

Evolution of YOLO Object Detection Model From V5 to V8


Introduction
Imagine you're trying to build an object detection system for an autonomous vehicle, only to find that traditional methods struggle with accuracy, speed, or both.
Imagine you're trying to build an object detection system for an autonomous vehicle, only to find that traditional methods struggle with accuracy, speed, or both.
Object detection—identifying and locating objects within images or video—has been a complex task for applications like autonomous driving, surveillance, and robotics, where precision is everything.
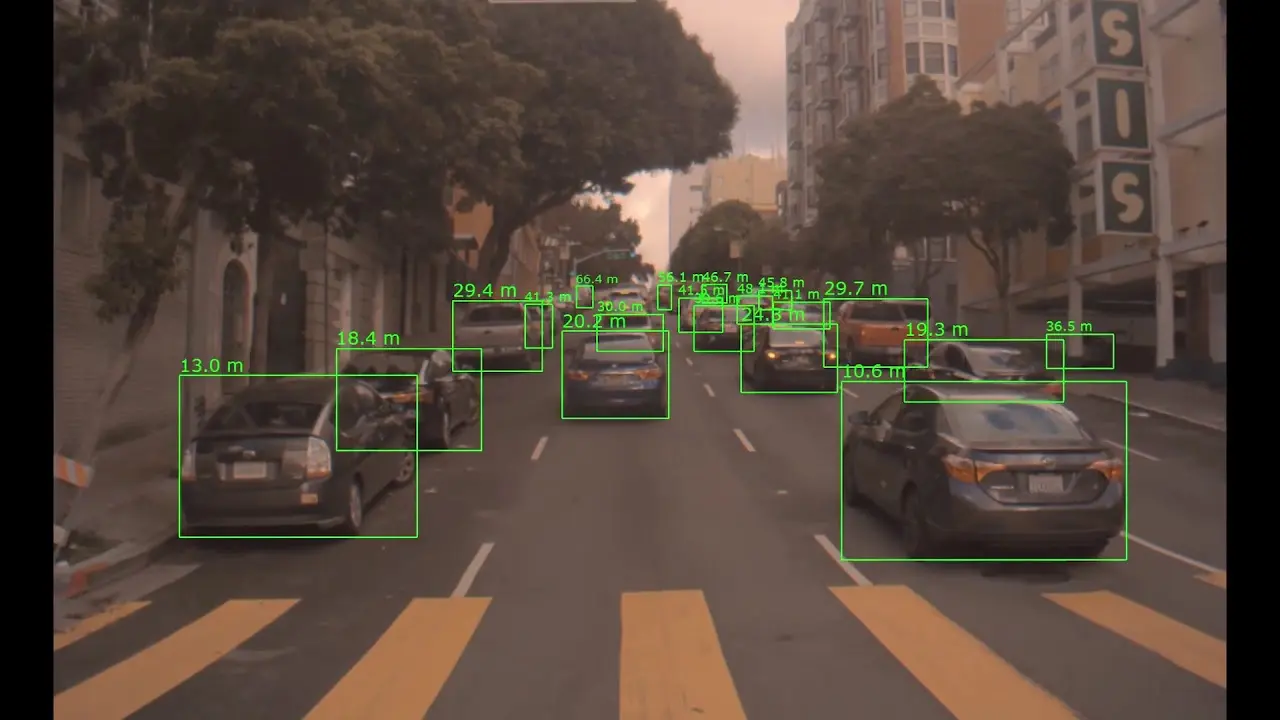
Figure: Object detection in autonomous vehicle
{kind=link}

Figure: Object detection for vehicle damage
Inconsistent lighting, overlapping objects, and high-speed environments add even more complexity, leading to a slow or inaccurate detection process that could result in costly mistakes or safety risks.
In fact, working on vision-based applications cite detection speed and accuracy as their biggest challenges.
But what if there was a solution that could speed up detection without sacrificing precision?
That’s where the YOLO algorithm comes in, continually evolving to handle these challenges better than ever.
In this blog, we’ll take you through the evolution of YOLO, from YOLOv5 to YOLOv8, to understand how each version improves detection performance.
Table of Contents
- Introduction
- YOLO: A State-of-the-Art Object Detection Algorithm
- Working of YOLO
- Comparative Study of YOLO Versions 5 to 8
- Conclusion
- Frequently Asked Questions (FAQ)
YOLO: A State-of-the-Art Object Detection Algorithm
Joseph Redmon et al. introduced the YOLO (You Only Look Once) algorithm for real-time object detection in 2016. The YOLO algorithm utilizes a single neural network for predicting the class probabilities and bounding boxes of objects in an image
Traditional object recognition algorithms have multiple steps to find objects, but YOLO only has one step to process the whole picture. This makes it faster and more efficient.
