

Evaluating and Finetuning Text To Video Model - Case Study


Introduction
Artificial intelligence has advanced significantly with text-to-video models, which fuse natural language interpretation subtleties with computer vision's visual narrative capabilities.
These models do more than just translate text to images; they also produce a series of images, or a video, that narrates a story based on the input text.
Text-to-video models are extremely important to AI and machine learning. They show how computer vision and natural language processing, two historically distinct fields of artificial intelligence, are coming together.
Richer experiences than could be obtained from static images or text alone are made possible by this link, which enables the creation of information that is more interesting and educational.
Text-to-video models' underlying technology is proof of the advances made in artificial intelligence. In order to provide a smooth video story, these models must not only produce visually pleasing frames but also make sure that these frames are temporally cohesive.
This calls for a solid understanding of the story structure, which is significantly more difficult than creating a single image.
Text-to-video models have a wide range of useful applications. With just a text prompt, they may produce short films, ads, instructional materials, and much more.
This has the power to completely transform content creation in a variety of industries by improving its efficiency and accessibility.
However creating these models is not without its difficulties. They need complex algorithms that can understand the subtleties of language and convert them into visually coherent parts that make sense when combined with one another over time.
This calls for not just comprehending the text's information but also encapsulating its tone, atmosphere, and style.
Though they are still in the early stages of development, text-to-video models are developing quickly. The precision, effectiveness, and caliber of the movies produced by these models are always being refined by researchers.
The future appears promising because these models can produce videos that are exact replicas of human-made ones.
Background
Evolution from Text-to-Image to Text-to-Video Models
The evolution from text-to-image to text-to-video models marks a significant advancement in the field of generative AI.
Initially, text-to-image models like VQGAN-CLIP and DALL-E made headlines with their ability to generate compelling images from textual descriptions.
These models laid the groundwork for the more challenging task of video generation, which necessitates not only the creation of visually appealing frames but also the assembling of these frames into a coherent sequence that adheres to the input text's narrative flow.
Technological Advancements and Breakthroughs
Technological breakthroughs in text-to-video models have been driven by the need to address the added complexity of video generation.
Unlike static images, videos incorporate motion and continuity over time, presenting unique challenges in ensuring temporal coherence and narrative consistency.

Recent models like Google’s Imagen Video and Meta’s Make-A-Video have introduced innovative approaches such as cascaded diffusion models and hierarchical training strategies, pushing the envelope in the quality and fidelity of generated videos.
Comparison with Other Generative Models
When compared to other generative models, text-to-video models stand out for their dynamic content generation capabilities.
While models like GANs, VAEs, and diffusion models have their own strengths in generating high-quality images or text, text-to-video models are unique in their ability to produce content that evolves over time, capturing the essence of storytelling and event depiction.
This sets them apart in the generative AI landscape and opens up new possibilities for applications that require a narrative element.
Core Concepts
Text-to-video models are sophisticated AI systems designed to generate video content directly from textual descriptions.
These models function by interpreting the semantics and narrative of the input text, transforming it into a sequence of coherent images, or frames, that collectively form a video.
The primary challenge for these models lies in producing content that is not only visually appealing but also temporally consistent.
Temporal consistency means that the generated video should flow logically from one frame to the next, accurately reflecting the actions, movements, and narrative progression described by the text.
Ensuring this consistency is crucial for the video to make sense and convey the intended message or story effectively.
Architecture and Working Principles
The architecture of text-to-video models is inherently complex, typically involving multiple neural network layers that collaborate to produce the final video output.
Initially, simpler models utilized recurrent neural networks (RNNs) to handle sequential data, leveraging their ability to process and generate time-series information.
However, as the field has evolved, more sophisticated architectures such as Generative Adversarial Networks (GANs) and transformers have become prominent.
In a typical text-to-video model, the process begins with encoding the input text into a latent space—a high-dimensional vector representation that captures the text's semantic content.
This encoded information is then used by the generative component of the model to create video frames.
GANs, for example, consist of two networks: a generator, which creates video frames, and a discriminator, which evaluates their realism.
Through an iterative process, the generator improves its output based on the feedback from the discriminator, resulting in increasingly realistic video frames.
Transformers, on the other hand, excel in handling sequential data, making them well-suited for capturing the temporal dependencies necessary for video generation.
These models encode the entire input sequence at once, allowing for efficient parallel processing and better long-range dependency modeling.
This capability is particularly advantageous for ensuring that each frame logically follows the previous one, maintaining spatial coherence and narrative flow.
Diffusion Models and Transformer Architecture
Recent advancements in AI have seen the adaptation of diffusion models and transformers for text-to-video generation. Diffusion models, originally developed for high-quality image generation, have shown great promise in video applications.
These models start with a sequence of noise and iteratively refine it to produce a coherent video that matches the textual description.
This iterative refinement process helps in maintaining object consistency and motion coherence throughout the video, which is critical for producing high-quality results.
Transformers have been a breakthrough in natural language processing due to their ability to handle sequences effectively. In the context of text-to-video generation, transformers are adapted to generate a series of video frames.
Some models employ a transformer-based framework to directly generate frames sequentially, ensuring temporal consistency. Others use hybrid methods that combine the strengths of image-generation techniques with time-sensitive transformer modules.
This hybrid approach allows for the generation of frames that are not only visually accurate but also temporally coherent, aligning well with the narrative structure provided by the text.
