

Evaluating & Finetuning Text-To-Audio Multimodal Models


Table of Contents
- Introduction
- Why Are We Fine-Tuning Text-to-Audio Models?
- Steps For Fine-Tuning a TTA Model
- Model Architecture of TTA Model
- Case Study:Fine-Tuning TTA Multimodal Systems for Audiobook Generation
- Challenges in Text-to-Audio Multimodal Systems
- Conclusion
- FAQ
Introduction
Text-to-Audio Multimodal (TTA) systems represent a pivotal advancement in technology, seamlessly converting textual information into audio formats to enhance accessibility, user interaction, and content dissemination.
These systems integrate sophisticated components such as Natural Language Processing (NLP) for understanding textual inputs and Speech Synthesis for generating human-like audio outputs.
The primary goal is to cater to diverse user needs, spanning from visually impaired individuals who rely on auditory interfaces to mainstream users seeking convenient access to information in situations where reading text is impractical.
TTA systems find extensive applications across various domains. In audiobooks, these systems enable the transformation of printed or digital texts into spoken narratives, enhancing the accessibility of literature for people with visual impairments and offering multitasking capabilities for others.
Moreover, in educational settings, TTA systems facilitate interactive learning experiences by converting textbooks and online content into audio formats, accommodating different learning styles and environments.
Beyond these applications, TTA systems also play a crucial role in multimedia content creation, where audio descriptions of visual elements enrich the overall user experience.
As technology continues to evolve, these systems are poised to further revolutionize how information is accessed and consumed across diverse platforms and user demographics, underscoring their profound significance in fostering inclusivity and efficiency in today’s digital age.
Why Are We Fine-Tuning Text-to-Audio Models?
To effectively leverage TTA models for the business use case, it need to be fine-tuned to improve its accuracy and performance. We'll discuss multiple where fine-tuning becomes necessary.
1. Improved Audio Quality and Naturalness:
- Reason: Pre-trained models may produce audio that sounds synthetic or unnatural. Fine-tuning helps in refining the model to generate more natural-sounding audio that closely resembles human speech.
- Example: Enhancing the intonation, pitch, and rhythm to match human-like expression and delivery.
2. Enhanced Accuracy in Pronunciation and Intonation:
- Reason: Pre-trained models might mispronounce words or lack proper intonation, especially for complex or rare words. Fine-tuning on specific datasets can correct these issues.
- Example: Ensuring correct pronunciation of technical terms or names, and proper intonation for questions or exclamatory sentences.
3. Contextual Relevance and Coherence:
- Reason: The generated audio may not always align well with the context or the sentiment of the input text. Fine-tuning ensures the audio output is contextually relevant and coherent.
- Example: Generating appropriate emotional tone and context-specific sounds (e.g., suspenseful music for a thriller audiobook).
4. Adaptation to Specific Genres or Styles:
- Reason: Different applications require different audio styles. Fine-tuning allows the model to adapt to specific genres or styles, such as formal speech, casual conversation, or dramatic narration.
- Example: Tailoring the model to generate narration suitable for audiobooks, podcasts, or educational content.
5. Reduction of Artifacts and Errors:
- Reason: Initial outputs from pre-trained models may contain audio artifacts or errors, such as background noise or clipping. Fine-tuning helps in minimizing these imperfections.
- Example: Smoothing out audio glitches and reducing unwanted noise in the background.
6. Customization for Specific Applications:
- Reason: Different use cases have unique requirements. Fine-tuning allows customization to meet the specific needs of an application, whether it's customer service, entertainment, or accessibility.
- Example: Customizing a TTA model for generating automated responses in customer service that sound polite and professional.
7. Handling of Diverse and Niche Content:
- Reason: Pre-trained models may not perform well on niche or diverse content. Fine-tuning ensures the model can handle a wide variety of content accurately.
- Example: Adapting the model to generate audio for scientific literature, poetry, or multi-lingual text.
Steps For Fine-Tuning a TTA Model
Initial Pre-Training
Pre-training serves as a foundational stage in developing text-to-audio (TTA) multimodal models. The primary objectives of pre-training these models include:
- Capturing Cross-Modal Interactions: The goal is to build a robust representation that can effectively capture the relationships between textual descriptions and their corresponding audio counterparts. This involves learning joint embeddings where the semantic meaning of a text is aligned with the acoustic features of audio.
- Generalization: Pre-training aims to develop a model that can generalize well across diverse types of text and audio data. By exposing the model to a wide range of examples, it learns versatile representations that can later be fine-tuned for specific tasks.
