

Exploring TRLx: Hands-on Guide for Implementing Text Summarization through RLHF

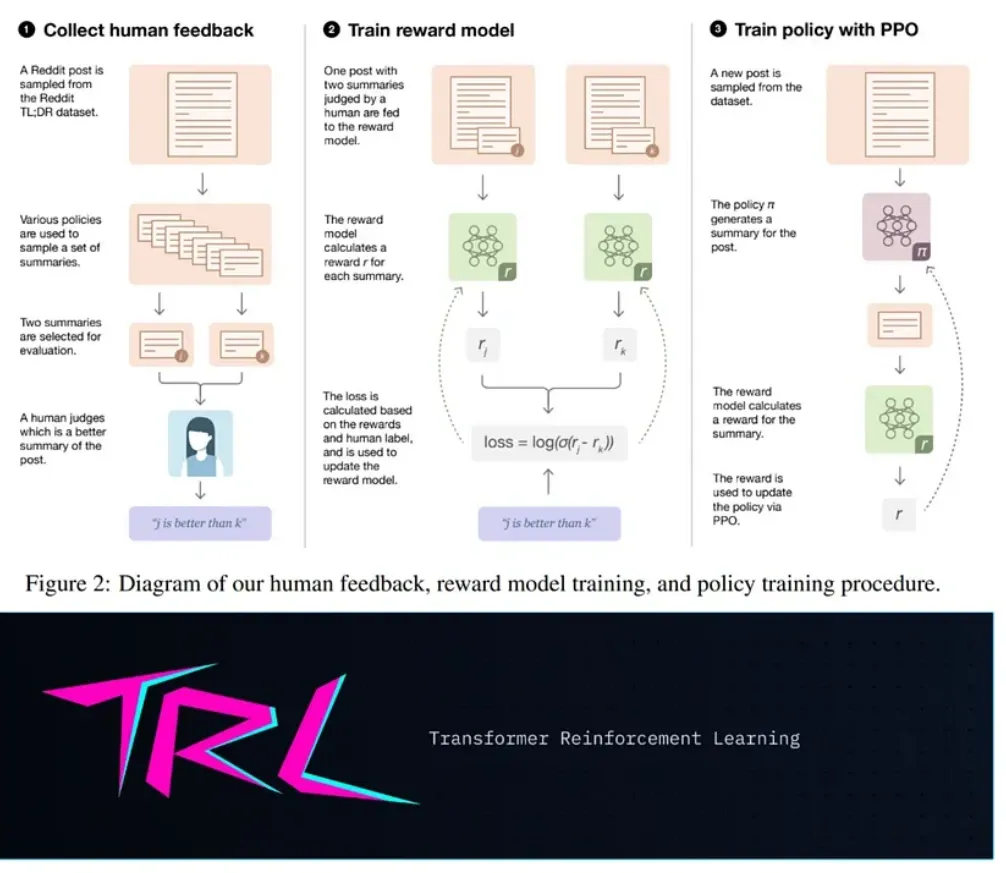
This guide provides a hands-on approach to implementing a text summarization tool utilizing the Reinforcement Learning from Human Feedback (RLHF) method.
OpenAI researchers, in their paper, 'Learning to Summarize from Human Feedback' (Stiennon et al., 2020), applied RLHF to GPT model.
This blog will explore the implementation of RLHF using TRLx.
TRLx is a recent package from CarperAI based on the Transformers Reinforcement Learning from Hugging Face.
The interest in the RLHF technique has surged within language modeling communities and beyond with the advent of OpenAI's ChatGPT.
OpenAI's paper on 'Learning to Summarize with RLHF' highlighted the suboptimal performance of fine-tuning on summarization data, advocating for the superiority of reinforcement learning based on human preferences.
This tutorial blog aims to replicate OpenAI's results using the trlX library.
TRLx, a distributed training framework inspired by the Transformer Reinforcement Learning library, focuses on RLHF at scale.
As an excellent tool for reproducing recent RLHF literature findings, trlX supports Proximal Policy Optimization (PPO) and Implicit Language Q-Learning (ILQL) algorithms.
This feature allows researchers to concentrate on high-level reinforcement learning dynamics, streamlining the process by minimizing the need for boilerplate code in distributed training.
Hands-on Guide
1. Fine-tuning a pre-trained transformer model on our summarization dataset
To initiate the process, we'll engage in fine-tuning a pre-trained transformer model specifically for text summarization.
We are using the trlX library with Hugging Face Transformers.
Our selected model for this task is the T5-small model.
T5-small stands out as a more lightweight variant of the T5 transformer model, specifically crafted for generative tasks such as summarization.
