

Pre-trained models: how it speed up data annotation and when to use it effectively


Are you someone who is looking for ways to fasten up your data annotation procedure?
As computer vision technologies continue to quickly proliferate throughout industries, the demand for annotated data only increases. To implement computer vision with the help of machine learning in any project, freshly annotated training data is required to train a model. But working with new datasets requires extra time and effort. But if we can tell you that you can fasten your data annotation process with pre-trained models. Want to know more about it, read the complete blog.
Table of Contents
- What is a Pre-Trained Model?
- How are Pre-Trained Models Used?
- How Can You Adjust Your Model?
- Pre-Trained Models as an Aid in Training and Learning
- Some Cases Where You Can Use Pre-Trained Models
- How Data Annotation Platforms/Tools Will Help You Fasten Your Data Annotation Process?
What is a pre-trained model?
A pre-trained model is, simply, a model developed by someone else to address a comparable issue. You can start with the model that has been trained on another problem rather than creating a new model from the start to address a comparable problem.
If you wanted to create a self-learning automobile, for instance. You can spend many years creating effective image detection algorithms from start or you can use Google's Inception model, which was constructed using data from ImageNet to recognize images in those photographs.
How are pre-trained models used?
What is one’s aim when they are training a neural network?
They want to use numerous forward and reverse iterations to determine the network's proper weights. So that, they can easily use the parameters and the generated structure and apply the knowledge to the problem statement by employing pre-trained models that have already been trained on sizable datasets. Transfer learning is the term for this. They "transfer the learning" from the trained model to the particular problem that one is trying to solve.
When deciding on a pre-trained model to utilize in your situation, one should exercise extreme caution. Predictions made using a pre-trained model would be extremely inaccurate if the issue statement at hand differs significantly from the one used to train it. In order to recognize objects, for instance, one cannot utilize a model that has been trained for voice recognition.
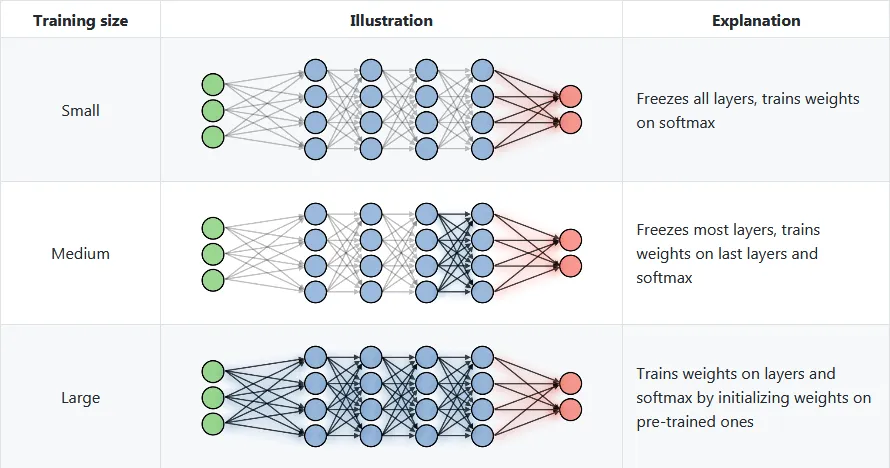
How can you adjust your model?
Perform Feature Extraction- A pre-trained model can be used as a mechanism for feature extraction. In order to use the complete network as a constant feature extractor for a fresh data set, we will need to delete the output layer, which provides probabilities for belonging to each of the numerous classes.
Utilize the pre-trained model's architecture - We can retrain the model using our datasets while using the pre-trained model's architecture to initialize all of the weights arbitrarily.
Training a few layers and freezing the other layers-Another technique to employ a model that has already been trained is to train it partially. Training some layers while freezing others. All we can do is freeze the weights of the model's first layers while only retraining the upper levels. How many layers should be frozen and trained can be experimented with?
Pre-trained models are an aid while performing Training in Learning
Transfer learning is a well-liked technique in computer vision since it speeds up the process of developing reliable models. With transfer learning, you start with structures that have been learned when addressing a different problem rather than from scratch. By doing so, you can make use of prior knowledge rather than having to start fresh.
