

F-VLM: Open-Vocabulary Object Detection Upon Frozen Vision And Language Models


Table of Contents
- Introduction
- Traditional Object Detection Challenges
- Understanding Vision Language Models (VLMs)
- Architecture of F-VLM
- Advantages of F-VLM
- Performance and Results
- Applications of F-VLM
- Conclusion
- FAQs
Introduction
In the rapidly evolving field of computer vision, object detection remains a fundamental yet challenging task. Traditional object detection models often require extensively annotated datasets and complex training pipelines to achieve high performance.
These models are also typically limited by a fixed vocabulary, restricting their ability to detect and classify a diverse array of objects in real-world scenarios.
F-VLM: Open-Vocabulary Object Detection Upon Frozen Vision and Language Models, a pioneering approach that leverages the power of frozen vision and language models (VLMs) to overcome these limitations.
In this blog, we will delve into the details of F-VLM, exploring its innovative methodology, impressive performance metrics, and broader applications in the field of computer vision
Traditional Object Detection Challenges
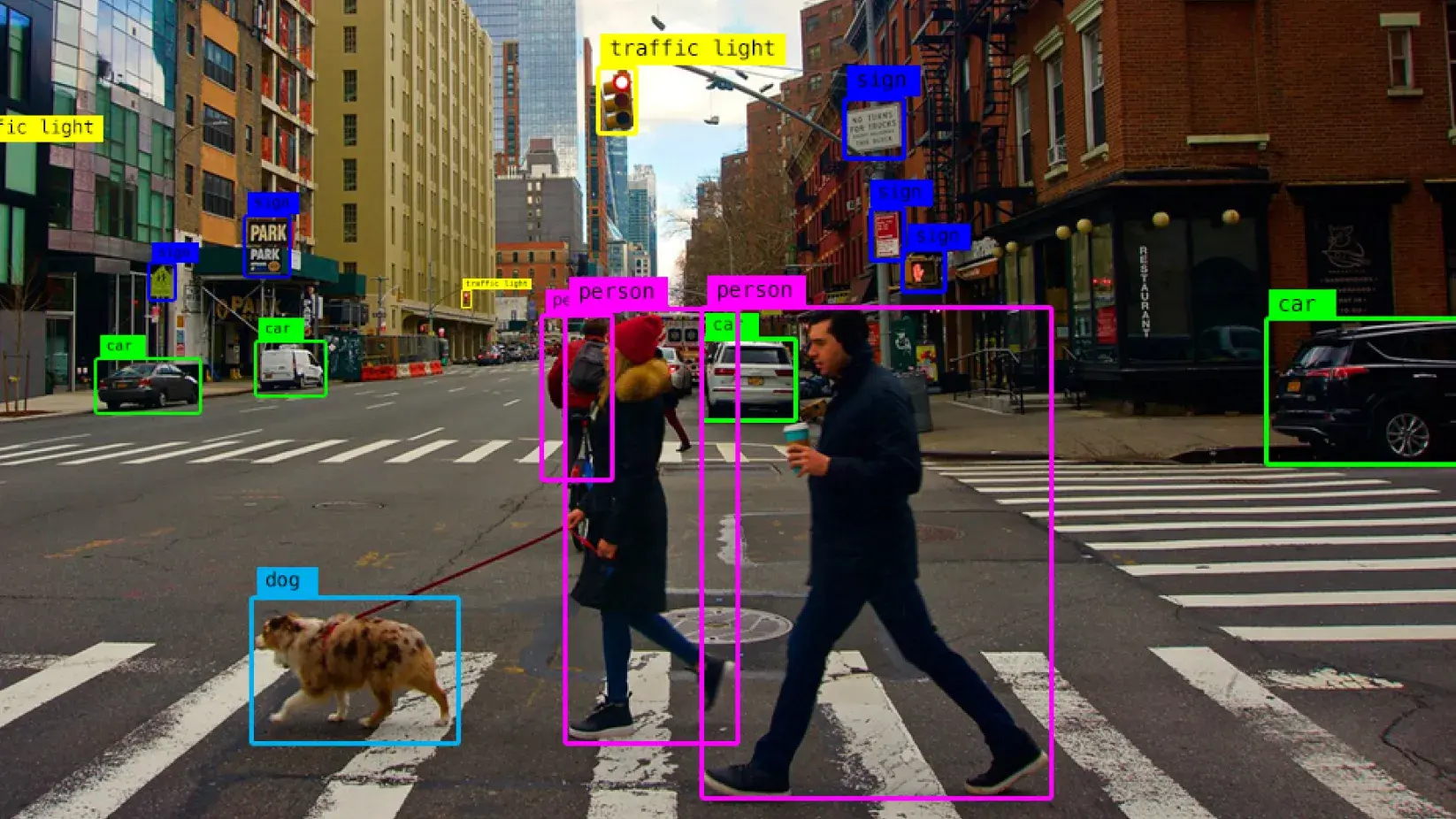
Object detection has long been a cornerstone of computer vision, enabling machines to recognize and locate objects within an image. However, traditional object detection methods come with several significant challenges:
Extensive Manual Annotation:
Traditional object detection models rely heavily on large, meticulously annotated datasets.
