-CNN resembled the original in many ways, but improved its detection speed through two main augmentations:
- Performing feature extraction over the image before proposing regions, thus only running one CNN over the entire image instead of 2000 CNNs over 2000 overlapping regions
- Replacing the SVM with a softmax layer, thus extending the neural network for predictions instead of creating a new model. So, Now we only have one neural net to train, as opposed to one neural net and many SVMs.
So, the new model looked something like this:
Fast R-CNN performed much better in terms of speed. There was just one big bottleneck remaining: the selective search algorithm for generating region proposals.
3. Faster-RCNN: The main insight of Faster R-CNN was to replace the slow selective search algorithm with a fast neural net. Specifically, it introduced the region proposal network (RPN). In a sense, Faster R-CNN = RPN + Fast R-CNN. Faster R-CNN achieved much better speeds and state-of-the-art accuracy. The flow of the Faster-RCNN algorithm can also be understood using the image below.
Faster R-CNN may look complicated, but its core design is the same as the original R-CNN: hypothesize object regions and then classify them. This is now the predominant pipeline for many object detection models.
Single-Shot-Detector (SSD)
SSD provides enormous speed gains over Faster-RCNN. While Faster-RCNN performed region proposals and region classifications in two separate steps. First, they used a region proposal network to generate regions of interest; next, they used either fully-connected layers or position-sensitive convolutional layers to classify those regions. SSD does the two in a “single shot”, simultaneously predicting the bounding box and the class as it processes the image.
SSD sounds straightforward, but training it has a unique challenge. With the previous two models, the region proposal network ensured that everything we tried to classify had some minimum probability of being an “object.” With SSD, however, we skip that filtering step.
We classify and draw bounding boxes from every single position in the image, using multiple different shapes, at several different scales. As a result, we generate a much greater number of bounding boxes than the other models, and nearly all of them are negative examples. Hence, accuracy decreased in SSD.
YOLO
YOLO is extremely fast and accurate.
Prior detection systems repurpose classifiers or localizers to perform detection. They apply the model to an image at multiple locations and scales. High-scoring regions of the image are considered detections. YOLO uses a totally different approach. A single neural network is applied to the full image.
This network divides the image into regions and predicts bounding boxes and probabilities for each region. CNN is used to predict various class probabilities and bounding boxes simultaneously. These bounding boxes are weighted by the predicted probabilities. This can be visualized using the below image.
The YOLO algorithm employs convolutional neural networks (CNN) to detect objects in real-time. Prediction in the entire image is done in a single algorithm run. The YOLO algorithm also consists of various variants. Some of the common ones include tiny YOLO and YOLOv3.
Such classification algorithms, after being trained, can help the autonomous vehicle identify objects like vehicles, pedestrians or other obstacles in real-time and avoid potential collisions. Although, one disadvantage of CNN-based methods is that they require a huge amount of data to be trained on.
One of the most complex objects to detect and track in any traffic scene are pedestrians, because of their huge range of complex motions and interaction with other pedestrians. The pose of a person can provide important information to the autonomous vehicle about the behavior and intention. Hence, human pose estimation is also an essential task in autonomous vehicles. We have discussed this briefly in the next section.
Human Pose Estimation
The pose estimation problem is challenging since the pose space is very large, and typically, people can only be observed at low resolutions because of their size and distance from the vehicle. Several approaches have been proposed to jointly estimate the pose and body parts of a person. An example is given in the image below.
Traditionally, a two-staged approach was used by first detecting body parts and then estimating the pose. One such approach was given by Gkioxari and his team, where each of the parts is a poselet and a separate template is used to learn the appearance of each part. This is problematic in cases when people are in proximity to each other because body parts can be wrongly assigned to different persons.
Pishchulin, with his team, later presented DeepCut, a model that jointly estimates the poses of all people in an image. The formulation is based on partitioning and labeling a set of body-part hypotheses obtained from a CNN-based part detector. The model jointly infers the number of people, their poses, spatial proximity, and part-level occlusions which greatly helped enhance its performance.
Another difficult task is to detect and classify traffic signs, because of their small size, different placements around the road, similarity in looks with one another, and complex backgrounds. We have discussed more traffic sign detection in the next section.
Traffic Sign Detection
Reliable detection and recognition of traffic signs are essential for autonomous vehicles to follow all traffic rules and drive safely. An example of this is given in the image below.
One of the best-performing traffic sign detectors was proposed by Yang and his team. They adapted Faster-RCNN to the traffic sign detection task by extracting region proposals in a coarse-to-fine fashion. First, an Attention Network (AN) is used to roughly locate and classify ROIs into three categories according to the color feature of the traffic signs. Then, the finer Region Proposal Network produces the final region proposals. This helps them achieve more accurate and fast results.
Although, current object detection algorithms, especially with deep learning, yield high accuracy, and that too at very fast speeds. Still, there are several challenges that might arise, we will discuss a few in the next section.
Challenges
The detection task in urban areas is tough because of the wide variety of object appearances and occlusions caused by other objects or the object of interest itself.
Also, reliable pedestrian detection is particularly difficult because of their complex, highly varying motion and the large variety of appearances due to different clothing and articulated poses.
Furthermore, the interaction of pedestrians with each other and the world often causes partial occlusions. An autonomous vehicle needs a flawless pedestrian detection system that is robust against all weather conditions and efficient for real-time detection.
So, partially occluded objects, distant objects, or small and complex objects like pedestrians or traffic signs are the most common sources of errors. Another major issue is the lack of data for several objects and not being able to cover all possible scenarios in the data.
Summary
Object detection is an essential task for self-driving cars to understand their surroundings and drive safer. With the introduction of Deep Learning, the task of object detection has shown significant growth in terms of speed and accuracy.
But still, several challenges remain. The pedestrian and cyclist detection task is more challenging. One reason for this is the limited number of training examples and the possibility of confusing cyclists and pedestrians which differ only via their context and semantics.
The recognition of small objects and heavily obstructed objects continue to be major problems. Crowds of pedestrians, groups of bicycles, and parked cars are major causes of errors since they obstruct the view and prevent all systems from detecting certain objects. Furthermore, the limited amount of image data available for distant objects continues to make them difficult for current technologies to detect.
Another area that needs more attention is enhancing accuracy in poorly lit areas or times of day and during bad weather when vision is poor.
Constant research is going on and we are closer to realizing the dream of self-driving cars than ever now. It would not take very long since we get to see some of the first self-driving cars, but it would probably take at least a decade more before they become a common sight.