

Future Trends in Image Annotation


Image annotation involves adding labels to images to facilitate AI and machine learning model training. Typically, human annotators use specialized tools to mark images, attaching relevant information, such as assigning specific classes to various entities within an image. The resultant structured data is then utilized to train a machine learning algorithm, a process commonly known as model training.
To illustrate, you might instruct annotators to label vehicles in a given set of images. This annotated data becomes instrumental in training a model capable of recognizing and distinguishing vehicles from pedestrians, traffic lights, or potential obstacles on the road, enabling safer navigation.
One prominent image annotation application is in computer vision, particularly in areas like autonomous driving.
In this blog, we discuss the potential in Image annotation. We discuss various aspects, including Integrating AI in Image Annotation, Real-Time Image Annotation, Emerging Trends in 3D Image annotation, and Enhanced Data Augmentation with Image Annotation.
Table of Contents
- Integrating AI in Image Annotation: The Future
- Annotating 3D Data: Emerging Trends
- Enhanced Data Augmentation with Image Annotation
- Conclusion
- Frequently Asked Questions
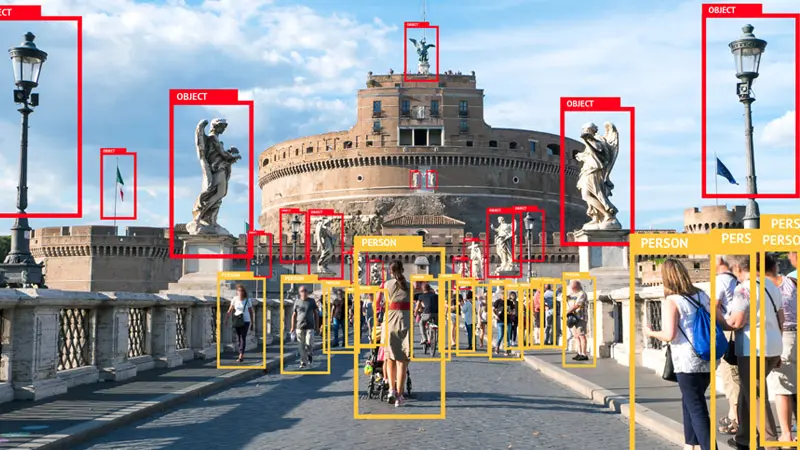
Figure: Image Annotation
Integrating AI in Image Annotation: The Future
Automatic Data Labeling, also known as auto-labeling, refers to the process of assigning data annotations using machines rather than human annotators. This can involve heuristic methods, machine learning models, or a combination of both.
Heuristic methods follow predefined rules set by human experts, allowing for cost-effective and efficient labeling. However, these rules may become outdated or inaccurate over time, impacting labeling accuracy.
Machine learning techniques, including programmatic labeling, transfer learning, few-shot learning, active learning, AutoML (Automated Machine Learning), and uncertainty estimation, aim to enhance the efficiency and cost-effectiveness of data annotation.
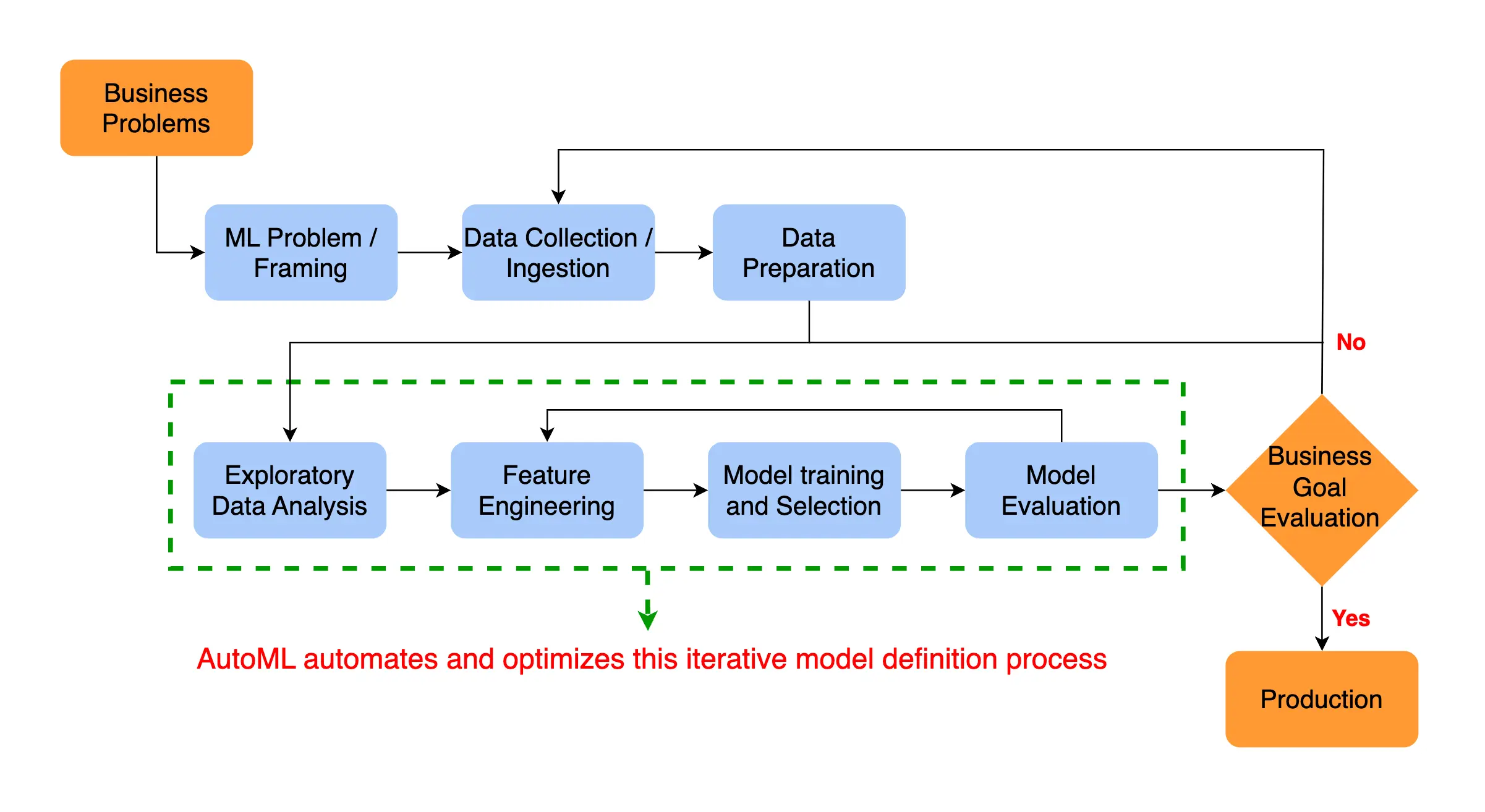
Figure: Auto Machine Learning
Programmatic labeling involves the use of labeling functions and scripts, enabling a more scalable and reusable approach.
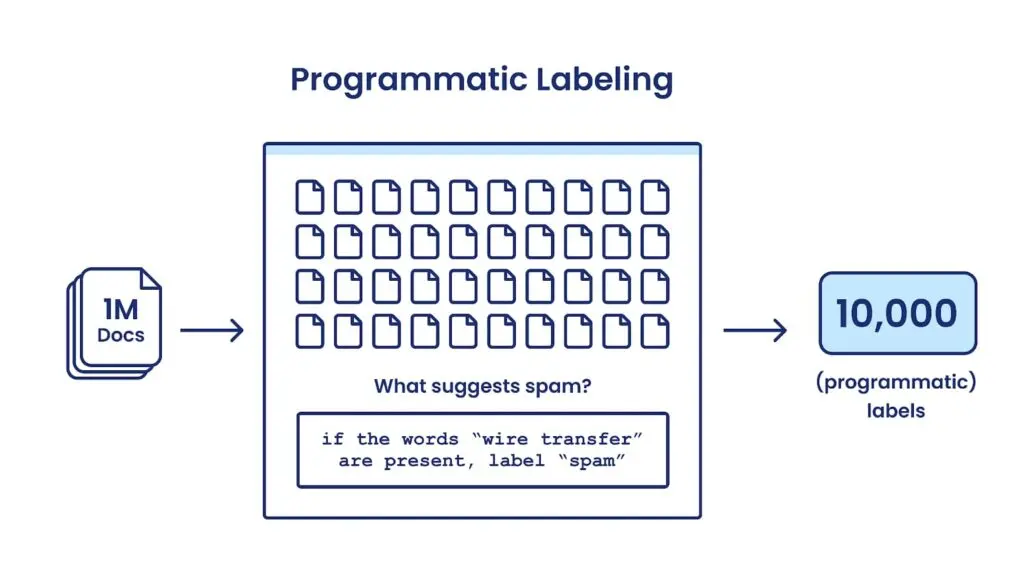
Figure: Programmatic Labelling
Transfer learning leverages pre-trained models for new tasks, reducing the time and data needed for training. Few-shot learning allows training with a minimal amount of data. Active learning algorithms assist human labelers in selecting optimal datasets.