Creating these datasets involves significant human effort and time, as annotators must draw bounding boxes and assign labels to each object in thousands or even millions of images.
This process is not only labor-intensive but also prone to inconsistencies and errors.
Limited Vocabulary Size
Conventional object detectors are typically trained on a predefined set of object categories.
This fixed vocabulary limits the model's ability to recognize objects outside the training set, making it difficult to adapt to new or rare objects without retraining the model with additional annotated data.
Consequently, traditional models struggle with scalability and generalization to diverse real-world scenarios.
Complex Training Pipelines
The training process for traditional object detection models often involves multiple stages, including pre-training on large datasets, fine-tuning on specific tasks, and iterative refinement of model parameters.
This complexity increases the computational cost and time required to develop and deploy robust object detection systems.
Performance Trade-offs
Balancing accuracy, speed, and computational efficiency is a constant challenge in object detection. High-performance models often require substantial computational resources, making them impractical for deployment in resource-constrained environments such as mobile devices or edge computing.
Understanding Vision Language Models (VLMs)
Vision Language Models (VLMs) are advanced AI systems that integrate visual and textual data to enhance their understanding and interpretation capabilities.
These models are trained on vast datasets comprising image-text pairs, allowing them to learn the intricate relationships between visual elements and their corresponding descriptions.
By combining visual recognition with natural language processing, VLMs can perform tasks that require a deep understanding of both visual content and language, such as image captioning, visual question answering, and cross-modal retrieval.
Their ability to process and interpret multimodal data makes VLMs highly versatile and powerful tools in the field of artificial intelligence.
One of the primary advantages of VLMs is their strong generalization capabilities. Since they are trained on diverse and extensive datasets, VLMs can recognize and understand a wide variety of objects and scenes, even those not explicitly present in the training data.
This makes them particularly useful for applications requiring open-vocabulary object detection, where the model must identify and classify previously unseen objects. Additionally, VLMs retain locality-sensitive features, crucial for tasks requiring detailed spatial understanding, such as object detection and segmentation.
The integration of visual and textual information also enhances their contextual reasoning abilities, allowing VLMs to perform complex tasks that involve both modalities efficiently.
Architecture of F-VLM
The fundamental innovation of F-VLM (Frozen Vision and Language Models) lies in its approach to object detection. Unlike traditional models that require extensive retraining, F-VLM leverages the powerful capabilities of pre-trained Vision and Language Models (VLMs) by keeping their weights frozen.
This means that the VLM's parameters, which have been trained on large-scale image-text datasets, remain unchanged during the training of the object detection component.
Instead, F-VLM focuses on fine-tuning only the detector head, which is specifically designed to interpret the features extracted by the VLM and perform object detection. This strategy not only simplifies the training process but also maintains the strong visual recognition capabilities of the VLM.
