

Evolution of Neural Networks to Large Language Models
Explore the evolution from neural networks to large language models, highlighting key advancements in NLP with the rise of transformer models.


Introduction
Over the last few decades, language models have evolved significantly. Simple language models were utilized initially for tasks like speech recognition, machine translation, and information retrieval.
These models were built using statistical approaches, including n-gram and hidden Markov models. However, they face limitations when it comes to both accuracy and scalability, especially with more complex tasks.
Neural networks have been more popular for language modeling applications since the introduction of deep learning.
In this field, recurrent neural networks (RNNs) and long short-term memory (LSTM) networks have proved remarkably effective.
Neural network models can understand the order of words in language and create sentences that make sense. This helps them do tasks like writing and translating more accurately than older methods.
Attention-based approaches, such as the transformer architecture, have lately gained appeal. These models create output by attending to distinct sections of the input sequence using self-attention techniques.
They have been demonstrated to be highly successful in various natural language processing applications, including language modeling.
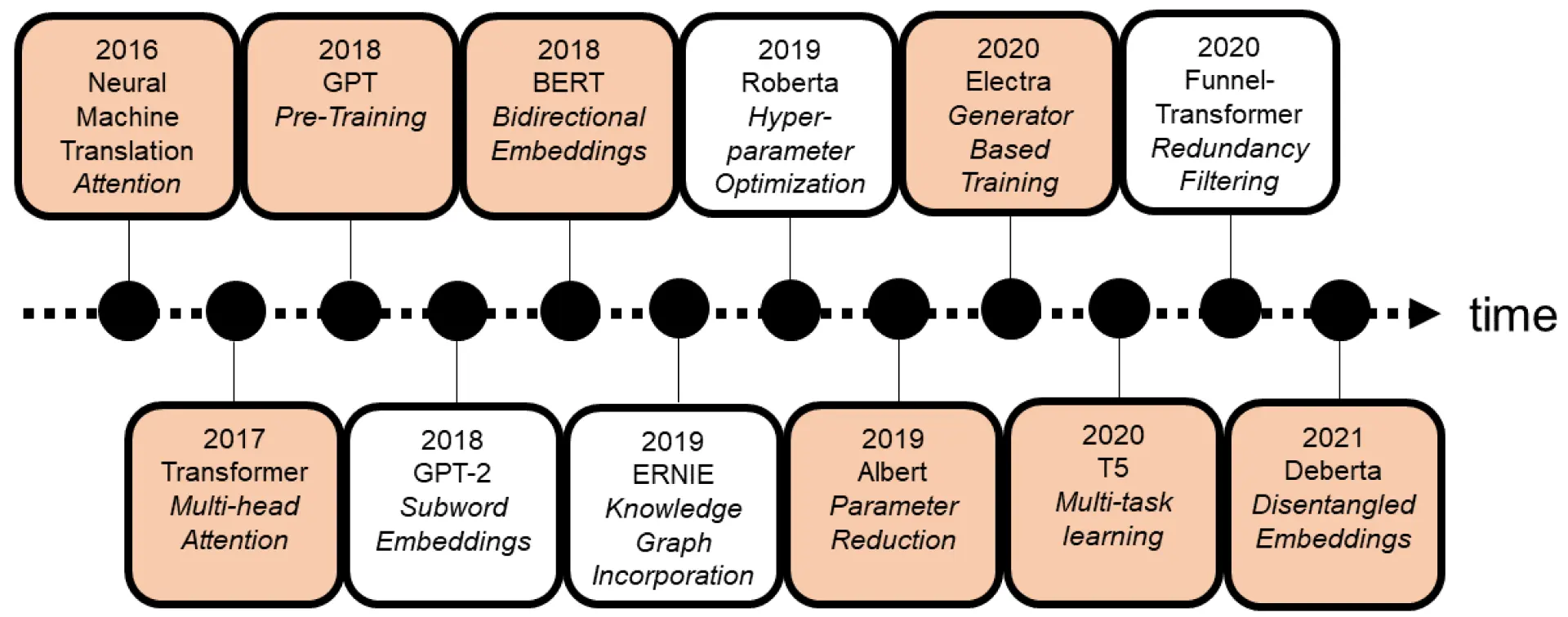
Figure: Timeline for the Evolution of Language Models
In this blog, we'll explore different language models that have played a key role in the development of large language models.