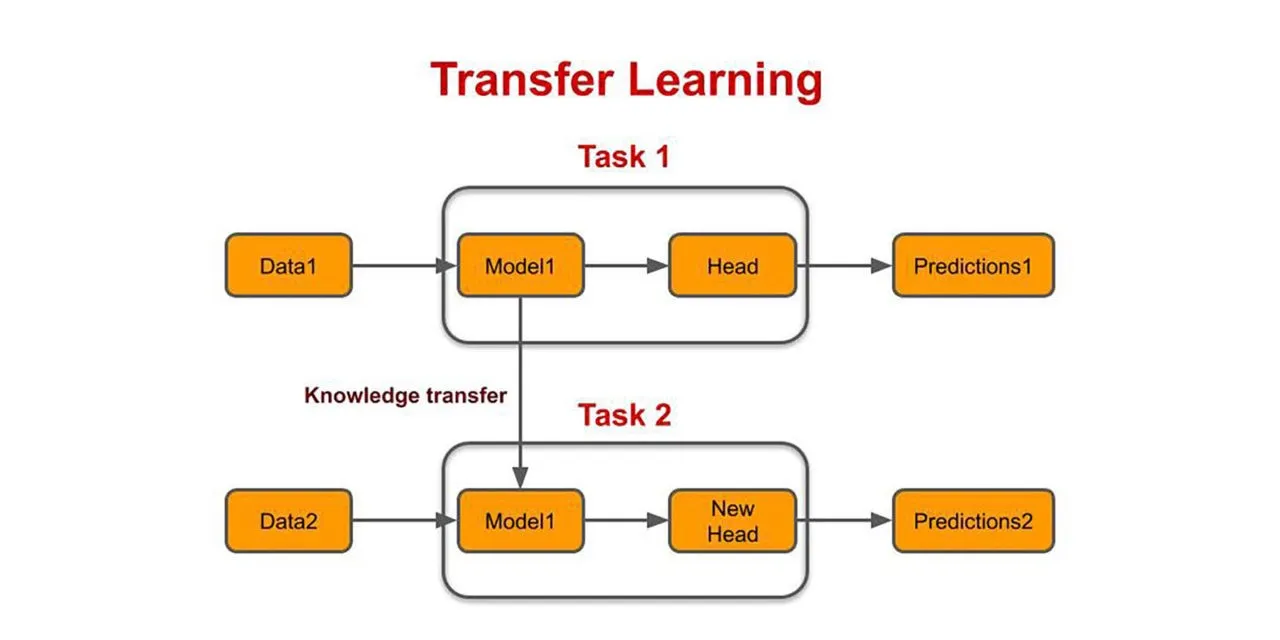
Transfer learning is typically expressed in computer vision by using trained models. A model that has already been trained on a sizable benchmark datasets to address a problem resembling the one we're trying to solve is known as a pre-trained model.
Some cases where you can use pre-trained models
Case 1: The size of the data collection is small, but there is a high degree of data similarity. In this instance, retraining the model is not necessary because of the high degree of data similarity. The output layers only need to be modified and customized to fit our problem description. The pre-trained model serves as an extractor of features for us.
Case 2: When the size of the data and the degree of data similarity are both minimal, we can freeze the first (let's say, k) levels of the pre-trained model and train the latter (n-k) layers only once. After then, the top layers will be adjusted for the new set of data.
Retraining and customizing the higher layers to the new dataset is important due to the low similarity of the new data set. The first layers are retained pre-trained (which have already been trained on a big dataset) and the parameters for all of the below layers are frozen, which makes up for the limited size of the data set.
Case 3: A huge data set with little data similarity. Given that we have a large-scale dataset, in this case, training a neural network would be successful.
However, the data we have differs greatly from the data used to train our previously trained models. Pretrained models will not successfully forecast anything. It is therefore advisable for training the neural network entirely from scratch using your data.
Case 4-The ideal circumstance is one in which the data are both huge in size and very similar. The pre-trained model ought to be the most useful in this situation.
The model's architecture and initial weights should be kept in place for optimal performance. Then, using the initialization weights from the previously trained model, we may retain this model.
How data annotation platforms/tools will help you to fasten your data annotation process?
Numerous methods and tools have been developed specifically to streamline the data (text/audio/video/image) annotation process for machine learning model training. Outsourcing annotation tasks to trustworthy and reliable suppliers is encouraged due to the value of quality performance and also the length of the full QA process.
They provide results in accordance with the requirements of the client since they are aware of what is necessary. In order to make the model easily calculate attributes, they created a training environment that was similar to the use case for the model.
Labellerr is a computer vision data annotation workflow automation tool that helps data science teams to simplify the manual mechanisms involved in the AI-ML product lifecycle. We are highly skilled at providing training data for a variety of use cases with various domain authorities.
A variety of charts are available on Labellerr's platform for data analysis. The chart displays outliers in the event that any labels are incorrect or to distinguish between advertisements.
We accurately extract the most relevant information possible from advertisements—more than 95% of the time—and present the data in an organized style. having the ability to validate organized data by looking over screens.

Simplify Your Data Annotation Workflow With Proven Strategies
Download the Free Guide