Architecture
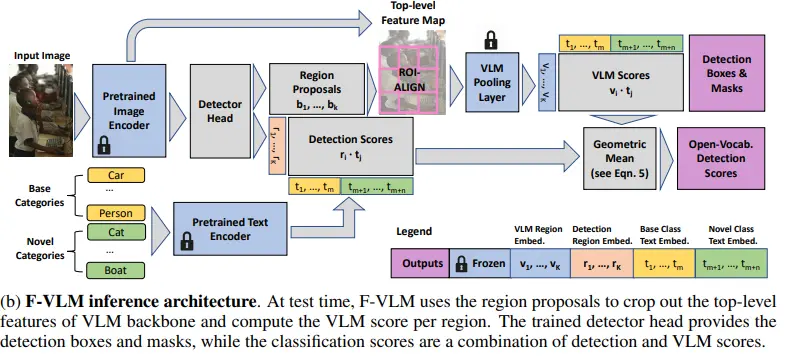
The architecture of F-VLM is designed to seamlessly integrate the frozen VLM with a specialized detector head, enabling efficient and effective object detection.
Core Components:
- Pretrained Image Encoder: This is the backbone of the model, responsible for extracting high-level features from the input image. It's typically a deep convolutional neural network (CNN) like ResNet or EfficientNet, pre-trained on a massive image dataset like ImageNet.
- Frozen VLM (Vision-Language Model): A pre-trained VLM like CLIP is used. It's kept "frozen," meaning its weights are not updated during training. The VLM is crucial for understanding the relationship between visual and textual information.
- Detector Head: This is a newly added component trained specifically for object detection. It takes the features from the image encoder and predicts bounding boxes and objectness scores for potential objects in the image.
Inference Process:
- Region Proposals: The detector head generates a set of region proposals, which are candidate bounding boxes that might contain objects.
- Feature Extraction: For each region proposal, the image encoder extracts features.
- VLM Scoring: The extracted features are fed into the frozen VLM, which calculates a similarity score between the region and each text embedding in its vocabulary. This score indicates how likely the region is to correspond to a particular object category.
- Detection Scores: The detector head also predicts objectness scores for each region proposal, indicating the likelihood that a region actually contains an object.
- Combined Scores: The final detection scores are a combination of the VLM scores and the detector head's objectness scores. This helps balance the model's ability to detect both known and novel object categories.
Advantages of F-VLM
Simplicity and Efficiency
One of the standout features of F-VLM is its streamlined approach. Unlike many other complex object detection models, F-VLM requires minimal training adjustments.
By leveraging a pre-trained Vision-Language Model (VLM) and freezing its parameters, the model significantly reduces computational costs and training time. This makes F-VLM a practical and efficient solution for various applications.
Open-Vocabulary Capability
A game-changer in the field of object detection, F-VLM excels at identifying objects that the model hasn't encountered during training. This open-vocabulary capability is a result of the VLM's ability to understand the relationship between images and text.
By combining this with a detector head, F-VLM can accurately locate and classify objects, even if they belong to previously unseen categories.
Strong Performance
Despite its simplicity, F-VLM delivers impressive results. It has consistently achieved state-of-the-art performance on several benchmark datasets for object detection.
This demonstrates the model's effectiveness in accurately detecting and localizing objects in real-world images, making it a strong contender in the field.
Performance and Results
F-VLM demonstrates impressive performance across multiple benchmark datasets, solidifying its position as a state-of-the-art solution for open-vocabulary object detection. The model has been rigorously evaluated on several prominent benchmarks, including LVIS, COCO, and Objects365, showcasing its robust detection capabilities and efficiency.