- Feature Extraction: Another key objective is to extract high-level features from both modalities that are rich in information and useful for downstream tasks. For text, this includes syntactic and semantic information, while for audio, it encompasses temporal, spectral, and harmonic features.
- Transfer Learning: Pre-training establishes a strong initial model that can be further fine-tuned on smaller, task-specific datasets. This transfer learning approach leverages the knowledge gained during pre-training to improve performance on specific applications with limited data.
Datasets and Resources
Several large-scale datasets are instrumental in pre-training TTA models. These datasets provide the necessary diversity and volume of examples to achieve the objectives mentioned above:
- AudioCaps: This dataset contains over 46,000 audio clips, each with multiple textual descriptions. It is derived from AudioSet and offers rich annotations that are crucial for learning the text-audio alignment.
- AudioSet: Developed by Google, AudioSet includes over 2 million 10-second audio clips from YouTube videos, categorized into 527 classes. It provides a vast amount of audio data with weak labels, which is beneficial for pre-training models to understand various audio events.
- Freesound: Freesound is a collaborative database of Creative Commons licensed sounds. It offers a wide variety of audio samples, which can be used to augment training data and increase the diversity of audio inputs.
- BBC Sound Effects: This dataset consists of over 30,000 high-quality sound effects from the BBC's archives. It includes a wide range of sounds, from natural environments to human-made noises, which help in creating a comprehensive training dataset for TTA models.
Model Architecture of TTA Model
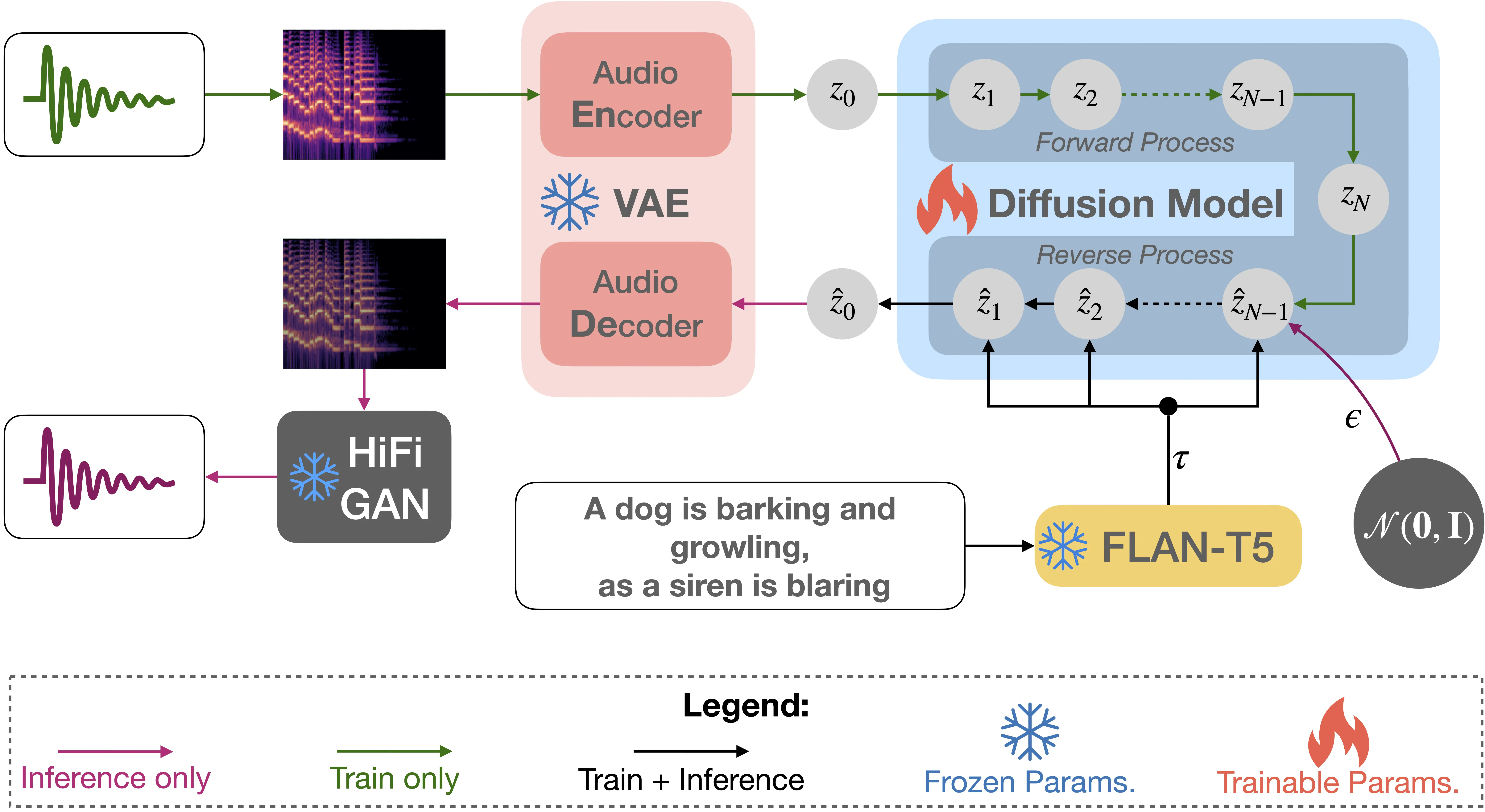
The architecture of a TTA model mentioned in (research paper)is critical in determining its ability to learn and generate high-quality audio from text. One notable architecture used in recent research is TANGO (Text And Generative Output), which employs the following components:
Text Encoder (FLAN-T5):
- FLAN-T5 (Fine-Tuned Language Model with Additions, T5): This model serves as the text encoder. FLAN-T5 is based on the T5 (Text-To-Text Transfer Transformer) framework, which treats all NLP tasks as text-to-text transformations. It is pre-trained on a large corpus of text data and fine-tuned on specific tasks.