AutoML automates the training and testing of ML models without human intervention. Uncertainty estimation enables models to express confidence in their predictions and helps identify data that may require human review for errors.
These advanced techniques contribute to streamlining the data annotation process, making it more efficient and adaptable to changing requirements.
Annotating 3D Data: Emerging Trends
3D annotation involves the labeling of three-dimensional data, such as point clouds, considering depth, distance, and volume. This annotation is commonly applied using cuboids, and in some cases, voxels (3D pixels) are utilized for semantic segmentation.
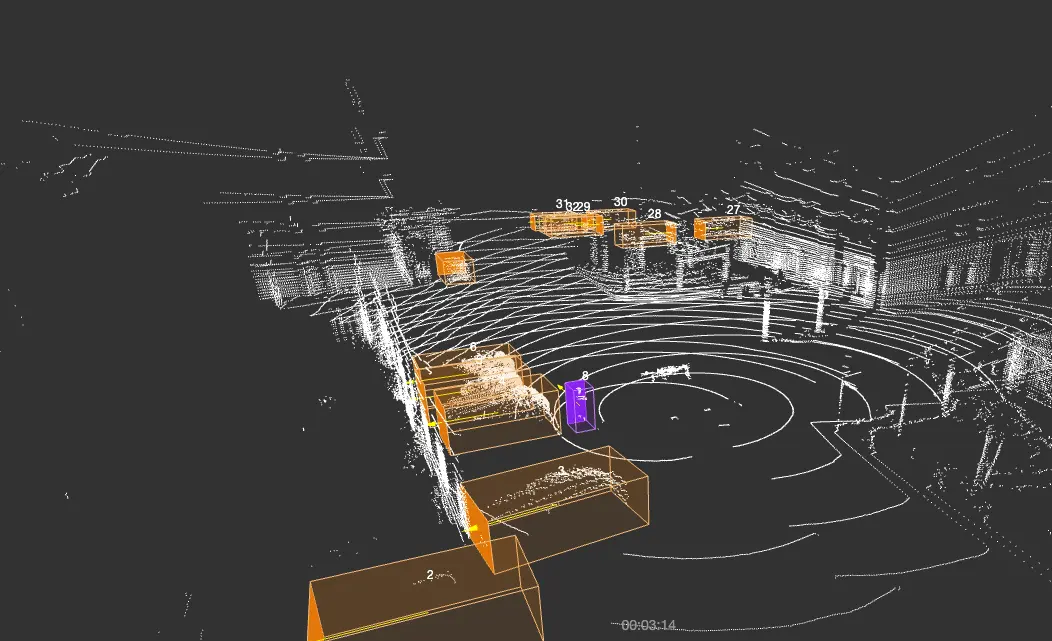
Figure: 3D point Cloud Annotation
Where can 3D annotation be used?
3D annotation finds applications across various industries due to its ability to incorporate depth and volume perception, offering valuable insights in scenarios where 2D visual data is insufficient. Although more challenging than annotating 2D data, it is employed in diverse sectors:
- Medical: Analyzing 3D scans like CTs and MRIs.
- Geospatial: Detecting 3D structures in Synthetic-Aperture Radar imagery.
- Automotive: Tracking vehicles in LiDAR point cloud data.
- Industrial: Detecting anomalies in 3D scans of products.
- Agriculture: Enabling harvesting robots for fruit picking.
- Retail: Detecting gestures and poses for VR and AR applications.
The Pros
It takes into consideration additional dimensions, providing more valuable information, especially in challenging conditions affecting 2D data (e.g., fog, darkness, occlusion).
3D annotations can be approximated on 2D data effectively, such as segmenting sequences of DICOM slices or estimating cuboids on flat images based on perspective.
The Cons
It requires considerable time and advanced tools capable of handling large volumes of data. Further, LiDAR data precision diminishes as objects move farther away from the source, impacting annotation quality.
LiDAR: Annotating 3-Dimensional Images
LiDAR (Light Detection and Ranging) is a remote sensing technology employing lasers to gauge distances and produce accurate three-dimensional details regarding the form and attributes of nearby objects.
These systems find application in various fields such as autonomous vehicles, aerial mapping, surveying, environmental monitoring, and more. They prove particularly advantageous in scenarios demanding precise and detailed information about object shapes and positions.