LVIS Benchmark
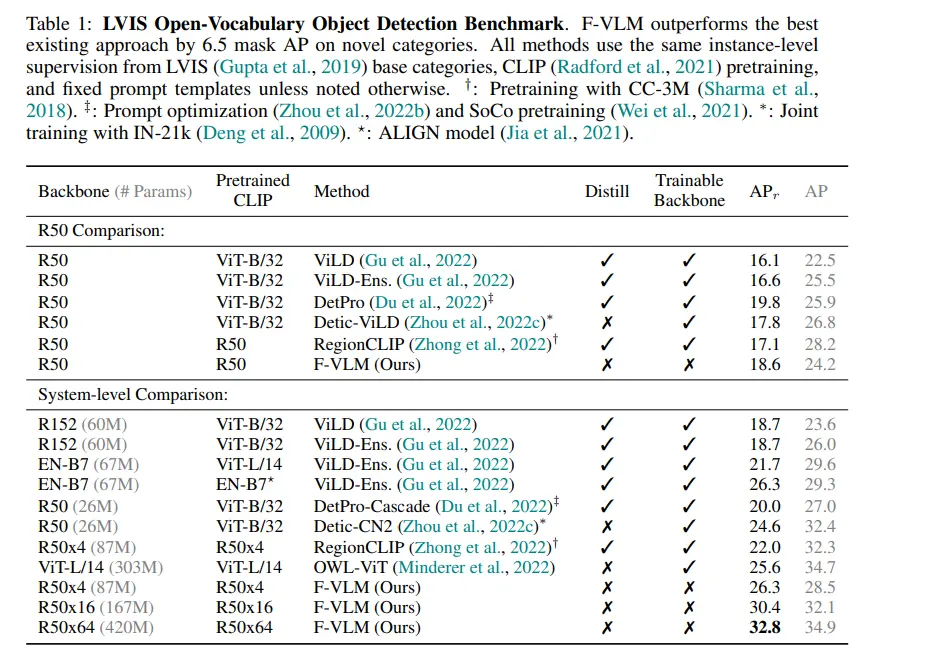
On the challenging LVIS (Large Vocabulary Instance Segmentation) dataset, F-VLM achieves remarkable improvements. The LVIS dataset is known for its extensive vocabulary and the presence of many rare and infrequent object categories.
F-VLM's ability to handle such a diverse and complex dataset is evidenced by its significant performance gains. Notably, F-VLM achieves a +6.5 mask AP (Average Precision) improvement over the previous state-of-the-art methods.
This substantial increase highlights F-VLM's effectiveness in accurately detecting and segmenting objects across a wide range of categories, including those with limited training examples.
COCO Benchmark
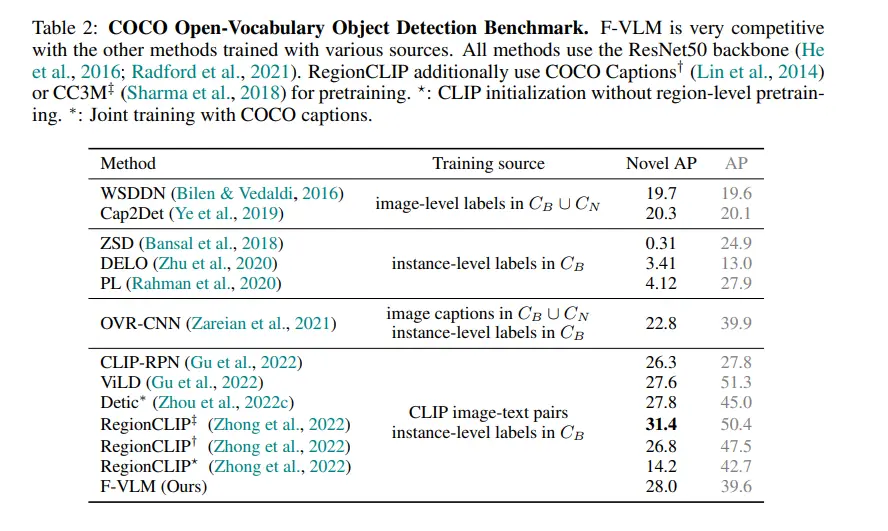
On the widely-used COCO (Common Objects in Context) dataset, F-VLM delivers competitive results, further demonstrating its versatility and robustness.
The COCO dataset contains a diverse set of everyday objects in various contexts, providing a rigorous test for object detection models.