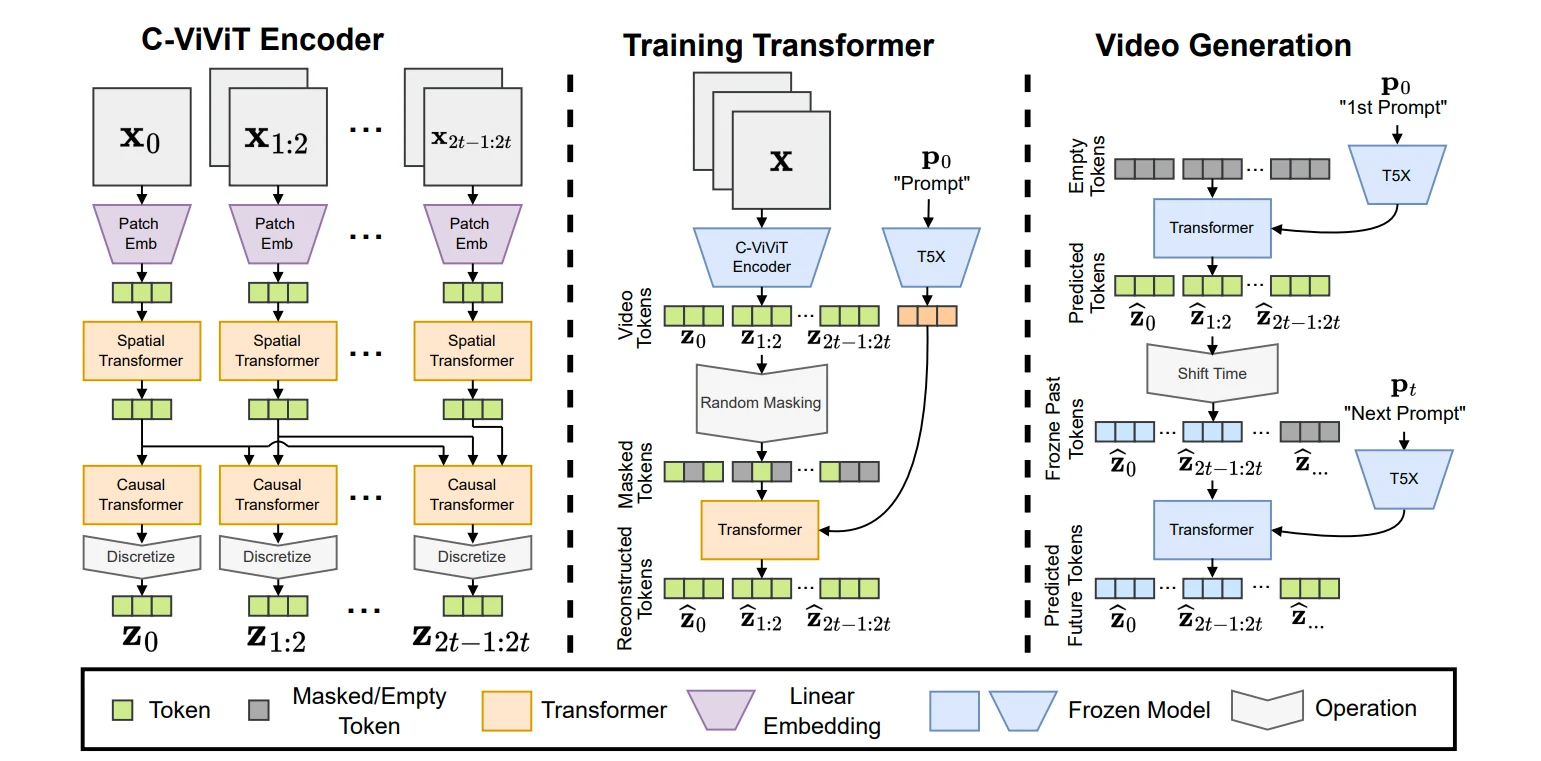
The image above outlines the architecture of PHENAKI text-to-video model, which is a type of machine-learning model designed to generate videos from textual descriptions. Let’s break down the components as described in the image:
C-ViViT Encoder
The C-ViViT Encoder is a crucial part of the model that processes the initial input. It consists of several stages:
Patch Embedding: This stage involves breaking down the input into smaller pieces or ‘patches’ and then embedding them into a higher-dimensional space for the model to process.
Spatial Transformer: Here, the model applies transformations to capture the spatial relationships within the data.
Temporal Transformer: This component captures the temporal dynamics, which is essential for understanding the sequence of events over time.
The encoder transforms the raw input (denoted as X0) into a series of encoded representations (X1…2).
Training Transformer
The Training Transformer is where the actual learning happens. It takes the encoded representations from the C-ViViT Encoder and further processes them through:
Attention mechanisms, allow the model to focus on different parts of the input sequence when making predictions.
Linear transformations are mathematical operations applied to the data.
Video Generation
The final section, Video Generation, is where the model outputs the generated video. It starts with an initial prompt (P0 1st Prompt) and goes through a series of transformers and tokenizers to produce the final video output (P1…t).
Evaluation Metrics for Text-to-Video Models
Evaluating the performance of text-to-video (T2V) models involves multiple aspects to ensure that the generated videos are of high quality and align well with the provided text prompts.
Unlike traditional methods that rely heavily on metrics like FID (Frechet Inception Distance), contemporary approaches necessitate a more comprehensive evaluation framework.
This section delves into the detailed metrics used for evaluating T2V models, focusing on overall video quality, text-video alignment, motion quality, and temporal consistency.
1) Overall Video Quality Assessment
Assessing the visual quality of generated videos is crucial for ensuring user appeal. Traditional distribution-based methods like FVD (Frechet Video Distance) require ground truth videos, making them unsuitable for general T2V generation cases. Instead, several other metrics are employed:
1.1 Video Quality Assessment (VQAA and VQAT): These metrics, derived from the Dover method, evaluate the aesthetics and technicality of the generated videos. The technical rating measures common distortions such as noise and artifacts.