Table of Contents
- Introduction
- Probabilistic Models
- Neural Network-based Language Models
- Recurrent Neural Networks
- Long Short-Term Memory (LSTM) Networks
- Gated Recurrent Unit (GRU) Networks
- Encoder-Decoder Networks
- Transformer Architecture
- Large Language Models (LLMs)
- General Architecture Properties Tokenization
- Conclusion
- Frequently Asked Questions (FAQ)
1. Probabilistic Models
Probabilistic models help computers understand the likelihood of words and phrases in language. Let’s dive into two key models: n-gram and Hidden Markov Models (HMMs), both used in Natural Language Processing (NLP).
1.1 N-Gram Model
The n-gram model predicts the next word in a sequence based on the previous n-1 words.
In a bigram model (n=2), the next word is predicted by looking at just the previous word.
Key Feature: N-gram models are simple and can handle large datasets because they only consider one word at a time.
Limitation: The model only looks at the previous word, ignoring the rest of the sentence, which can lead to less accurate predictions.
1.2 Hidden Markov Model (HMM)
HMM is a statistical model used for understanding sequences where hidden states (not directly observed) produce visible events.
How it works:
- Hidden States: These are the unseen parts of the process (like the grammatical structure).
- Observable Events: These are the visible outcomes (like the words in a sentence).
1.3 Applications
- Speech Recognition
- Part-of-Speech Tagging
- Machine Translation
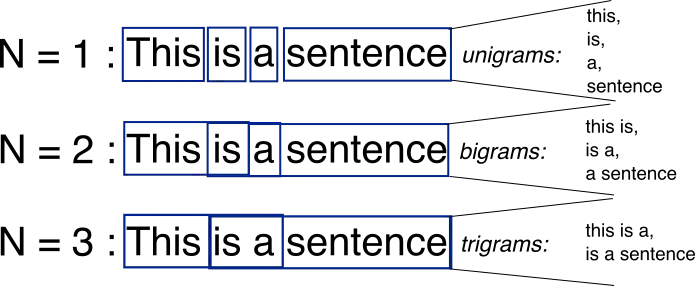
Figure: N-Gram Model
2. Neural Network-based Language Models
Neural network-based language models have revolutionized natural language processing (NLP) by enabling computers to predict and generate text with remarkable accuracy. These models are trained on large datasets to learn patterns in language and make probabilistic predictions for the next word in a sentence.
2.1 How Neural Networks Work in Language Models
Neural networks process language by recognizing patterns and correlations in the training data.
- Prediction Process: The model predicts the next word based on the words that came before it.
- Learning Mechanism: It identifies relationships in the input data, such as grammar, context, and meaning, to make informed predictions.
2.2 Key Features and Limitations
- Key Feature: Neural networks can capture complex relationships in language and generate coherent text.
- Limitation: They require large datasets and significant computational power for effective training.
2.3 Applications of Neural Network-Based Models
- Text generation (e.g., chatbots, virtual assistants)
- Machine translation
- Sentiment analysis
These models paved the way for more advanced architectures, such as transformers, that power modern LLMs.
Figure: Neural Networks
3. Recurrent Neural Networks
Recurrent Neural Networks (RNNs) are a form of artificial neural network that processes incoming data one at a time while retaining a state that summarises the history of previous inputs.
Recurrent Neural Networks (RNNs) are a special type of neural network designed to process data in sequences. Unlike regular neural networks, RNNs remember previous inputs, allowing them to make decisions based on both current and past data.
3.1 Key Features of RNNs
- Handles Variable-Length Data:RNNs can work with inputs and outputs of different lengths, making them useful for tasks like:
- Language synthesis
- Machine translation
- Speech recognition
- Captures Temporal Dependencies:RNNs have feedback loops that feed the output back into the model as input. This helps the network "remember" what it has seen before, allowing it to learn from previous steps in the sequence.
3.2 Challenges with RNNs:
- Vanishing Gradient Problem:When training RNNs, the gradients (used to adjust the model) can become too small. This makes it hard for the network to learn long-term dependencies in sequential data.
- Exploding Gradient Problem:The gradients sometimesIn some cases, the gradients become too large, causing unstable updates to the model’s weights. This can lead to poor performance or failure to train.
- Computational Limitations: Since RNNs process data one step at a time, they can be slow and hard to parallelize, which makes it difficult to scale them up for large datasets.