F-VLM's strong region classification capabilities and retention of locality-sensitive features enable it to perform exceptionally well on COCO, achieving high precision and recall rates across different object categories.
Objects365 Benchmark
F-VLM's performance on the Objects365 dataset underscores its scalability and adaptability. Objects365 is a large-scale dataset with a comprehensive set of object categories and a substantial number of training images.
F-VLM leverages its frozen VLM backbone and fine-tuned detector head to handle the complexity of this dataset effectively.
The model's ability to maintain high detection accuracy and generalization across such a vast dataset demonstrates its robustness and scalability.
Cross-Dataset Transfer
F-VLM's ability to perform well on cross-dataset transfer tasks is another testament to its robustness and generalization capabilities.
The model has demonstrated competitive results when transferred to the COCO dataset, a critical benchmark for evaluating cross-dataset performance.
This capability is essential for real-world applications where models often encounter new and diverse datasets that differ from their training data.
Applications of F-VLM

Visual Question Answering (VQA)
The integration of vision and language models in F-VLM makes it an ideal candidate for Visual Question Answering (VQA) tasks.
VQA systems require an understanding of both visual content and natural language queries to provide accurate answers. F-VLM's ability to associate visual features with textual descriptions can be leveraged to develop advanced VQA systems that excel in interpreting complex scenes and answering detailed questions about them.
This has potential applications in fields such as education, customer support, and accessibility technologies.
Image Captioning
Image captioning is another area where F-VLM's capabilities can be explored. By generating coherent and contextually accurate descriptions of images, F-VLM can be used to develop systems that automatically generate captions for images, enhancing accessibility for visually impaired individuals and enabling more efficient image organization and search.
The strong visual recognition and language understanding of F-VLM can produce high-quality captions that capture the essence of the visual content.
Scene Understanding and Contextual Reasoning
F-VLM's robust feature extraction and classification abilities can contribute to improved scene understanding and contextual reasoning.
This is particularly important in autonomous systems, such as self-driving cars and robotic navigation, where understanding the context and relationships between objects in a scene is crucial for safe and efficient operation.
F-VLM's ability to generalize to new object categories and contexts enhances its utility in dynamic and unpredictable environments.
Conclusion
F-VLM (Frozen Vision and Language Models) represents a significant advancement in the field of object detection, offering a novel approach that leverages the power of pre-trained Vision and Language Models while maintaining computational efficiency.
By keeping the VLM weights frozen and fine-tuning only the detector head, F-VLM retains rich visual representations and locality-sensitive features, resulting in superior performance across a variety of benchmarks such as LVIS, COCO, and Objects365.
In summary, F-VLM's groundbreaking approach to leveraging frozen VLMs for object detection not only sets new standards in performance and efficiency but also paves the way for broader applications in the evolving landscape of computer vision.
As advancements in vision and language models continue, F-VLM's scalable and adaptable framework ensures it will remain at the forefront of innovation, driving progress in both research and practical applications.
FAQs
1. What is F-VLM?
F-VLM stands for Frozen Vision and Language Models, a novel approach to object detection that leverages pre-trained vision and language models while keeping their weights frozen. This method focuses on fine-tuning only the detector head, resulting in enhanced detection performance and computational efficiency.
2. How does F-VLM differ from traditional object detection methods?
Traditional object detection methods typically require extensive training and fine-tuning of the entire model, which can be computationally intensive and time-consuming. In contrast, F-VLM maintains the weights of the pre-trained vision and language models frozen and only fine-tunes the detector head, reducing the training complexity and computational requirements.
3. What are the main benefits of using F-VLM?
- Efficiency: By fine-tuning only the detector head, F-VLM reduces the computational resources and time needed for training.
- Performance: F-VLM retains rich visual representations and locality-sensitive features, resulting in superior detection accuracy.
- Scalability: The approach allows for easy integration of larger and more advanced vision and language models, enhancing performance without significant re-training.
- Generalization: F-VLM can generalize well to new and unseen object categories, making it suitable for open-vocabulary object detection.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