The YOLO algorithm also uses anchor boxes to improve detection accuracy and handle objects of different sizes and aspect ratios.
Since its introduction, YOLO has evolved through several versions, with each version improving upon the previous one in speed, accuracy, and functionality.
YOLOv8, which forms the latest version of the algorithm, is the fastest and most accurate YOLO model to date, and it achieves state-of-the-art evaluations on several benchmark datasets.
YOLO is widely used in various applications, such as autonomous driving, surveillance, and robotics.
Working of YOLO
The YOLO (You Only Look Once) object detection algorithm works in multiple steps. The working of YOLO can be described in the following steps:
- Input Image: The algorithm takes an image as input.
- Grid Division: The image is divided into a grid of cells. Each cell is responsible for detecting the objects that are present in it. The size of the grid depends on the input size of the image and the size of the network's last convolutional feature map.
- Feature Extraction: Each cell is passed through a convolutional neural network (CNN) to extract features. This CNN is pre-trained on a large dataset of images to learn features that can be used for object detection.
- Objectness Score: The objectness score that is predicted for each cell determines whether an item is present in a cell . This is done using a logistic regression function, which predicts the probability of an object being present in the cell.
- Class Probability: For each cell that predicts an object, YOLO predicts the class of the object and its probability. This is done using a softmax function, which computes the conditional probability of the object belonging to each class.
- Bounding Box: For each cell that predicts an object, YOLO also predicts the bounding box that encloses the object. The bounding box is anticipated about to the cell size and is represented by its center coordinates, width, and height.
- Non-Maximum Suppression: To remove redundant bounding boxes and improve the accuracy of the detections, YOLO performs non-maximum suppression (NMS) on the predicted bounding boxes. NMS removes all the overlapping bounding boxes with a lower confidence score.
- Output: YOLO's end result is a list of bounding boxes with their related class and confidence score. These boxes represent the objects that were found in the image that was given as input.
YOLO is designed to be a quick and effective object detection algorithm capable of real-time image processing.
YOLO is significantly quicker than other object recognition algorithms that make many passes over the input image because it divides it into a grid of cells and predicts the items in each cell.
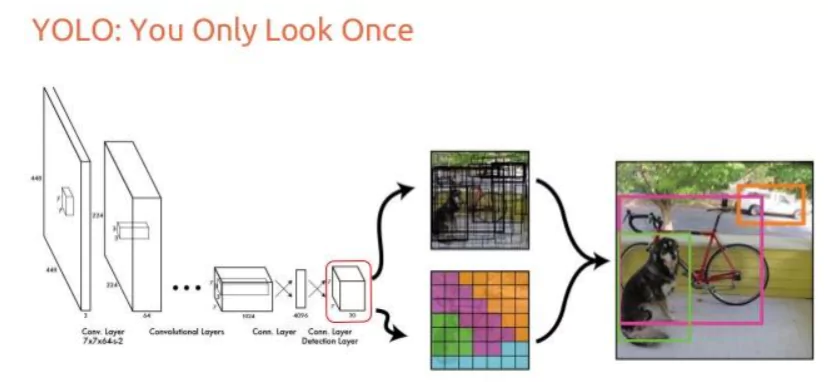
Figure: Working of YOLO architecture
YOLO operates on the entire image simultaneously, making it extremely fast and efficient. This is where the YOLOv8 differs from other object detection algorithms, which utilize a sliding window approach, which is computationally expensive.
Due to its multi-scale feature maps, YOLO can detect small objects and objects in crowded scenes.
YOLO has several versions, with YOLOv8 being the most recent and widely used. YOLOv8 has a lightweight architecture that focuses on speed and efficiency. It obtains state-of-the-art scores on several benchmarks.
It also includes several new features, such as custom anchor boxes and transfer learning, which make it easier to train and customize for specific tasks.
Comparative Study of YOLO Versions 5 to 8
Though Yolo was first introduced in 2016 (Yolov1), it is continuously improving in terms of its working accuracy, efficiency, utilization of computation resources, etc.
In this section, we will study about performances of different versions, mainly from version Yolov5 to Yolov8.
Evaluation metrics
Before diving in, it’s essential to cover a few key terms that will aid in understanding the evaluation metrics used in this comparative analysis.
- mAP: mAP (mean Average Precision) measures the accuracy of an object detection model by computing the average precision (AP) for each class of object in the dataset and then taking the mean across all classes.
