

Everything You Need To Know About Vision Language Models (VLMs)


Table of Contents
- What are Vision Language Models?
- VLMs vs. LLMs: Distinctive Comparison
- The Internet's Bias: A Challenge for VLMs
- What are Domain-specific Large Vision Models (VLMs)?
- Industry Applications of Domain-Specific Large Vision Models (VLMs)
- Conclusion
- Frequently Asked Questions
What are Vision Language Models?
From analyzing static images to generating dynamic video content, large vision models can transform a simple textual description into a rich visual narrative, enabling the creation of automated video summaries from sports events based on live commentary.
VLMs which stands for "Large-Vision Models" are sophisticated AI models that combine the capabilities of large language models (LLMs) with visual understanding to interpret, analyze, and generate information from both textual and visual inputs.
VLMs leverage deep learning techniques to understand and process vast volumes of data, encompassing text, images, and other visual information.
VLM's key capabilities include:
Language Understanding: Similar to LLMs, VLMs can understand, generate, and manipulate textual information, enabling tasks like language translation, content creation, and chatbot interactions.
Visual Recognition: VLMs possess the capability to analyze and interpret images, recognizing objects, scenes, emotions, or any information conveyed visually. This allows them to generate descriptions of images, classify visual content, and even predict aspects related to the visual data they process.
Applications: VLMs find applications in diverse fields such as artificial intelligence, computer vision, natural language processing, healthcare (like analyzing medical images for cell counting or disease identification), and various industries where interpreting both language and visual data is crucial.
Training Techniques: These models can be trained using methodologies like Visual Prompting, where users guide the model's output by presenting visual patterns or images that the model has been trained to recognize and respond to in specific ways.
Examples of Language-Visual Models (VLMs)
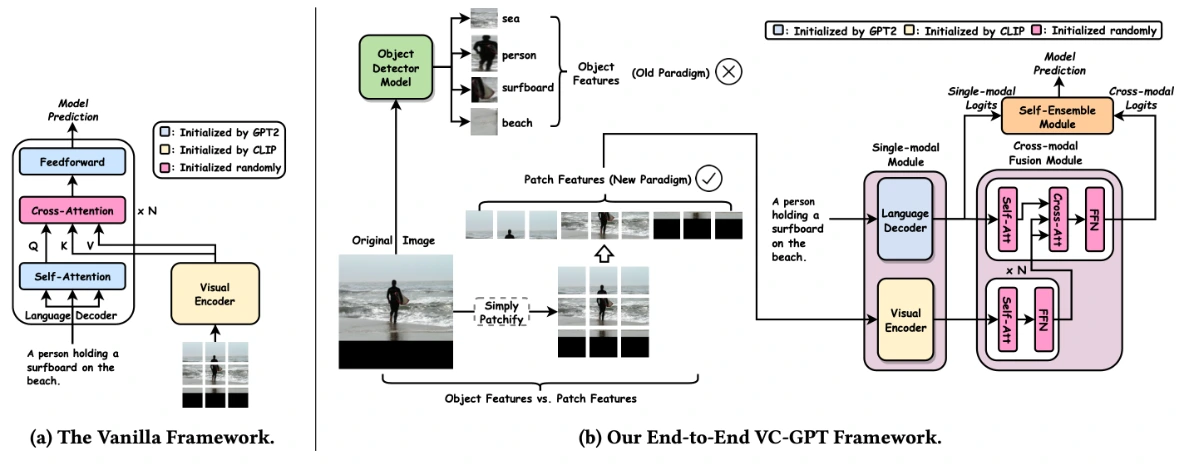
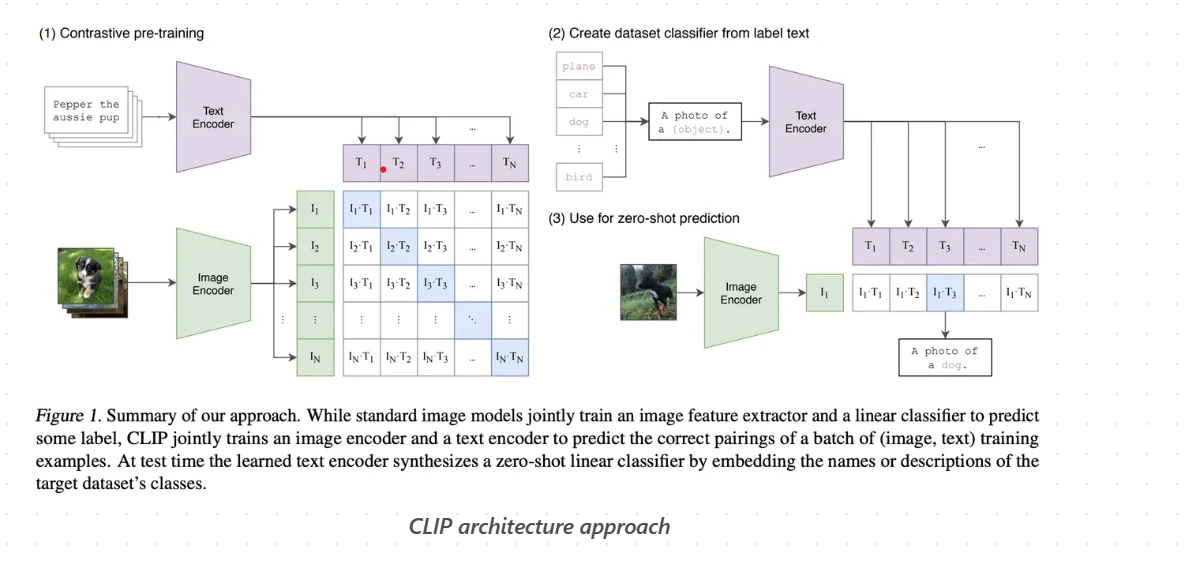
(i) CLIP (Contrastive Language–Image Pretraining): Developed by OpenAI, CLIP is a model that combines vision and language, specifically trained to understand images parallel to natural language.
(ii) Google’s Vision Transformer (ViT): Also known as ViT, this model focuses on image classification using a transformer-based architecture. It breaks down images into fixed-size patches, embeds them linearly, adds position embeddings, and processes the resulting sequence of vectors through a standard transformer encoder. This model has been trained on an extensive 22 billion parameters.
(iii) LandingAi: Their primary product, LandingLens, aims to democratize computer vision. It offers an intuitive platform enabling users to swiftly create customized computer vision projects. Users can directly upload images into LandingLens, annotate objects within the images, train the model, assess its performance, and deploy it on cloud services or edge devices.
VLMs vs. LLMs: Distinctive Comparison
VLMs and LLMs share a foundational connection but diverge significantly in their application and efficacy. LLMs have achieved immense success in understanding and producing textual content by training extensively on copious amounts of internet-based text data.
Their proficiency hinges on a critical point, the similarity between internet text and various forms of proprietary documents. This similarity enables LLMs to adapt and effectively understand a broad spectrum of textual content.