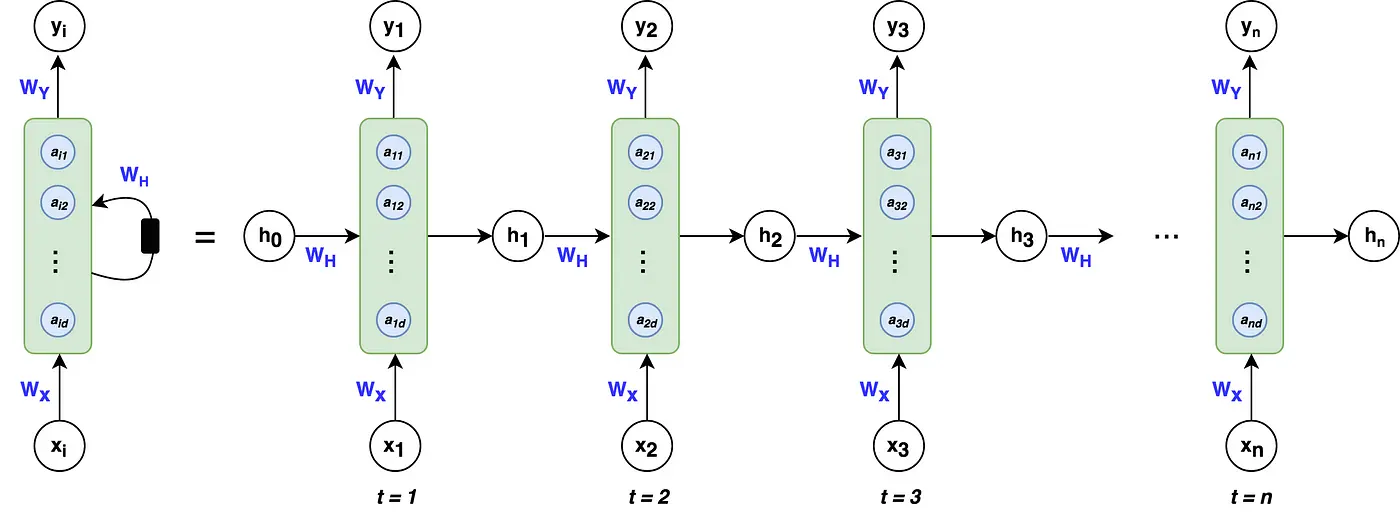
Figure: Recurrent Neural Networks
4. Long Short-Term Memory (LSTM) Networks
Long Short-Term Memory (LSTM) networks are a type of recurrent neural network (RNN) designed to overcome the limitations of traditional RNNs by effectively capturing long-term dependencies in sequential data.
4.1 How LSTMs Work
LSTMs introduce a memory cell and gates to control the flow of information.
- Memory Cell: Stores information across time steps, allowing the model to retain context over long sequences.
- Gates:
- Forget Gate: Decides which information to discard from the memory.
- Input Gate: Determines what new information to store.
- Output Gate: Controls what information to use for predictions.
4.2 Key Features and Limitations
- Key Feature: LSTMs are excellent at capturing long-term dependencies and context in sequential data.
- Limitation: They are computationally intensive and can struggle with very long sequences compared to newer models like transformers.
4.3 Applications of LSTM Networks
- Speech recognition
- Time-series prediction
- Text generation
LSTM networks played a critical role in advancing sequential modeling and paved the way for more efficient architectures like transformers and attention mechanisms.
5. Gated Recurrent Unit (GRU) Networks
Gated Recurrent Unit (GRU) networks are a simplified version of LSTMs, designed to capture sequential data's context while reducing complexity. GRUs retain the ability to manage long-term dependencies but use fewer parameters, making them more computationally efficient.
5.1 How GRUs Work
GRUs use gating mechanisms to control the flow of information without the memory cell in LSTMs.
- Update Gate: Decides how much of the past information to keep.
- Reset Gate: Determines how much of the previous state to forget when computing the current state.
These gates work together to ensure the model captures both short-term and long-term dependencies.
5.2 Key Features and Limitations
- Key Feature: GRUs are simpler and faster to train compared to LSTMs while offering similar performance in many tasks.
- Limitation: GRUs might not perform as well as LSTMs on highly complex sequential tasks requiring extensive memory.
5.3 Applications of GRU Networks
- Language modeling
- Sentiment analysis
- Time-series forecasting
GRUs strike a balance between efficiency and performance, making them a popular choice for many sequential data problems.
6. Encoder-Decoder Networks
Encoder-Decoder networks are a powerful architecture for handling sequence-to-sequence tasks, where the input and output have varying lengths, such as in translation or summarization. These networks consist of two main components: the encoder and the decoder.