The Dover method, trained on a large-scale dataset with user-ranked labels, provides scores for both aesthetic (VQAA) and technical (VQAT) quality.
1.2 Inception Score (IS): Widely used in T2V generation papers, the Inception Score evaluates the diversity and quality of the generated content using a pre-trained Inception Network on the ImageNet dataset. A higher Inception Score indicates more diverse and higher-quality content.
2) Text-Video Alignment
Evaluating the alignment between the input text and the generated video is critical for ensuring that the video content accurately reflects the textual description. This evaluation includes several metrics:
2.1 Text-Video Consistency (CLIP-Score): This metric uses the CLIP model to quantify the similarity between input text prompts and generated videos. By computing the cosine similarity between frame-wise image embeddings and text embeddings, the overall CLIP-Score is derived.
2.2 Image-Video Consistency (SD-Score):
This newly proposed metric compares the generated video frames with images generated using the Stable Diffusion (SD) model, addressing concept forgetting issues when fine-tuning T2I models to video models.
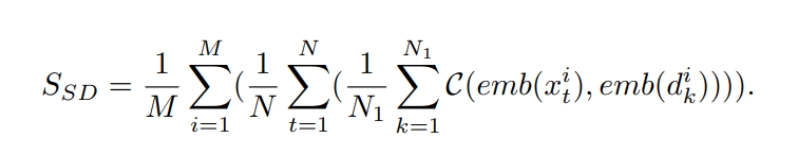
where x i t is the t-th frame of the i-th video, C(·, ·) is the cosine similarity function, emb(·) means CLIP embedding, M is the total number of testing videos, and N is the total number of frames in each video, where N1 = 5.
2. 3 Text-Text Consistency (BLIP-BLEU): This metric evaluates the alignment between generated text descriptions of the video and the input prompt using BLIP2 for caption generation and BLEU for scoring.
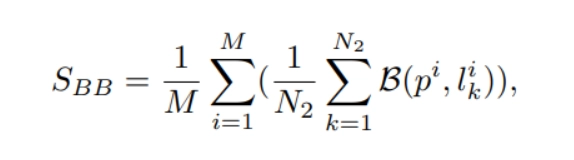
where p^i is the i-th prompt, B(·, ·) is the BLEU similarity scoring function, {li k } N2 k=1 are BLIP2 generated captions for i-th video, and N2 is set to 5 experimentally
3) Object and Attributes Consistency
Tools like SAMTrack and DeepFace are used to perform the following evaluations.
3. 1 Detection-Score assesses the presence of objects in the video as specified by the text prompts.
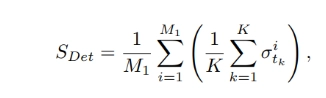
where M1 is the number of prompts with objects, K is the number of frames where detection is performed, and σ i tk is the detection result for frame tk in video i (1 if an object is detected, 0 otherwise). In our approach, we perform detection every I = 5 frames. Therefore, K = N/I .
3.2 Count-Score assesses the count of objects in the video as specified by the text prompts.
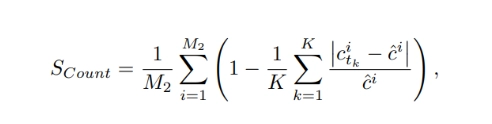
where M2 is the number of prompts with object counts, c i tk is the detected object count at frame tk in video i, and cˆ i is the ground truth object count for the video i.
3.3 Color-Score assesses the color accuracy of objects in the video as specified by the text prompts.
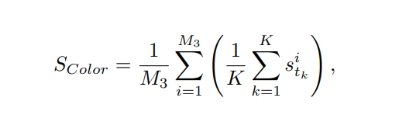
where M3 is the number of prompts with object colors and s i tk is the color accuracy result for frame tk in video i (1 if the detected color matches the ground truth color, 0 otherwise).
3.4 Human Analysis (Celebrity ID Score)
This metric evaluates the correctness of human faces in generated videos using the DeepFace analysis toolbox, comparing generated celebrity faces to real images.
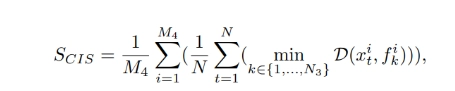
where M4 is the number of prompts that contain celebrities, D(·, ·) is the Deepface’s distance function, {f i k } N3 k=1 are collected celebrities images for i-th prompt, and N3 = 3
3. 5 Text Recognition (OCR-Score)
This metric assesses the ability of T2V models to generate text within the video using PaddleOCR, measuring word error rate, normalized edit distance, and character error rate.
4) Motion Quality
Motion quality is a distinguishing factor in video generation compared to static image generation. Evaluating motion quality involves:
4.1 Action Recognition (Action-Score): Using pre-trained models like VideoMAE V2, this metric infers human actions in generated videos, focusing on classification accuracy for common actions.
4.2 Average Flow (Flow-Score): This metric uses RAFT to extract dense optical flows between frames, calculating the average flow to assess general motion quality.
4.3 Amplitude Classification Score (Motion AC-Score): This metric evaluates whether the motion amplitude in the generated video matches the amplitude specified by the text prompt, using an average flow threshold.
5) Temporal Consistency
Temporal consistency ensures that the generated video maintains coherence across frames. Metrics for this evaluation include:
5.1 Warping Error: This metric calculates the pixel-wise differences between warped images and predicted images, using optical flow estimation to assess consistency across frames.
5.2 Semantic Consistency (CLIP-Temp): Similar to warping error but focused on semantic information, this metric computes the cosine similarity between embeddings of consecutive frames to evaluate semantic continuity.