Enhanced Data Augmentation with Image Annotation
The advancement of computer vision is primarily driven by the success of deep learning techniques, specifically those utilizing Convolutional Neural Networks (CNN). However, the effectiveness of these neural networks heavily depends on ample training data to prevent issues like overfitting and subpar model performance.
Unfortunately, in many practical scenarios, such as real-world applications, obtaining a sufficient amount of training data poses a significant challenge due to limitations and high costs.
In this section, we look into Data Augmentation, a solution within the data-space domain, addressing the issue of restricted data in computer vision. Explore how data augmentation can enhance the performance of AI models, particularly in situations with limited and small datasets.
What Is Data Augmentation?
Data augmentation comprises a set of methods designed to amplify the size and quality of training datasets in machine learning, facilitating the training of more robust deep learning models. This involves artificially expanding datasets through label-preserving transformations of the data.

Figure: Image Augmentation Examples
What Are Popular Data Augmentation Techniques?
Image augmentation techniques includes a variety of algorithms, including geometric transformations, color space augmentation, kernel filtering, image blending, random erasing, feature space augmentation, adversarial training, generative adversarial networks (GAN), meta-learning, and neural style transferring.
- Geometric Transformations: Altering the spatial characteristics of images, including rotation, scaling, and flipping.
- Color Space Augmentation: Adjusting color-related features, such as brightness, contrast, and saturation.
- Kernel Filtering: Applying filters to images to emphasize or suppress specific features.
- Mixing Images: Combining multiple images to create new training instances.
- Random Erasing: Randomly removing parts of an image to force the model to focus on other features.
- Feature Space Augmentation: Modifying abstract features within images.
- Adversarial Training: Introducing adversarial examples during training to enhance robustness.
- Generative Adversarial Networks (GAN): Using GANs to generate synthetic data.
- Meta-Learning: Incorporating meta-learning techniques for improved adaptation.
- Neural Style Transferring: Applying artistic styles from one image to another.
Points to Remember
Below, we have mentioned key points about Data Augmentation, which, in general, benefits the ML Models for Image Annotations.
Reduces Overfitting
Data augmentation is a powerful technique to mitigate overfitting, where a model performs well on training data but struggles with unseen data. It achieves this by providing a more comprehensive set of possible data points during training, improving the model's generalizability.
Artificially Inflate the Original Dataset
Data augmentation directly addresses overfitting by expanding the training dataset. This is achieved through augmentations like geometric transformations, color adjustments, random erasing, adversarial training, and neural style transfer. These transformations preserve the labels, ensuring the integrity of the annotated information.
Conclusion
In conclusion, image annotation is a crucial process for enhancing AI and machine learning models by adding labels to images, allowing for effective model training.
Human annotators use specialized tools to mark images, attaching pertinent information such as specific classes to entities within the images. This structured data is then employed in training machine learning algorithms, particularly in the field of computer vision, with applications like autonomous driving.
The integration of AI in image annotation through Automatic Data Labeling and advanced machine learning techniques like programmatic labeling, transfer learning, and uncertainty estimation, is paving the way for more efficient and cost-effective data annotation processes.
Emerging trends in 3D image annotation, despite posing challenges, offer valuable insights in various industries, including medical, geospatial, automotive, industrial, agriculture, and retail.
Additionally, the use of LiDAR for annotating 3D images is instrumental in applications requiring precise details about object shapes and positions. Furthermore, the synergy of enhanced data augmentation with image annotation addresses the challenges of limited training data in computer vision, providing methods to expand datasets for more robust deep learning models artificially.
Popular data augmentation techniques, including geometric transformations, color space augmentation, and adversarial training, contribute to reducing overfitting and inflating the original dataset.
These advancements collectively shape the future of image annotation, offering solutions to complexities in real-world applications and promising increased efficiency, accuracy, and adaptability in training AI models.
Frequently Asked Questions
1. What is the future for Data Annotation
What lies ahead for data annotation? In 2023 and beyond, the future is characterized by increased automation and efficiency. The ongoing development of automation tools and platforms is set to streamline the work of annotators, diminishing the time and effort needed for data labeling.
One such Automated Platform for Image Annotations, which I personally prefer is Labellerr.
2. What are the advantages of Data Annotation?
Advantages of employing image annotation services in various contexts include the assurance that products convey accurate information and are appropriately categorized, enhancing search relevance for product recommendations. Additionally, image annotation contributes to the improvement of visual search capabilities.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