- Role: The text encoder converts the input textual description into a high-dimensional representation that encapsulates the semantic content of the text. This encoded representation serves as the input to the subsequent stages of the TTA model.
Audio Decoder (Diffusion-Based Models):
- Diffusion Models: These models are used as audio decoders. They generate audio waveforms from the encoded text representation by progressively refining a noise signal into the desired audio output. Diffusion models are advantageous due to their ability to produce high-fidelity audio with intricate temporal structures.
- Architecture: Typically, a U-Net architecture is employed, where the network progressively denoises the input through a series of convolutional layers, capturing both global and local audio features.
Intermediate Latent Space:
- Latent Space Representation: The model uses a latent space to bridge the text and audio modalities. The latent space is designed to be modality-agnostic, meaning it can effectively represent information from both text and audio.
- Training Objective: During pre-training, the model is optimized to minimize the difference between the latent representations of paired text and audio samples. Techniques such as contrastive loss or variational methods can be employed to achieve this alignment.
Auxiliary Components:
- Attention Mechanisms: Attention layers are integrated to allow the model to focus on relevant parts of the input text when generating audio. This helps in producing more contextually appropriate audio outputs.
- Conditional Layers: Conditional layers, such as adaptive batch normalization or FiLM (Feature-wise Linear Modulation), can be used to condition the audio generation process on the encoded text features, enhancing the coherence between the text and audio.
By utilizing these architectural components and pre-training on extensive datasets, TTA models like TANGO can learn to generate high-quality audio that accurately reflects the given textual descriptions.
Evaluation Metrics
Evaluating the performance of text-to-audio (TTA) multimodal models requires a combination of objective and subjective metrics. These metrics assess the quality, relevance, and fidelity of the generated audio in relation to the input text. Here’s a detailed look at the key metrics used in this evaluation.
Objective Metrics
Objective metrics provide quantifiable measures of model performance, allowing for precise comparisons and benchmarking.
Fréchet Audio Distance (FAD):
- Definition: FAD is an adaptation of the Fréchet Inception Distance (FID) used in image generation tasks. It measures the similarity between the distribution of real audio features and the distribution of generated audio features.
- Formula:

- Application: Lower FAD values indicate that the generated audio is more similar to the real audio, suggesting higher quality. TANGO achieves state-of-the-art results on AudioCaps with a significantly lower FAD compared to other models.
Kullback-Leibler Divergence (KL):
- Definition: KL divergence measures how one probability distribution diverges from a second, reference probability distribution. It is used to compare the distribution of generated audio features to real audio features.
- Formula:
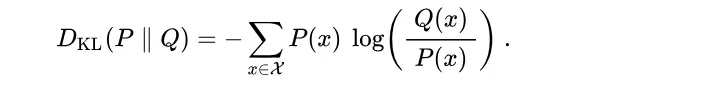
- Application: Lower KL divergence indicates that the generated audio distribution is closer to the real audio distribution, implying better performance.
Signal-to-Noise Ratio (SNR):
- Definition: SNR measures the level of the desired signal compared to the level of background noise.
- Formula:

- Application: Higher SNR values indicate clearer and more distinguishable audio signals.