5.3 Face Consistency: This metric assesses the consistency of human identity across video frames by calculating the cosine similarity of embeddings from the first frame to subsequent frames.
6)User Opinion Alignments
In addition to objective metrics, user opinions are crucial for evaluating the overall performance of T2V models.
User studies focus on various aspects such as video quality, text-video alignment, motion quality, and temporal consistency.
By generating videos using state-of-the-art methods and collecting feedback from users, these studies help align evaluation metrics with human preferences, ensuring that the generated videos meet user expectations and preferences.
Through a combination of these metrics, T2V models can be rigorously evaluated to ensure that they produce high-quality, relevant, and temporally consistent video content that aligns well with the input text prompts.
Challenges in Evaluating and Fine-tuning Text-to-Video Models
The development and refinement of text-to-video (T2V) models present several significant challenges.
These challenges, spanning computational difficulties, data scarcity, and ethical considerations, must be addressed to advance the field and ensure the responsible deployment of these models.
Computational Difficulties: Ensuring Spatial and Temporal Consistency
One of the primary computational challenges in T2V models is maintaining both spatial and temporal consistency in the generated videos.
Spatial consistency ensures that each frame is visually coherent, while temporal consistency ensures that the sequence of frames forms a fluid, logical video.
Spatial Consistency: Achieving spatial consistency requires high computational power and advanced algorithms to generate detailed and accurate frames.
Each frame must be coherent in itself and match the scene described by the text prompt.
This involves intricate neural network architectures and significant computational resources for training and inference.
Advanced techniques such as convolutional neural networks (CNNs) are often employed to enhance spatial details and ensure that the visual quality of each frame meets a high standard.
Temporal Consistency: Ensuring temporal consistency is even more challenging as it involves maintaining logical and smooth transitions between frames.
Temporal inconsistencies can result in jarring or unrealistic videos that do not accurately reflect the intended narrative.
Techniques like optical flow estimation and advanced generative models (e.g., transformers and GANs) are employed to tackle these issues, but they demand substantial computational resources and sophisticated training regimes.
Optical flow techniques help in tracking the motion of objects between frames, ensuring smoother transitions and coherent motion, which are crucial for the natural appearance of generated videos.
Data Scarcity: Availability of Datasets for Training and Evaluation
Data scarcity is another significant hurdle in the development of T2V models. High-quality, large-scale datasets are essential for training models that can generate accurate and realistic videos from text prompts. However, several factors contribute to the scarcity of such datasets:
Diverse and Annotated Data: T2V models require datasets that not only include a wide range of scenes and actions but also have detailed annotations that link text descriptions to corresponding video clips.
Creating such datasets is labor-intensive and costly. Detailed annotations are essential for training the models to understand and generate the nuanced aspects of the text prompts accurately.
Quality and Variety: The datasets must encompass a broad spectrum of scenarios to ensure the models generalize well across different contexts.
This includes variations in lighting, camera angles, object interactions, and environmental conditions, which are challenging to compile in a single dataset. Without such diversity, models may overfit specific types of data and fail to perform well in real-world applications.
Evaluation Benchmarks: Besides training data, robust evaluation benchmarks are needed to assess the performance of T2V models. These benchmarks must be comprehensive and cover various aspects such as visual quality, alignment with text, and temporal coherence.
The lack of standardized evaluation datasets hampers the consistent assessment of different models and their progress. Comprehensive benchmarks enable fair comparisons and highlight areas where models excel or need improvement.
Ethical Considerations: Misinformation, Bias, and Content Moderation
Ethical considerations are paramount when developing and deploying T2V models. These concerns include the potential for generating misinformation, inherent biases in the models, and the need for content moderation.
Misinformation: T2V models can be misused to create fake videos that spread misinformation. This capability raises concerns about the authenticity and trustworthiness of video content, especially in the context of news and social media.
Ensuring that these models are used responsibly and implementing safeguards against misuse is crucial. Potential solutions include developing verification tools that can distinguish between real and AI-generated content.
Bias: Like many AI systems, T2V models can inherit and amplify biases present in their training data.
This can result in the generation of biased or discriminatory content. Addressing bias involves careful dataset curation, algorithmic fairness techniques, and ongoing monitoring to detect and mitigate biased outputs.
Efforts to de-bias training datasets and apply fairness-aware algorithms are essential for creating more equitable AI systems.
Content Moderation: With the ability to generate vast amounts of video content, T2V models pose challenges for content moderation. Ensuring that generated videos do not contain harmful, inappropriate, or illegal content is essential.
Developing robust moderation frameworks and incorporating ethical guidelines into the model development process are necessary steps to address these challenges. Implementing automated moderation tools and establishing clear guidelines for acceptable content can help mitigate these risks.
Fine-tuning Strategies for Text-to-Video Models
Fine-tuning text-to-video (T2V) models is crucial to adapt them to specific tasks or improve their performance on new types of data.
Effective fine-tuning strategies can significantly enhance the quality and relevance of the generated videos, ensuring they meet the desired standards and user expectations.
Here, we explore two prominent fine-tuning strategies: one-shot video tuning and customizing motions.