The trlX library serves as a valuable tool in this context, simplifying the fine-tuning procedure by seamlessly incorporating our custom dataset.
Noteworthy is its capability to abstract away intricate aspects of the training loop, optimization procedures, and provide a more streamlined and efficient fine-tuning experience.
import trlX
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("t5-small")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
# Load your dataset
train_dataset, val_dataset = load_summarization_datasets()
# Fine-tune the model
trainer = trlX.Trainer(
model=model,
tokenizer=tokenizer,
train_dataset=train_dataset,
val_dataset=val_dataset,
train_batch_size=8,
gradient_accumulation_steps=2,
)
trainer.train()We start by importing the required libraries and then the T5-small model and its tokenizer.
Following that, we load our personalized datasets for training and validation.
Then, a Trainer instance is formed using the trlX library.
This Trainer is given the model, tokenizer, training dataset, validation dataset, along with details like training batch size, and gradient accumulation steps.
We use the trainer.train() method for fine-tuning process.
This sequence of steps is for setting up our tools, loading our data, and then instructing our training tool (the Trainer) to start the process of making our model better for the summarization task.
2. Training a reward model
Now, we move on to creating a reward model.
This model will assist us in figuring out how good our generated summaries are during the reinforcement learning phase.
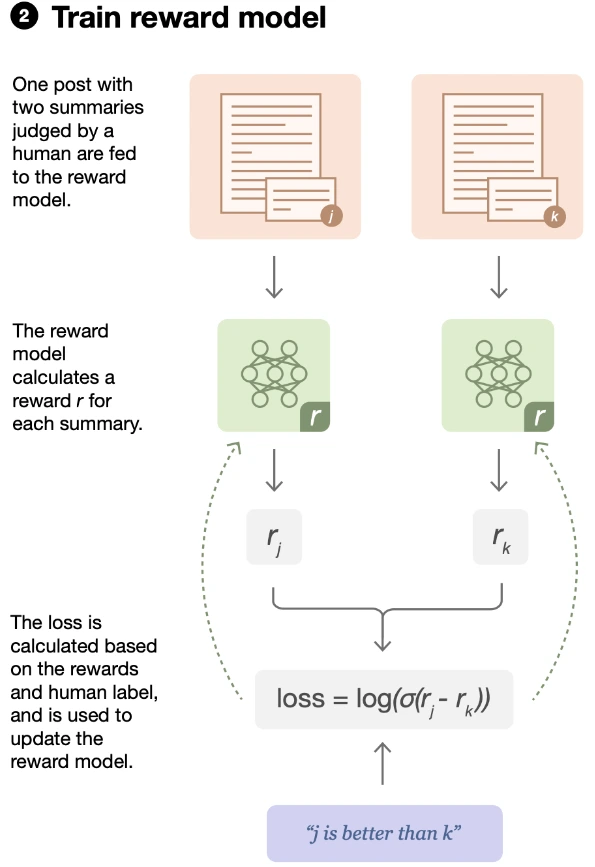
To train this reward model, we'll use the fine-tuned transformer model along with a comparison dataset.
This is where we can see how well our summaries stack up.
To make things easier, we'll rely on the trlX library for training the reward model.
It streamlines the training process to make it more straightforward and efficient.
For this step, we need a supervised dataset to teach the reward model.
To fine-tune the pre-trained supervised model, we'll use a scientific TL;DR dataset from AllenAI.
This dataset provides concise summaries, making it a solid choice for training our reward model to recognize good summaries.
from trlX.reward_model import RewardModel
from datasets import load_dataset
reward_model = RewardModel(model, tokenizer)
comparison_dataset = load_dataset("allenai/scitldr")
# Train the reward model
reward_trainer = trlX.RewardModelTrainer(
reward_model=reward_model,
train_dataset=comparison_dataset,
train_batch_size=8,
)
reward_trainer.train()In the above code, we build a RewardModel using the transformer model that we fine-tuned earlier, along with its tokenizer.
Then, we bring in the comparison dataset, which consists of pairs of summaries along with scores indicating how good they are.
To teach our reward model, we set up a RewardModelTrainer.
This trainer needs to know about the reward model we created, the dataset for comparison, and details like how many examples to process in each training batch.
RewardModelTrainer is used to show our model what makes a good summary by using examples from the comparison dataset.
3. Fine-tuning the model using PPO
We will use a method called Proximal Policy Optimization (PPO) to further refine our transformer model.