On the other hand, VLMs extend beyond the domain of textual data. They fuse the capabilities of understanding language with the interpretation of visual information.
While LLMs excel in text-based comprehension and generation,VLMs specialize in processing both language and visual data concurrently. Their unique strength lies in their capacity to interpret and generate content based on combined textual and visual inputs, making them versatile in tasks requiring comprehension and analysis of both text and images.
In essence, LLMs focus on text-centric tasks, drawing their efficacy from vast textual datasets, while VLMs, with their dual expertise in language and visual comprehension, cater to applications that demand a holistic understanding of both textual and visual information.
The Internet's Bias: A Challenge for VLMs
There exists a fundamental divergence between VLMs and LLMs due to the dissimilar nature of online text and images. Unlike the relatively consistent structure and vocabulary found in online text, internet images present a diverse and heterogeneous assortment. This disparity poses a significant challenge for LVMs trained exclusively on generic internet images.
Consider a VLM trained on millions of Instagram photos, primarily depicting people, pets, landmarks, and everyday objects. While this exposure proves valuable for general image recognition tasks, it may not effectively translate to specialized applications. Such a VLM might encounter difficulties in discerning intricate details in medical images or identifying minute defects in manufacturing equipment due to its reliance on generalized image data.
This disparity emphasizes the necessity for domain-specific VLMs. These specialized models play a pivotal role in overcoming the limitations of generic image training by focusing on distinct domains such as healthcare or manufacturing.
By training on specific datasets tailored to these domains, these VLMs enhance their capability to comprehend and interpret intricate details within specialized visual contexts.
What are Domain-specific Large Vision Models (VLM)?
Domain-specific Vision Language Models (VLM) cater to specific industries or applications by focusing on a designated domain during their training. These models are adept at recognizing subtle nuances, patterns, and anomalies unique to that field, offering enhanced performance and accuracy compared to generic VLMs, which lack the depth of understanding required for specialized tasks.