One-shot Video Tuning: Using a Single Text-Video Pair for Model Refinement
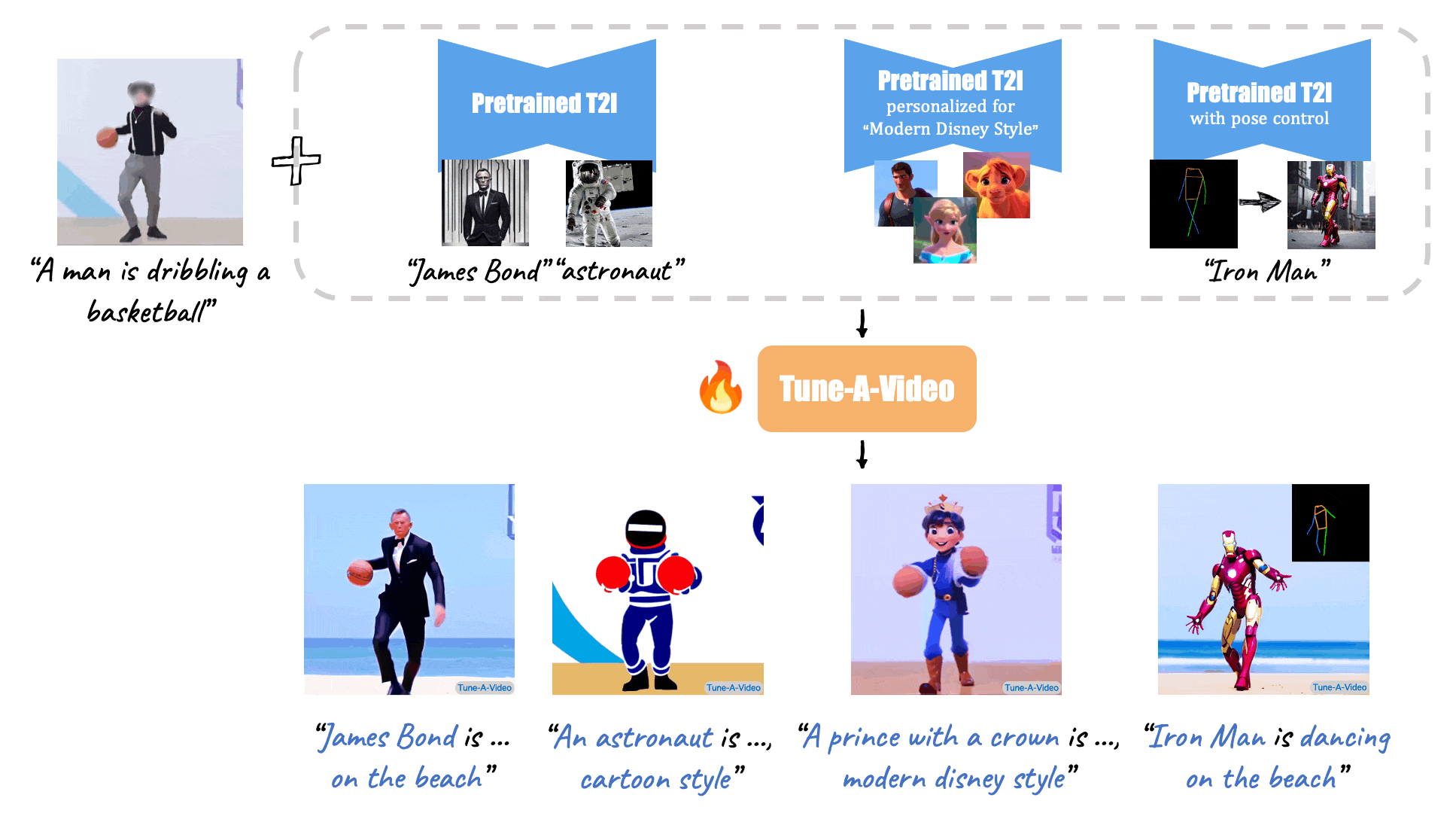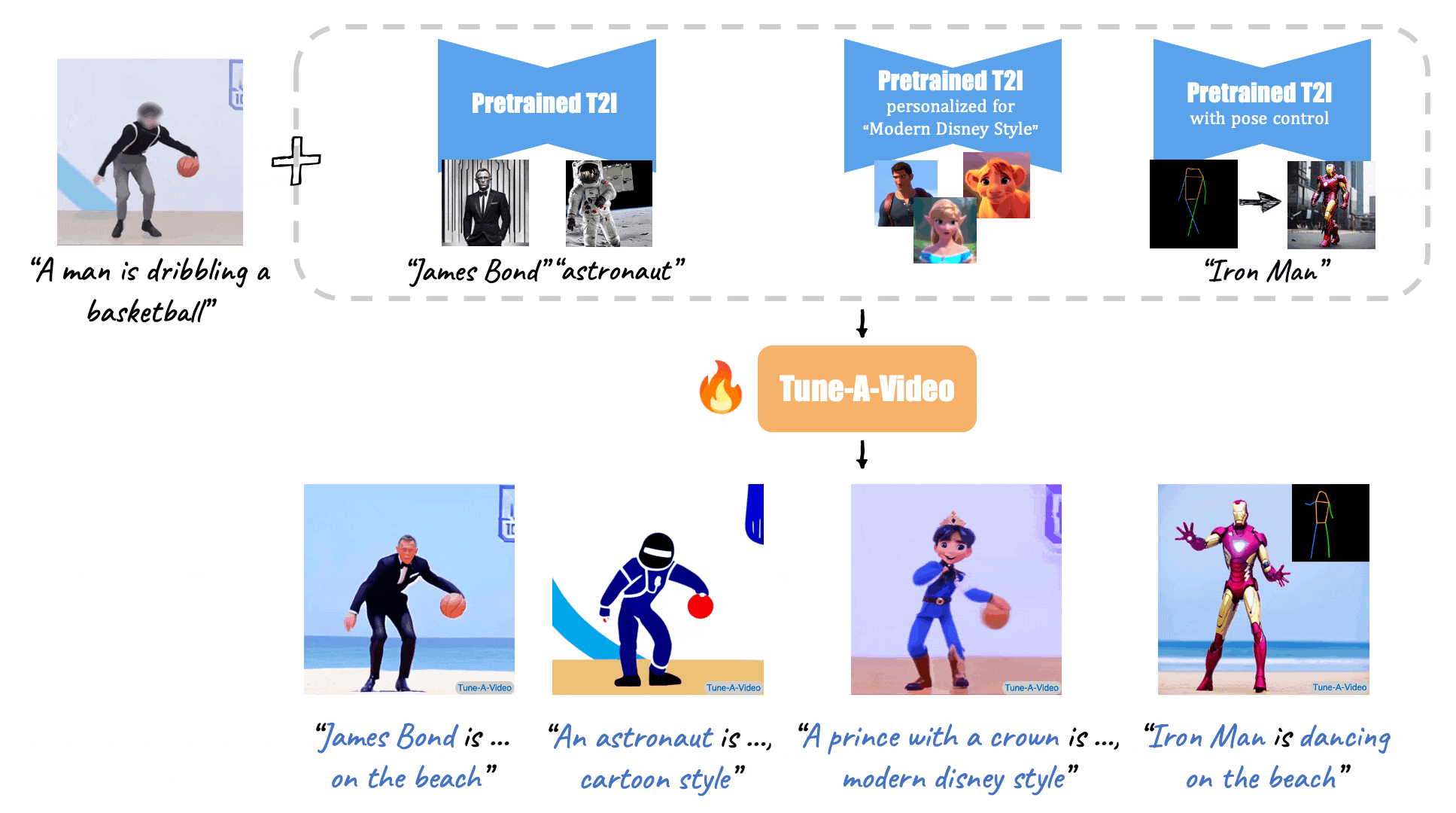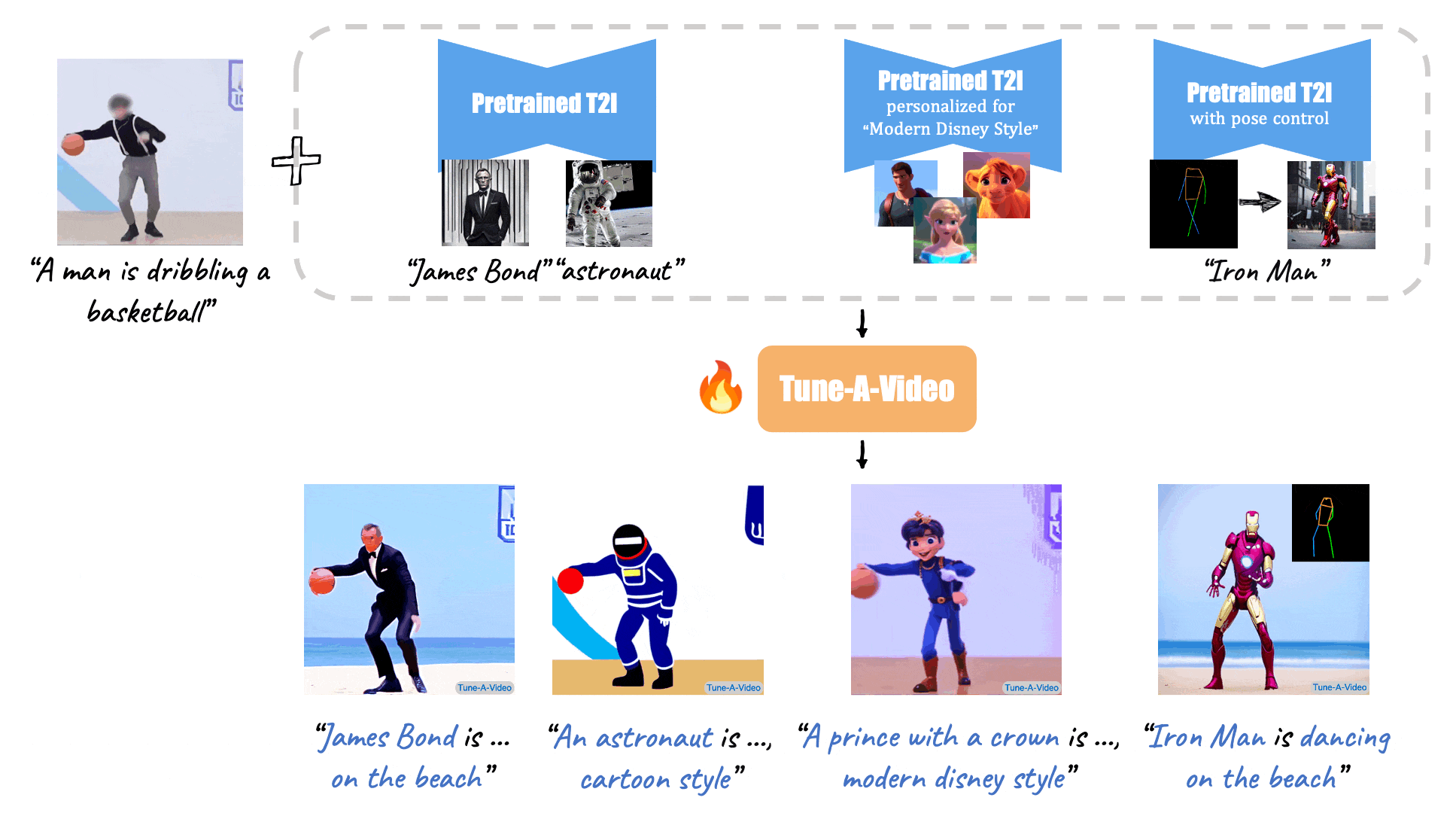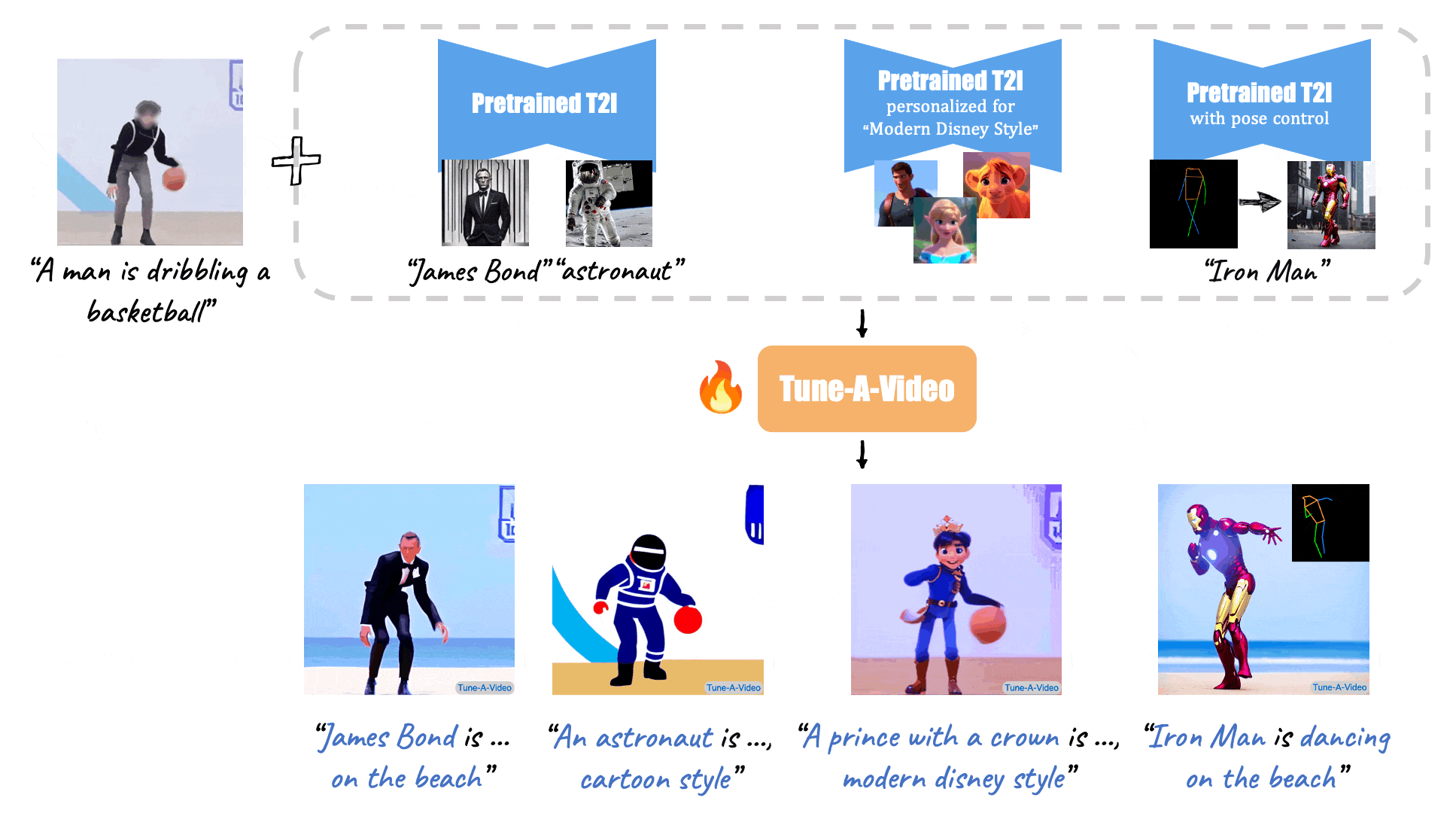
One-shot video tuning involves refining a T2V model using just a single text-video pair. This technique is particularly valuable when there is limited data available for a specific task or when quick adaptation to new content is required. The process generally involves the following steps:
Identifying Key Features: The initial step is to identify the salient features of the provided text-video pair. This includes the primary objects, actions, and scene elements depicted in the video and described in the text.
This helps the model to understand what aspects are most important in the specific context.
Model Adjustment: The model undergoes minor adjustments to better capture the nuances of the specific text-video pair.
