

Heart Disease Prediction Using Machine Learning


Table of Contents
Introduction
Heart disease is the leading cause of death globally, claiming millions of lives each year, presenting a significant challenge to hospitals and doctors. Early detection and intervention are crucial in preventing and managing this condition. In recent years, machine learning techniques have emerged as a powerful tool in the fight against heart disease, allowing the development of accurate and efficient models for heart disease prediction.
In this blog, we will be predicting whether a person has heart disease or not using the Kaggle Dataset. We will be using the logistic regression algorithm to build our machine-learning model.
Build ML Model
1) First, we will be importing the required libraries.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score2) Next, we will be reading the dataset (CSV file) using the Pandas library.
df_heart= pd.read_csv("heart.csv")
df_heart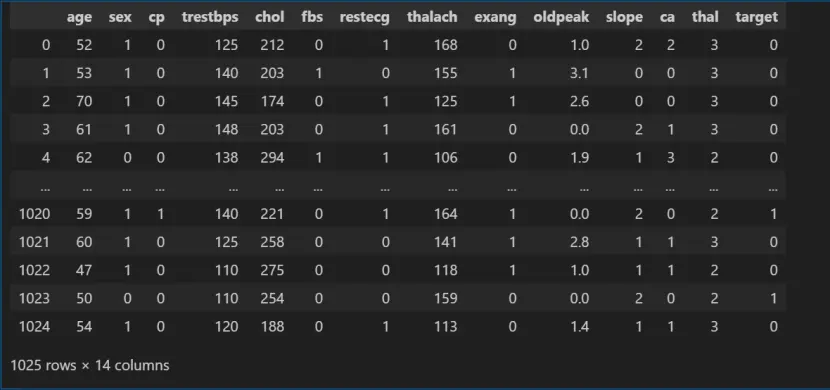
3) Now, we will be checking the features and the data type for each feature present in the dataset.
df_heart.info()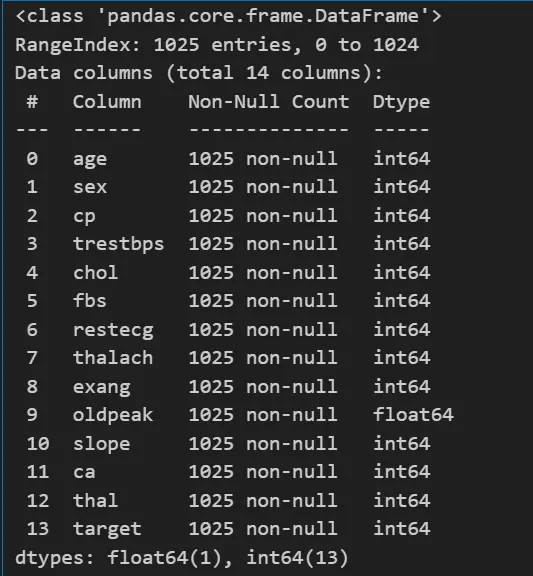
In the dataset, we have 14 features like age , gender, CP (chest pain), cholesterol, blood sugar, etc., and all of them have integer datatypes.
4) Now we will do data preprocessing. For this, let’s check if the dataset contains any null values or not.
df_heart.isnull().sum()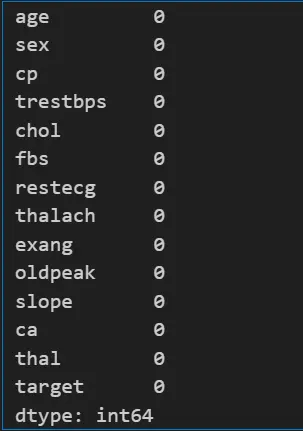
Our data does not contain any null values, as shown in the above image.
5) Let’s visualize the features and find out the correlation between the target variable and other features.
plt.figure(figsize=(20, 10))
sns.heatmap(df_heart.corr(), annot=True)
plt.show()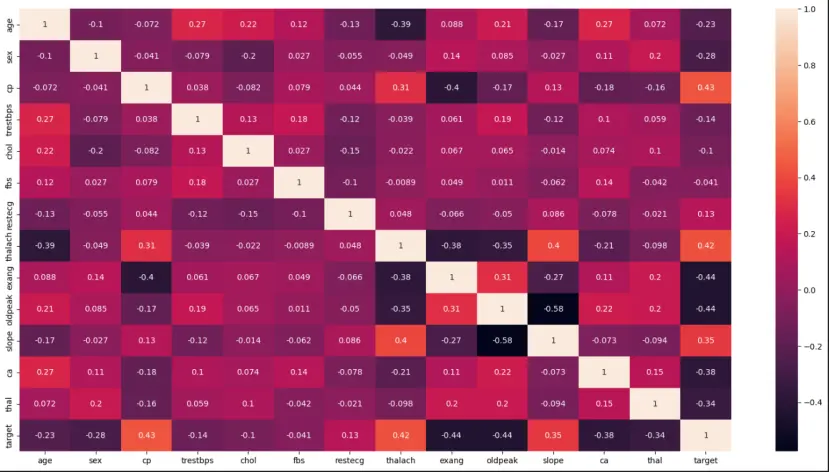
We can see from the correlation matrix that many features, such cp have a positive correlation, meaning that if one feature increases, then the target variable also increases.
6) Let’s check the count of our target variable. X represents the features or independent variables, and Y represents the target variable or dependent variable.
df_heart['target'].value_counts()
X = df_heart.drop(columns='target', axis=1)
Y = df_heart['target']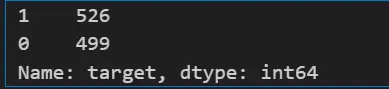
Here, 1 represents a defective heart, and 0 represents a healthy heart.