Generic VLMs vs Domain-specific VLMs
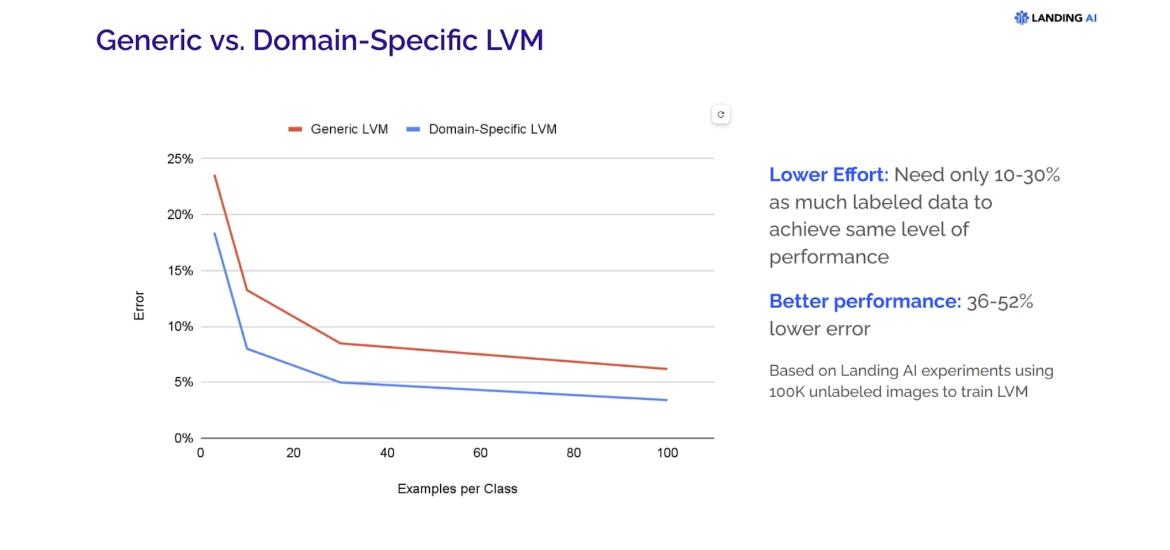
Generic VLMs, trained on diverse internet images, provide a foundational understanding of visual data but might struggle with domain-specific intricacies. In contrast, domain-specific VLMs, honed through training on domain-relevant datasets, exhibit superior performance by efficiently recognizing and interpreting visual content specific to that sector or industry.
They require less labeled data and deliver heightened accuracy, making them invaluable for tasks in healthcare, manufacturing, finance, automotive, and other specialized domains.
Industry Applications of Domain-Specific Vision Language Models (VLMs)
(I) Healthcare
Diagnostic Imaging: VLMs proficiently analyze medical scans like X-rays, CT scans, and MRIs, enhancing early detection of abnormalities for timely treatment.
Surgical Assistance: VLMs contribute to developing surgical robots, enabling precise procedures with minimal human intervention.

(II) Retail and E-commerce
Product Recommendations: VLMs analyze product images to suggest similar items, boosting sales and enriching the shopping experience.
Visual Search: VLMs enable customers to find comparable products online by capturing images using smartphones.
(III) Manufacturing and Industry
Quality Assurance: VLMs ensure product quality by detecting defects, guaranteeing only top-tier products reach customers.
Predictive Maintenance: Analyzing machinery images, VLMs forecast potential failures, allowing preemptive maintenance to avert production disruptions.
(IV) Security and Surveillance
Object Detection: VLMs identify threats like weapons or explosives in security camera footage, enhancing safety and security measures.
Facial Recognition: Utilizing VLM in security cameras aids in identifying individuals for law enforcement or access control purposes.

(V) Agriculture
Crop Health Monitoring: VLMs analyze crop images to detect diseases and pests, enabling proactive measures to protect crops.
Weed Management: Identifying weeds in fields helps farmers efficiently target them with herbicides, minimizing damage to crops.

(VI) Entertainment
Special Effects: VLMs contribute to creating life-like special effects in movies and video games, enhancing visual experiences.
Virtual Reality: VLMs elevate virtual reality experiences by making them more immersive and engaging.
(VII) Education
Visual Learning: Students engage with images and utilize VLMs to inquire and learn about various subjects, fostering interactive learning experiences.
Accessibility Tools: VLM-based tools aid visually impaired individuals in accessing information otherwise inaccessible to them.

(VIII) Automotive
Autonomous Vehicles: VLMs are pivotal in developing self-driving cars, enabling a comprehensive understanding of surroundings such as trees, lane markers, signs, etc. for safe navigation.
Traffic Management: VLMs analyze traffic patterns for real-time adjustments, improving traffic flow and signal management.
Conclusion
In conclusion, VLMs have made significant strides in the field of artificial intelligence. VLMs represent a remarkable fusion of visual perception and language understanding, pushing the boundaries of what machines can understand and create.
As these models continue to advance, they promise to unlock new possibilities in AI, from enhancing multimedia experiences to revolutionizing content creation and beyond. The future of ss is not only about technological innovation but also about its potential to reshape industries, redefine human-machine interactions, and contribute to the betterment of society.
The journey from vision to action is just beginning, and the implications of these developments are as exciting as they are profound.
Frequently Asked Questions
1.What are Large Vision Models?
Large Vision Models (VLMs) are advanced AI systems that process and interpret vast amounts of visual data, such as images and videos. They combine the capabilities of vision and natural language processing to understand and generate content that bridges the gap between visual perception and linguistic expression.
By leveraging a significant number of parameters, LVMs can learn complex patterns in visual data, leading to a deeper understanding of the visual world and its correlation with textual information.
2. What is an example of a Large Vision Model?
An example of a Large Vision Model is OpenAI’s CLIP (Contrastive Language–Image Pretraining). CLIP is a neural network that has been trained on a diverse range of images and text captions.
It excels at understanding and describing the content of images in a manner that resonates with natural language descriptions. This model is capable of performing various vision tasks, including zero-shot classification, by interpreting images within the context of natural language
3. How do Large Vision Models differ from traditional computer vision models?
Unlike traditional computer vision models that primarily focus on image recognition and object detection, VLMs integrate language processing to provide context and understanding that align with human perception. They can handle complex tasks like visual question answering, image captioning, and even creating narratives from visual data.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