- FLOPs: FLOPs estimate the number of floating-point arithmetic operations (such as addition and multiplication) that a model must perform during inference (i.e., when making predictions on new data).
- Speed (fps): In deep learning, speed FPS (frames per second) is a metric used to measure the inference speed of a model. It represents the number of input frames that the model can process in one second and is often used to evaluate the real-time performance of a model.
- params: In deep learning, "params" typically refers to the number of trainable parameters in a model. These parameters are the weights and biases of the neurons in the neural network, which are learned during training to minimize the loss function.
- Size (pixels): In YOLO (You Only Look Once), "size (pixels)" typically refers to the input size of the images used to train the model.
Analysis of Yolo v5
You Only Look Once (YOLO) is a well-known object detection system, and the fifth iteration of this algorithm is known as YOLOv5. It was developed by Ultralytics and released in 2020.
YOLOv5 is based on a similar architecture as YOLOv4 but with several improvements to its speed, accuracy, and ease of use.
One of the main improvements of YOLOv5 is its speed. It is much faster than YOLOv4 and can achieve real-time object detection at up to 140 frames per second (FPS) on a single GPU.
This is due to implementing a new feature called "SPP" (Spatial Pyramid Pooling), which reduces the number of computations required to detect objects.
Another improvement of YOLOv5 is its accuracy. It achieves state-of-the-art performance on several popular object detection benchmarks, such as COCO, PASCAL VOC, and OIDv4.
YOLOv5 also introduces a new backbone architecture called "CSPNet" (Cross-Stage Partial Network), which improves the feature extraction process and further enhances the model's accuracy.
Yolo version 5 comes in the following five versions: x, l, m, s, and n. Below, I've provided a comparison of the performance of various models of yolov5.
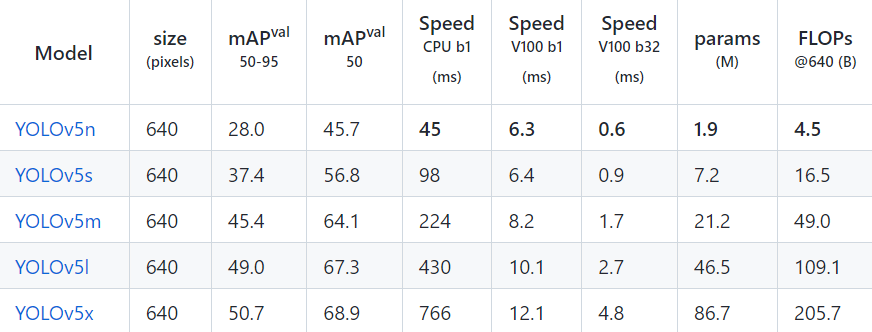
Figure: Performance metrics for Yolov5
Some points are to be noted:
- With default parameters, all checkpoints are trained to 300 epochs.
- mAPval values are for single-model single-scale on COCO val2017 dataset.
- Speed is measured using an Amazon p3.2xlarge instance with COCO val pictures. NMS timings (1 ms/image) are not included.
- Reflection and scale augmentations are both included in TTA Test Time Augmentation.
Analysis of Yolo v6
"YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications" is a research paper that proposes a new object detection framework for industrial applications.
The proposed framework is an extension of the popular YOLOv5 model. It aims to address challenges in industrial settings, such as low light conditions, occlusions, and small object sizes.
The proposed YOLOv6 model incorporates several modifications to the YOLOv5 architecture, including a novel anchor-free detection approach and a new feature pyramid network.
The anchor-free approach eliminates the need for predefined anchors, which makes the model more flexible and robust to object size variations.
The feature pyramid network enhances the model's ability to detect objects of different sizes and resolutions.
The YOLOv6 model has been evaluated against several industrial benchmarks, including the difficult D2LC dataset, after being trained on a sizable dataset of industrial objects.
The experimental results show that the proposed model outperforms other state-of-the-art object detection models on these benchmarks, demonstrating its effectiveness for industrial applications.
Below, I've attached the benchmark performance of YOLOv6 In terms of its speed, accuracy, efficiency, computation cost, etc.