This can be done by tweaking the weights of the neural network layers to enhance the model’s sensitivity to the unique features of the input pair.
Adjustments may involve fine-tuning the attention mechanisms to focus more on critical elements in the video.
Loss Function Optimization: The fine-tuning process often involves optimizing the loss function to minimize discrepancies between the generated video and the ground truth video.
This ensures that the model accurately reproduces the specific characteristics of the single text-video pair. The optimization process might use techniques like gradient descent to iteratively improve the model’s predictions.
One-shot video tuning is advantageous because it allows for rapid adaptation with minimal data.
However, it also poses challenges such as the risk of overfitting, where the model becomes too specialized to the single example and loses its generalization ability for other inputs.
To mitigate overfitting, techniques such as dropout or data augmentation might be employed during the fine-tuning process.
Augmenting Model Beyond Original Training Data
Customizing motions involves augmenting the T2V model to generate videos with specific motion patterns that may not be extensively covered in the original training data.
This strategy enhances the model's capability to produce diverse and contextually appropriate motions, which is crucial for creating dynamic and engaging videos.
Motion Data Augmentation: This involves expanding the training dataset with additional motion sequences.
Synthetic data generation techniques can be employed to create varied motion patterns that enrich the training set, allowing the model to learn from a broader spectrum of motion scenarios. These synthetic data points help in covering gaps in the original training data.