Mel-Frequency Cepstral Coefficients (MFCCs):
- Definition: MFCCs are features used to characterize the short-term power spectrum of audio signals. They are commonly used in audio processing and speech recognition.
- Application: Comparing the MFCCs of generated audio to those of real audio helps in evaluating the fidelity and naturalness of the generated sound.
Subjective Metrics
Subjective metrics involve human evaluations to assess the perceptual quality and relevance of the generated audio. These evaluations are crucial because objective metrics might not fully capture the human perception of audio quality.
Mean Opinion Score (MOS):
- Definition: MOS is a common subjective measure where human evaluators rate the quality of audio on a scale, typically from 1 (bad) to 5 (excellent).
- Application: MOS scores provide an overall impression of audio quality from a listener’s perspective. TANGO’s audio outputs can be rated by human evaluators to assess their perceived quality.
Relevance and Coherence Evaluation:
- Definition: This involves assessing how well the generated audio matches the input text in terms of content, context, and coherence.
- Evaluation Process: Human evaluators compare the generated audio to the input text and rate the relevance and coherence on a scale. This helps in understanding if the audio accurately reflects the intended message of the text.
Pairwise Comparisons:
- Definition: Evaluators are presented with pairs of audio samples (e.g., from different models) and asked to choose which one better matches the given text.
- Application: Pairwise comparisons are useful for direct comparison between models, providing insights into relative performance.
Comparative Results
To illustrate the effectiveness of these metrics, consider the performance of the TANGO model:
- Fréchet Audio Distance (FAD): TANGO achieves a lower FAD score on the AudioCaps dataset compared to other models like AudioLDM and DiffSound, indicating superior audio quality and fidelity.
- Mean Opinion Score (MOS): In subjective evaluations, TANGO's generated audio receives higher MOS ratings, reflecting better perceived quality and relevance.
- KL Divergence and SNR: TANGO shows lower KL divergence and higher SNR, further confirming its ability to generate clear and accurate audio that closely matches real-world data.
Case Study: Fine-Tuning TTA Multimodal Systems for Audiobook Generation
In recent years, the demand for audiobooks has surged, driven by the growing popularity of hands-free listening experiences. Traditional audiobook production involves hiring professional narrators, studio time, and post-production work, which can be time-consuming and expensive.
To address these challenges, a leading online book retailer decided to explore the use of text-to-audio (TTA) multimodal systems to automate the narration process. The goal was to produce high-quality audiobooks with expressive, natural-sounding voices directly from text.
Why TTA Models are Needed
Challenges:
- Cost and Time Efficiency: The conventional process of producing audiobooks is labor-intensive and costly.
- Scalability: With a vast and continuously expanding catalog of books, producing audiobooks manually for each title is impractical.
- Consistency: Ensuring consistent narration quality across different narrators and recording sessions is challenging.
Solution: A TTA model can generate audio narration directly from text, providing a scalable, cost-effective, and consistent solution for audiobook production.
Initial Implementation
Pre-Training Phase: The TTA model was pre-trained on a large dataset comprising diverse audio-text pairs, such as AudioCaps and AudioSet. This phase allowed the model to learn general text-audio relationships and develop a foundational understanding of how textual information translates to audio output.
Fine-Tuning Objectives
Specialization for Audiobook Narration:
- Expressiveness: Fine-tuning aimed to enhance the model’s ability to generate expressive and engaging narration, crucial for maintaining listener interest.
- Accuracy: Improving the accuracy of pronunciation, intonation, and pacing to match professional narration standards.
- Adaptation to Literary Content: Tailoring the model to handle various literary styles, from fiction to non-fiction, and genres like fantasy, thriller, and biography.
Fine-Tuning Techniques and Strategies
Datasets:
- Targeted Dataset: A curated dataset of professionally narrated audiobook segments was used for fine-tuning. This dataset included diverse genres and styles to ensure the model could handle a wide range of content.
- Augmentation: Data augmentation techniques, such as pitch shifting and time stretching, were employed to create variations and enhance the robustness of the model.
Training Setup:
- Steps and Iterations: The fine-tuning process involved 57,000 steps, carefully monitored to avoid overfitting.
- Hardware Resources: Utilized high-performance GPUs, such as NVIDIA V100, to accelerate training and handle large datasets effectively.
- Batch Size: A batch size of 64 was selected to balance memory usage and computational efficiency.
- Learning Rate and Optimizer: A lower initial learning rate with a cosine annealing scheduler was used, along with the AdamW optimizer to ensure stable and efficient training.