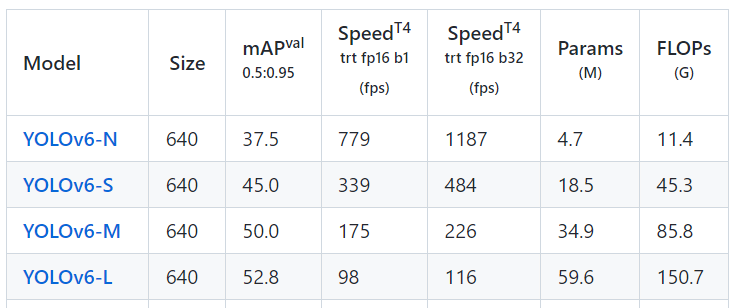
Figure: Performance metrics for Yolov6
Some points are to be noted:
- Except for the YOLOv6-N6/S6 models trained to 300 epochs without distillation, all checkpoints are trained using self-distillation.
- The mAP and speed results are evaluated on the COCO val2017 dataset with the input resolution of 640×640 for P5 models and 1280x1280 for P6 models.
- Speed is tested with TensorRT 7.2 on T4.
Analysis of Yolo v7
YOLOv7 is a real-time object detection model that achieves state-of-the-art performance by incorporating a range of "bag-of-freebies" techniques, such as AutoAugment, CutMix, and DropBlock.
These techniques are designed to improve the robustness and generalization of the model, allowing it to perform well even in challenging real-world environments.
The YOLOv7 model is based on a single-shot detector architecture and is trained end-to-end on a large dataset of annotated images.
It incorporates several advanced features, including:
- A backbone network based on the EfficientNet architecture.
- An SPP (Spatial Pyramid Pooling) module for capturing multi-scale features
- And a PAN (Path Aggregation Network) module for integrating features from different scales.
Experimental results show that YOLOv7 outperforms previous state-of-the-art object detection models on various benchmarks, including COCO and PASCAL VOC.
Moreover, the model is highly efficient, achieving real-time performance on various hardware platforms, including desktop CPUs, mobile devices, and embedded systems.
Below, I've attached the benchmark performance of YOLOv7 In terms of its speed, accuracy, efficiency, computation cost, etc.
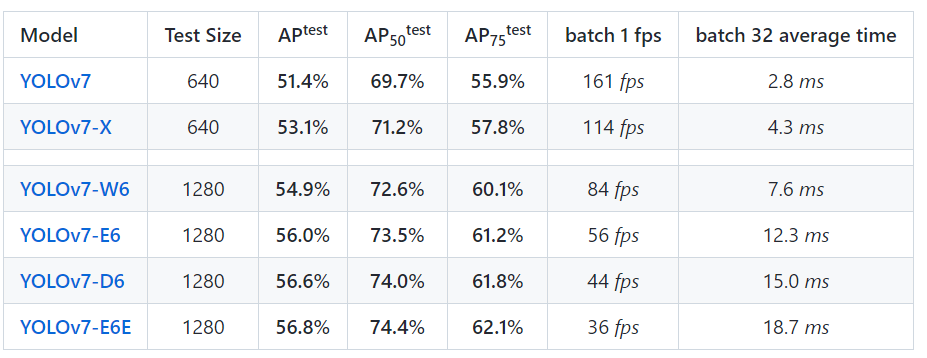
Figure: Performance benchmark for yolov7
Points to be noted:
- The mAP and speed results are evaluated on the COCO val2017 dataset with the input resolution of 640×640 for P5 models and 1280x1280 for P6 models.
Analysis of Yolo v8
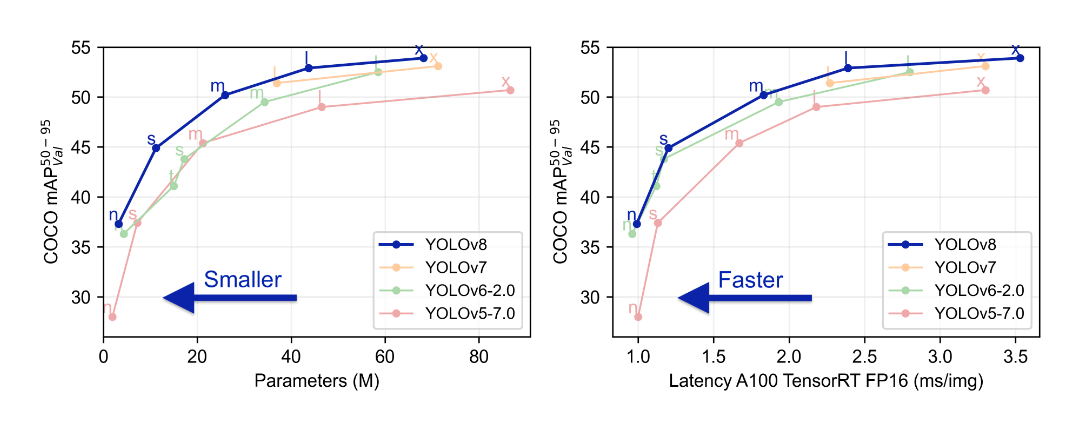
Figure: Comparison of a) Number of parameters in different versions of YOLO architecture b) Inference speed for each YOLO version
{kind=link}
YOLOv8 is an object detection model that builds on the success of previous versions of YOLO (You Only Look Once) by incorporating several key improvements.