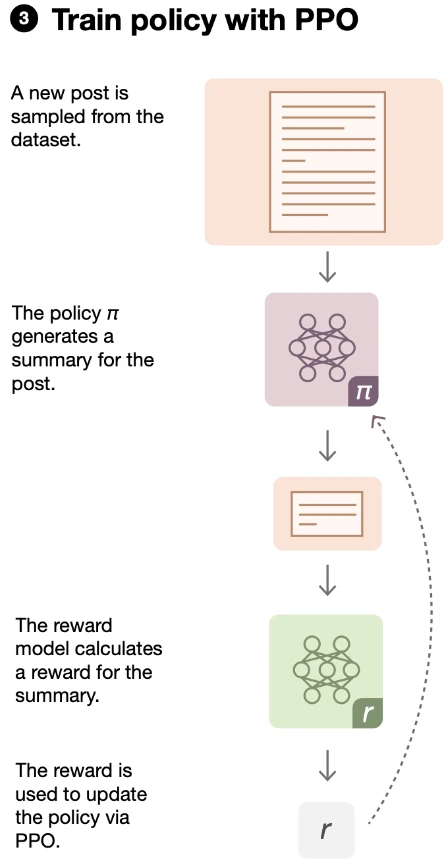
This time, we are using the reward model we trained earlier to guide our model's learning through reinforcement.
PPO is a well-known and effective algorithm in the world of reinforcement learning.
It's like a smart strategy that helps our model get better at summarizing text in challenging situations.
The trlX tool makes things even smoother and simplifies the process of applying PPO for fine-tuning text summarization models. It is because of the assistance provided by our trained reward model.
It gives our model some valuable tips on how to improve its summarization skills.
ppo_trainer = trlX.PPOTrainer(
model=model,
tokenizer=tokenizer,
reward_model=reward_model,
train_dataset=train_dataset,
train_batch_size=8,
)
ppo_trainer.train()In the code, we create an instance of the PPOTrainer class, providing it with the model assets and parameters.
The PPOTrainer will optimize the transformer model to produce better summaries depending on user choices by using the reward model as a guide during the fine-tuning process.
Lastly, we initiate the PPO-based fine-tuning procedure by calling the ppo_trainer.train() method.
Conclusion
In this blog, we saw the power of trlX to carry out Reinforcement Learning from Human Feedback (RLHF) for a summarization task, through a structured process in three key phases.
Firstly, we fine-tuned a pre-existing transformer model using our summarization dataset. This step involved enhancing the model's capabilities specifically for summarizing text.
Following that, we delved into creating a reward model, which is a crucial component that helps us understand and quantify the quality of generated summaries during the reinforcement learning process.
Lastly, we employed Proximal Policy Optimization (PPO) to further refine our model, leveraging the insights gained from the trained reward model.
We utilized the TL;DR summarization dataset from OpenAI’s "Learning to Summarize with RLHF" paper, a curated collection that serves as a reliable benchmark for our training and fine-tuning processes.
Frequently Asked Questions
1. How to implement RLHF for a summarization task?
To implement RLHF for a summarization task, follow these steps. First, fine-tune a pre-trained transformer model using a summarization dataset.
This customizes the model for summarizing text. Next, create a reward model by comparing generated summaries with quality scores using a comparison dataset.
This model helps assess the goodness of the generated summaries.
Finally, use Proximal Policy Optimization (PPO) to further improve the model based on the guidance from the trained reward model.
This process optimizes the summarization model to generate better summaries aligned with human preferences.
2. What is TRLx?
TRLx is a library that helps make implementing Reinforcement Learning from Human Feedback (RLHF) easier. It's specifically designed for tasks like text summarization.
With TRLx, you can fine-tune pre-trained transformer models, create and train reward models to evaluate the quality of generated content, and use reinforcement learning techniques, like Proximal Policy Optimization (PPO), to further refine models.
Overall, TRLx simplifies the complex process of training models for tasks like summarization, making it more accessible for developers and researchers.
3. Can RLHF be applied to GPT models?
Yes, RLHF (Reinforcement Learning from Human Feedback) can be applied to GPT (Generative Pre-trained Transformer) models.
Researchers have successfully used RLHF techniques, such as Proximal Policy Optimization (PPO), to fine-tune GPT models for specific tasks like text summarization.
By leveraging human feedback and reinforcement learning, GPT models can be optimized to generate more accurate and contextually relevant summaries based on desired preferences, showcasing the versatility of RLHF in enhancing the capabilities of GPT-based language models.
Looking for high quality training data to implement text summarization through RLHF model? Talk to our team to get a tool demo.
References
https://trlx.readthedocs.io/en/latest/index.html
https://github.com/CarperAI/trlx
https://huggingface.co/blog/rlhf
Book our demo with one of our product specialist
Book a Demo