Evaluation Metrics
Objective Metrics:
- Fréchet Audio Distance (FAD): Used to quantitatively measure the quality of the generated audio. The fine-tuned model achieved a significantly lower FAD, indicating improved audio quality.
- Signal-to-Noise Ratio (SNR): Higher SNR values post-fine-tuning indicated clearer and more distinct audio outputs.
- Kullback-Leibler Divergence (KL): Lower KL divergence post-fine-tuning showed better alignment between the generated and real audio distributions.
Subjective Metrics:
- Mean Opinion Score (MOS): Human evaluators rated the quality and expressiveness of the generated narration. The fine-tuned model received higher MOS ratings, reflecting its ability to produce natural and engaging narration.
- Relevance and Coherence: Evaluators assessed how well the generated audio matched the input text in terms of context and coherence. The fine-tuned model scored higher in these evaluations, demonstrating its improved performance.
Results and Impact
Performance Improvements:
- Expressiveness: The fine-tuned model generated narration with natural intonation, appropriate pauses, and emotional expressiveness, closely resembling professional human narrators.
- Accuracy: Improved pronunciation and pacing ensured that the audio output was clear and easily comprehensible.
- Listener Engagement: Higher MOS ratings indicated that listeners found the generated audiobooks more engaging and enjoyable.
Business Impact:
- Cost Savings: Significant reduction in production costs by automating the narration process.
- Scalability: Enabled the production of audiobooks at scale, allowing the retailer to quickly convert a large number of titles into audiobooks.
- Consistency: Ensured consistent narration quality across the entire catalog, enhancing the overall listener experience.
Challenges in Text-to-Audio Multimodal Systems
1. Dataset Limitations
One of the primary challenges in developing robust Text-to-Audio (TTA) multimodal systems is the availability of large-scale annotated datasets.
While datasets like AudioCaps and AudioSet provide valuable resources, they may not cover the full spectrum of linguistic diversity and acoustic environments encountered in real-world applications.
Acquiring and annotating diverse datasets that encompass various languages, dialects, and domain-specific contexts remains a significant hurdle.
2. Computational Resources:
TTA systems require substantial computational resources, especially during the training and fine-tuning phases. Transformer-based architectures and neural networks used for text encoding and audio synthesis are computationally intensive, necessitating high-performance hardware and efficient algorithms.
Scaling up models to handle large datasets and achieving real-time processing capabilities pose additional computational challenges.
3. Integration of Multimodal Information
Effectively integrating textual and audio modalities to ensure coherent and contextually relevant output remains a technical challenge.
Achieving seamless integration that enhances rather than compromises the naturalness and clarity of synthesized speech requires advanced model architectures and optimization strategies.
Conclusion
The development and fine-tuning of text-to-audio (TTA) multimodal systems represent a significant advancement in the field of artificial intelligence, offering transformative solutions across various applications.
Pre-training on large and diverse datasets like AudioCaps and AudioSet provides a solid foundation, allowing models to capture complex text-audio relationships and extract meaningful features from both modalities.
Fine-tuning these models on specific datasets, using sophisticated techniques and resources, further enhances their performance, enabling them to produce high-quality, contextually relevant audio outputs.
Metrics such as Fréchet Audio Distance (FAD), Kullback-Leibler divergence (KL), and subjective human evaluations are essential for assessing and validating the improvements, ensuring that the generated audio meets the desired standards of clarity, accuracy, and expressiveness.
The fine-tuned models not only excel in objective metrics but also receive higher ratings in subjective evaluations, reflecting their ability to produce natural and engaging audio content.
As technology continues to evolve, the potential applications of TTA systems will expand, offering personalized, multilingual, and real-time audio generation capabilities, further revolutionizing the way we interact with and consume auditory content.
FAQ
Q1: What is a Text-To-Audio (TTA) multimodal system?
A1: A TTA multimodal system is an artificial intelligence model designed to generate audio outputs from textual inputs. It leverages both text and audio data to learn the relationships between the two modalities, enabling it to produce high-quality, contextually relevant audio from a given text.
Q2: Why is pre-training important for TTA models?
A2: Pre-training is crucial because it allows the model to learn from large and diverse datasets, capturing general text-audio interactions and developing a foundational understanding. This process ensures that the model can handle a wide range of audio and text variations before being fine-tuned for specific tasks.
Q3: How does fine-tuning improve the performance of TTA models?
A4: Fine-tuning hones the model’s performance by training it on a smaller, task-specific dataset. This process allows the model to adapt to particular use cases, improving its accuracy, expressiveness, and relevance. Fine-tuning helps the model to focus on the nuances and specific requirements of the target application.
References:
1) Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model(Paper).

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