7) Now let’s split our dataset into a 75:25 train and test ratio.
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.25,random_state = 42)8) We will be training the model using logistic regression.
model = LogisticRegression()
model.fit(X_train, Y_train)9) Now we will be predicting the accuracy of our model and printing the classification report
from sklearn.metrics import accuracy_score, classification_report
pred_X_train = model.predict(X_train)
accuracy_train = accuracy_score(pred_X_train, Y_train)
print('Accuracy on Training data:', accuracy_train)
pred_X_test = model.predict(X_test)
accuracy_test = accuracy_score(pred_X_test, Y_test)
print('Accuracy on Test data:', accuracy_test)
print('Classification Report:')
print(classification_report(Y_test, pred_X_test))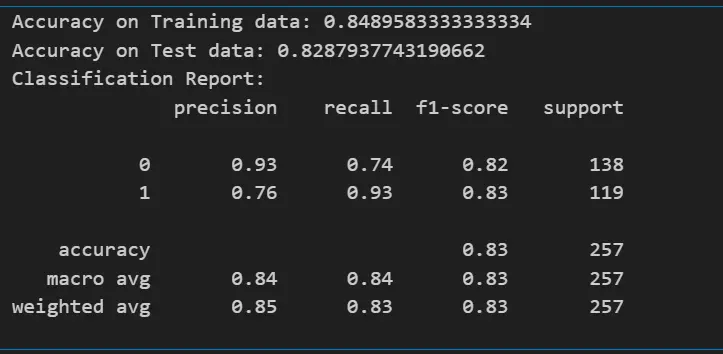
From the above report, we can conclude that our model has achieved an accuracy of 82%.
Conclusion:
In conclusion, machine learning can predict heart disease and can be really helpful for doctors and patients. By looking at lots of information about people’s health, like their age, blood pressure, and other factors, we can make predictions about who might get heart disease. In the future, doctors can use different machine learning algorithms to identify people who are at risk of heart disease at an early stage.
Frequently Asked Questions
Q1) What is heart disease prediction using machine learning?
Heart disease prediction using machine learning involves using various algorithms like logistic regression, support vector machines (SVM), and random forests to analyze data related to a person’s health and predict their risk of developing heart disease.
Q2) Why is predicting heart disease important?
Predicting heart disease is important because it allows for early detection and treatment, thus preventing serious complications or even death. Early identification allows the person to change their lifestyle, and proper medical treatment can also mitigate heart disease.
Q3) What kind of data is used for heart disease prediction?
Data used for heart disease prediction typically includes various factors such as age, sex, blood pressure, chest pain, and other medical conditions. All the data present is in numerical format.

Simplify Your Data Annotation Workflow With Proven Strategies
Download the Free Guide