6.1 How Encoder-Decoder Networks Work
- Encoder: Processes the input sequence and converts it into a fixed-length context vector (or representation).
- Decoder: Takes the context vector and generates the output sequence step-by-step.
The encoder and decoder are typically implemented using RNNs, LSTMs, GRUs, or Transformers.
6.2 Key Features and Limitations
- Key Feature: Encoder-decoder networks handle variable-length input and output sequences effectively, making them versatile.
- Limitation: Vanilla encoder-decoder networks struggle with long sequences due to the fixed-length context vector, which may lose important information. Attention mechanisms were later introduced to address this limitation.
6.3 Applications of Encoder-Decoder Networks
- Machine translation (e.g., English to French)
- Text summarization
- Speech-to-text conversion
This architecture laid the foundation for transformer-based models like BERT and GPT, which dominate modern NLP tasks.
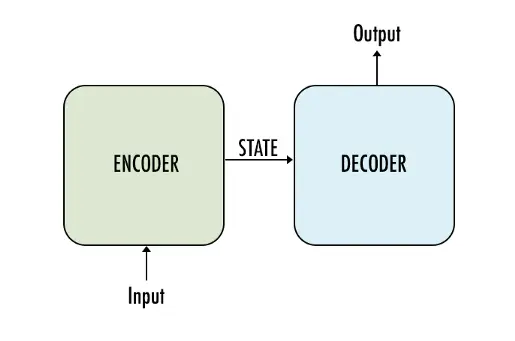
Figure: Encoder-Decoder Architecture
7. Attention Mechanism
The Attention Mechanism is a technique that allows models to focus on different parts of an input sequence when making predictions, instead of processing the entire sequence in a fixed manner.
This improves performance on tasks involving long sequences and complex relationships between words.
7.1 How Attention Mechanism Works
The attention mechanism works by assigning different weights to different parts of the input sequence, enabling the model to "pay attention" to more relevant words or phrases while making predictions.
- Query, Key, and Value: In the context of transformers, the model uses queries, keys, and values to compute attention scores, which help determine which parts of the sequence are most important.
- Self-Attention: A specific form of attention where the model attends to different words within the same sequence to build contextual relationships.
7.2 Key Features and Limitations
- Key Feature: Attention allows models to focus on important parts of the input sequence, improving context understanding.
- Limitation: It can be computationally expensive, especially with long input sequences.
7.3 Applications of Attention Mechanism
- Machine translation
- Text generation
- Question answering
The attention mechanism has become the cornerstone of modern models like transformers, enhancing their ability to process and generate text.
8. Transformer Architecture
The Transformer architecture, introduced in the "Attention is All You Need" paper, has revolutionized NLP by leveraging attention mechanisms to process sequences in parallel, rather than sequentially as in previous models like RNNs or LSTMs.
8.1 How Transformer Architecture Works
- Encoder-Decoder Structure: Like traditional encoder-decoder models, but with attention mechanisms replacing RNNs.
- Self-Attention: Each word in a sequence is compared to every other word to build contextual relationships.
- Multi-Head Attention: Allows the model to attend to different parts of the input sequence simultaneously, capturing various aspects of the data.
8.2 Key Features and Limitations
- Key Feature: Transformers can process entire sequences in parallel, significantly speeding up training and enabling better scalability.
- Limitation: Transformers require a large amount of computational power, especially for longer sequences.
8.3 Applications of Transformer Architecture
- Natural Language Understanding (NLU) tasks
- Machine translation (e.g., Google Translate)
- Text generation (e.g., GPT models)
The transformer architecture has set the standard for modern NLP models, powering state-of-the-art systems like BERT, GPT, and T5.
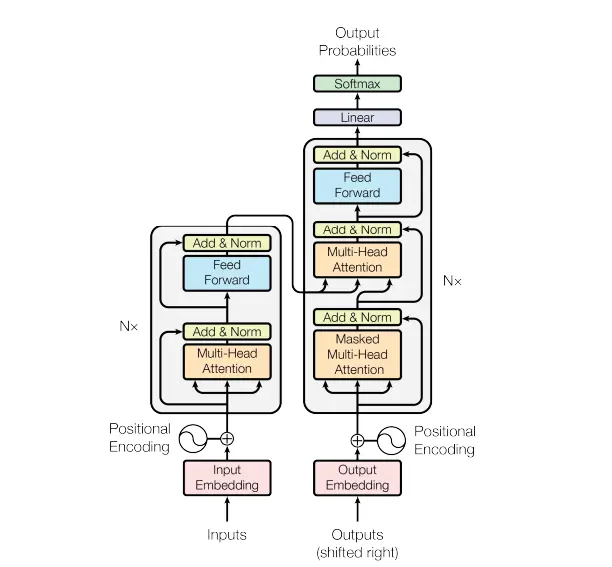
Figure: Transformer Architecture
9. Large Language Models (LLMs)
Large Language Models (LLMs) have become a cornerstone of modern natural language processing (NLP), with the transformer architecture driving their success.