Ultralytics, a computer vision and deep learning company develops and maintains the model.
Some of the critical features of YOLO v8 include the following:
- Improved accuracy and speed compared to previous versions of YOLO.
- An updated backbone network based on EfficientNet, which improves the model's ability to capture high-level features.
- A new feature fusion module that integrates features from multiple scales.
- Enhanced data augmentation techniques, including MixUp and CutMix.
Ultralytics YOLOv8 model, created by Ultralytics, is cutting-edge and state-of-the-art (SOTA). It builds on the success of earlier YOLO versions and adds new features and enhancements to increase performance and versatility further.
YOLOv8 is an excellent option for various object recognition, picture segmentation, and image classification jobs since it is quick, precise, and simple.
Below, I've attached the benchmark performance of YOLOv7 In terms of its speed, accuracy, efficiency, computation cost, etc.
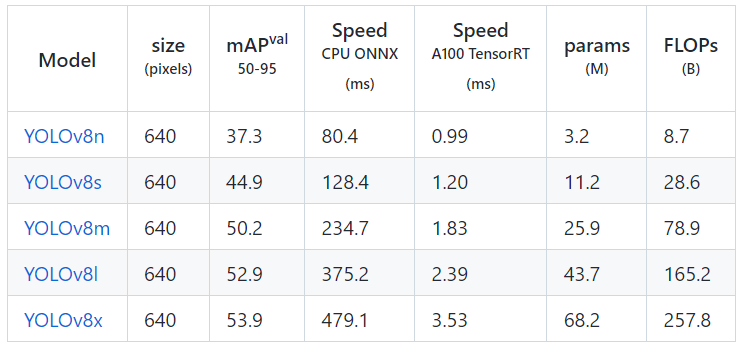
Figure: Performance benchmark for yolov7
Points to be noted:
- The COCO val2017 dataset's mAPval values are for single-model, single-scale models.
- Speed utilizing an Amazon EC2 P4d instance averaged over COCO val pictures.
- Utilized A100 Tensor RT for inferencing.
By streamlining the annotation process, Labellerr makes object detection easier. Its user-friendly interface makes labeling and annotation efficient, and its collaborative features increase output.
Accuracy and organization are improved through automated suggestions and annotation management systems. To meet the needs of various projects, Labellerr offers a range of price plans from which you can select.
Conclusion
In the above blog, we compare the performance of different YOLO (You Only Look Once) object detection models, including YOLOv5, YOLOv6, YOLOv7, and YOLOv8.
The authors conducted experiments to evaluate the models on several popular object detection datasets, including COCO, VOC, and Open Images.
Overall, the results of the experiments showed that YOLOv8 outperformed the other models in terms of accuracy, with a mean Average Precision (mAP) score of 52.8% on the COCO dataset at a speed of 60 FPS.
YOLOv8 also had a relatively low number of parameters and FLOPs, making it an efficient and scalable model.
However, we also see that the performance of the models varied depending on the specific dataset and task.
For example, YOLOv6 and YOLOv7 performed better on small object detection tasks, while YOLOv5x was faster than YOLOv8 on some datasets.
In conclusion, the authors suggested that YOLOv8 is a promising model for real-time object detection tasks but emphasized the importance of considering the specific requirements of each task when selecting a model.
They also noted that the field of object detection is constantly evolving and that future improvements in model architecture and training techniques are likely to improve the performance of these models further.
Frequently Asked Questions (FAQ)
1. What is the difference between Yolo v5 and v8?
When it comes to YOLO (You Only Look Once) models, YOLOv5 stands out for its user-friendly nature, making it easier to work with. On the other hand, YOLOv8 offers improved speed and accuracy.
If real-time object detection is a priority for your application, YOLOv8 would be the preferable option. Ultimately, the selection of the appropriate model will depend on the specific requirements and objectives of your application.
2. When was Yolo v8 released?
YOLOv8 was launched on January 10th, 2023.
3. What is Yolo for?
YOLO (You Only Look Once) has emerged as a widely adopted algorithm for object detection, bringing significant advancements to the realm of computer vision. With its impressive speed and efficiency, YOLO proves to be an exceptional solution for real-time object detection applications.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