Transfer Learning: Transfer learning techniques can be used to incorporate knowledge from pre-trained models that excel in motion capture.
By transferring learned motion representations, the T2V model can inherit sophisticated motion understanding and generation capabilities.
This method leverages the strengths of existing models to enhance the T2V model's performance.
Motion Embedding Enhancement: Improving the model's motion embeddings can help in better capturing and reproducing intricate motion details.
This can be achieved by refining the motion encoding layers of the model, ensuring they accurately represent the temporal dynamics of different actions. Enhanced embeddings allow for more nuanced and realistic motion portrayal.
Custom Motion Control: Allowing users to input specific motion instructions can further customize the generated videos.
Techniques such as motion vectors or skeleton tracking can provide explicit control over the motion trajectories, enabling the creation of videos with precise and desired movements.
This user-driven approach ensures that the generated content aligns closely with specific requirements.
Customizing motions ensures that the T2V model can generate more realistic and varied video content, catering to specific user needs and scenarios.
It addresses the limitations of the original training data and enhances the model’s flexibility and robustness in video generation.
This strategy not only improves the model’s output quality but also expands its applicability to a wider range of tasks and contexts.
Case Study: Evaluating T2V Models
When evaluating text-to-video generation models, it is essential to consider various aspects to determine the quality and effectiveness of the generated content.
One of our customers is fine-tuning multi-modal models to figure out the best model to fine-tune to provide the best generative output for the gaming industry.
In this comparison, they were assessing two different videos created by distinct models: the first one by Gen2 and the second one by PikaLabs.
For that, they prepared tens of thousands of prompts and ran those prompts to generate video output and Labellerr helped them with RLHF.
Here we discuss one example prompt, outputs, and parameters on which human evaluation has been done.
Prompt - "Harry Potter chewing while reading."
Our evaluation will focus on several criteria: visual appeal, fidelity to the text description, camera motion, object motion, and overall consistency.
By examining these factors, we aim to identify which model delivers a superior viewing experience and accurately represents the given prompt.

GEN2

PikaLabs
Evaluation questions on which human evaluator has to choose either Gen2 vs Pikalabs -
1) Which of the following videos is more pleasing to watch?
The first video (Gen2) has a more polished and cinematic look, making it more visually appealing.
The second video (PikaLabs) has a more cartoonish and less refined appearance, which might be less pleasing to some viewers.
2) Which of the two matches with text description?
The first video features a character resembling Harry Potter reading a book in a library setting, closely matching the text description.
The second video also depicts Harry Potter reading a book, but the character design and scene are less realistic and more stylized, which might not match the expected Harry Potter aesthetic as closely.
3) Do the models have Camera Motion?
The first video has smoother and more realistic camera motion, adding to its cinematic quality.
The second video has less sophisticated camera movement, which might appear less dynamic.
4) Which video has better Object Motion?
The first video shows better object motion, with more natural and fluid movements of the character and the book.
The second video has more rigid and less natural object motions, which might detract from the realism.
5) Is the video produced by the models consistent?
The first video maintains consistency in the character design, setting, and overall style throughout the video.
The second video shows some inconsistencies in the character design and animation quality.
6) Final Verdict
The first video is overall better in terms of visual appeal, matching the text description, camera and object motion, and consistency. Therefore, the first video is the better one.
Conclusion
The evaluation and fine-tuning of text-to-video models are pivotal in advancing the field of generative AI. The key points discussed include the importance of comprehensive evaluation metrics that go beyond traditional measures like FVD or IS to assess the quality of generated videos.
These metrics must evaluate visual and temporal quality, content relevance, naturalness, and semantic matching with text prompts. Despite the advancements in objective metrics, the need for human evaluation remains crucial due to the subjective nature of video quality and storytelling.
Reflecting on the potential trajectory of text-to-video technology, it is clear that the field is rapidly evolving. With the advent of more sophisticated models and algorithms, the future promises more realistic and contextually rich video content generated from textual descriptions.
This technology has the potential to revolutionize industries such as entertainment, education, and advertising, offering new ways to create and consume content.
However, the path forward is not without challenges. The computational demands of these models, the need for large and diverse datasets, and the ethical considerations of AI-generated content are all areas that require further attention. As such, there is a significant call to action for the research community and industry practitioners to collaborate.
By sharing knowledge, resources, and best practices, the community can drive innovation, address challenges, and ensure the responsible development of text-to-video technology. This collaborative effort is essential to harness the full potential of this exciting field and to navigate the complex landscape of generative AI responsibly.
FAQ
What are text-to-video models?
Text-to-video models are AI-driven systems that generate video content from textual descriptions. They use advanced machine learning techniques to interpret text and produce a sequence of images that form a coherent video, ensuring both spatial and temporal consistency with the input text.
How are text-to-video models evaluated?
Evaluation of text-to-video models involves a combination of objective metrics and human judgment. Objective metrics like Frechet Video Distance (FVD) and Inception Score (IS) assess the technical quality of videos, while human evaluators provide insights into the perceptual quality, such as naturalness and semantic alignment with the text prompts.
Why is fine-tuning important for text-to-video models?
Fine-tuning is crucial because it allows the model to adapt to specific tasks or datasets, improving its performance. It involves adjusting the model’s parameters, expanding the training dataset, and optimizing hyperparameters to enhance the quality and relevance of the generated videos.
What are the challenges in text-to-video generation?
The main challenges include computational complexity, maintaining spatial and temporal consistency across frames, and the limitations of current evaluation metrics. These challenges necessitate ongoing research and development to improve the generative capabilities of text-to-video models.
References

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