Since 2018, transformers have been the dominant architecture for LLMs, offering unparalleled efficiency in processing long sequences of data.
Before transformers, recurrent neural networks (RNNs), particularly Long Short-Term Memory (LSTM) networks, were the go-to models for sequential tasks.
9.1 How Large Language Models Work
LLMs use the transformer architecture, which is well-suited for tasks such as language translation, text generation, and question answering.
The transformer model, introduced in the groundbreaking paper "Attention is All You Need" by Vaswani et al. in 2017, revolutionized NLP by introducing attention mechanisms that allow the model to focus on different parts of the input sequence simultaneously.
This ability to handle long-range dependencies without the need for sequential processing has made transformers the standard for sequential data processing.
9.2 General Architecture Properties
Tokenization
Tokenization is the process of converting words or subwords into numbers so that a model can process them. LLMs use tokenizers, which are bijective functions that map text to lists of integers.
Tokenizers are trained on the entire dataset and are typically frozen before training the LLM. They serve to compress the input text, mapping common words or phrases to a single token.
For example, one token might represent approximately four characters or 0.75 words in typical English text.
Output
The output of an LLM is a probability distribution over its vocabulary, computed using a softmax function.
When the model receives input text, it produces a vector representing the probabilities of each word in its vocabulary.
The softmax function normalizes these values so that they sum to one, representing the model's prediction for the most likely next word or phrase given the input.
9.3 Examples of Large Language Models
Several recent developments in LLMs include:
- GPT-4: The fourth iteration of the Generative Pre-trained Transformer (GPT) series, known for its ability to generate human-like text, answer questions, write poetry, and code.
- BERT: Bidirectional Encoder Representations from Transformers (BERT), developed by Google, is a pre-trained model that captures context from both directions, making it useful for tasks such as question answering and sentence classification.
- T5: Developed by Google, T5 treats all NLP tasks as a text-to-text problem, achieving remarkable results in tasks like translation, summarization, and question answering.
- RoBERTa: An optimized version of BERT, developed by Facebook, RoBERTa has surpassed BERT in many benchmarks by utilizing more training data and removing some of BERT’s constraints.
- Megatron: Developed by NVIDIA, Megatron is an LLM designed to scale efficiently, allowing researchers to train models with billions of parameters while maintaining performance.
These models showcase the versatility and power of LLMs in handling complex NLP tasks, from generation to comprehension.

ChatGPT: LLM introduced by OpenAI
Conclusion
The journey from early statistical models to Large Language Models (LLMs) marks a remarkable evolution in natural language processing (NLP).
Initial models like n-grams and Hidden Markov Models laid the foundation, but their limitations prompted the development of neural networks, including Recurrent Neural Networks (RNNs) and advanced versions like Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs).
The introduction of encoder-decoder architectures and the Transformer model revolutionized language processing, enabling improved handling of sequential data and attention mechanisms.
Today, models like GPT-4 and BERT exemplify the capabilities of LLMs, delivering human-like text generation and diverse applications across various fields.
As we look to the future, advancements in model architecture and ethical considerations will likely enhance the efficiency and adaptability of language technologies, paving the way for even more innovative solutions in understanding and generating human language.
Frequently Asked Questions (FAQ)
1. What is the large language models theory?
The large language model is an advanced form of natural language processing that goes beyond fundamental text analysis. By leveraging sophisticated AI algorithms and technologies, it can generate human-like text and accomplish various text-related tasks with high believability.
2. What are examples of large language models?
Different organizations have developed several prominent large language models. For instance, OpenAI has developed models like GPT-3 and GPT-4, Meta has introduced LLaMA, and Google has created PaLM2. These models excel in understanding and generating human language.
3. What are the applications of neural networks?
Neural networks find applications in various fields, such as image recognition, speech recognition, machine translation, and medical diagnosis. Their ability to learn from sample data sets is a notable advantage. One of the most common uses of neural networks is for approximating random functions.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
