

Enhancing Data Annotation Efficiency With YOLOv10

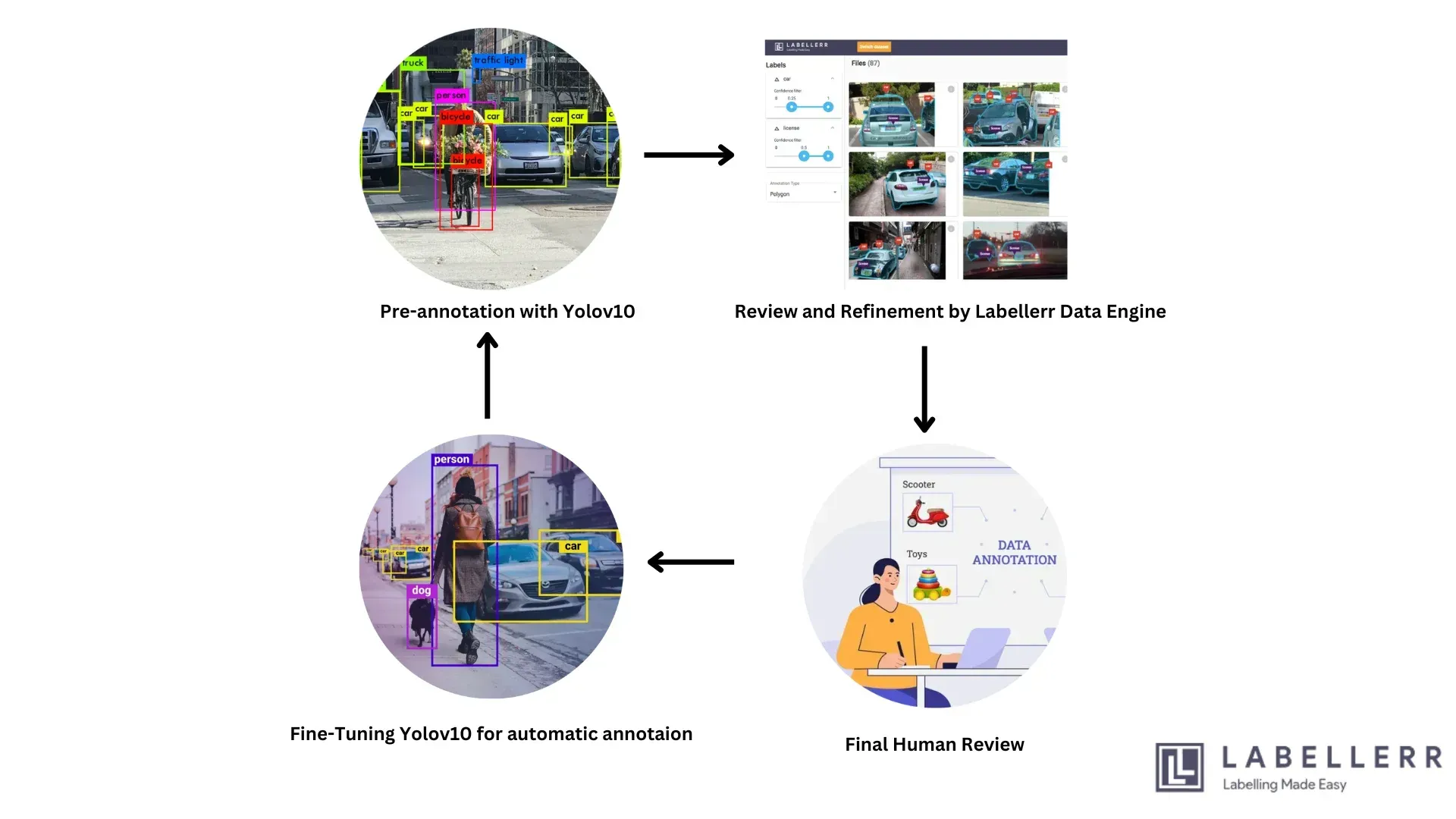
Table of Contents
- Introduction
- YOLOv10 Model Variants and Objectives
- Architectural Innovations in YOLOv10
- Benchmarking of YOLOv10
- Real-World Applications of YOLOv10
- FAQ
Introduction
Since the beginning, the YOLO (You Only Look Once) series has been a leader in real-time object recognition. Another important thing about YOLO models is that they can handle images in a single pass, which makes object detection much faster without sacrificing accuracy too much.

The newest version in this important series, YOLOv10, continues the practice of innovation by making a number of important changes to the architecture and using efficiency-driven design strategies to lower latency and improve performance even more.
YOLOv10 Model Variants and Objectives
YOLOv10 comes in various model scales to cater to different application needs:
- YOLOv10-N: Nano version for extremely resource-constrained environments.
- YOLOv10-S: Small version balancing speed and accuracy.
- YOLOv10-M: Medium version for general-purpose use.
- YOLOv10-B: Balanced version with increased width for higher accuracy.
- YOLOv10-L: Large version for higher accuracy at the cost of increased computational resources.
- YOLOv10-X: Extra-large version for maximum accuracy and performance.
YOLOv10 is designed to achieve a superior balance between speed and accuracy and address the growing demand for efficient, real-time object detection in various applications. The primary objectives of YOLOv10 are:
- Latency Reduction: By optimizing the model architecture and eliminating unnecessary computational overhead, YOLOv10 aims to significantly reduce the time taken for inference, making it even more suitable for time-sensitive tasks.
- Performance Enhancement: Alongside latency reduction, YOLOv10 seeks to improve detection accuracy and robustness, ensuring that the model can reliably identify and localize objects in diverse and challenging environments.
- Efficient Design: YOLOv10 introduces novel design strategies that enhance model efficiency, allowing it to run on a broader range of hardware, from high-end GPUs to resource-constrained edge devices.
Architectural Innovations in YOLOv10
1. Compact Inverted Bottleneck
YOLOv10 leverages a compact inverted bottleneck design to streamline the architecture, improving efficiency without sacrificing detection capabilities.
This design utilizes depth-wise separable convolutions to reduce computational complexity while maintaining high performance.
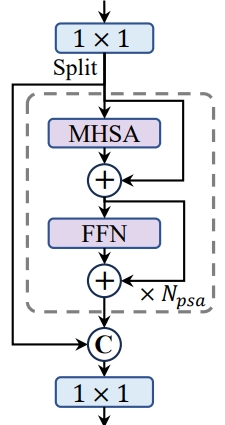
The image below shows a compact inverted block.
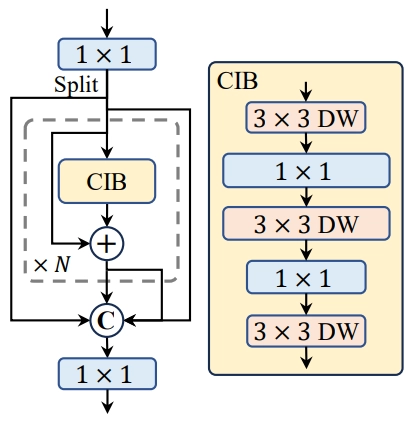
By adopting these convolutions, the model can capture more relevant features with fewer parameters, thus improving both speed and accuracy.
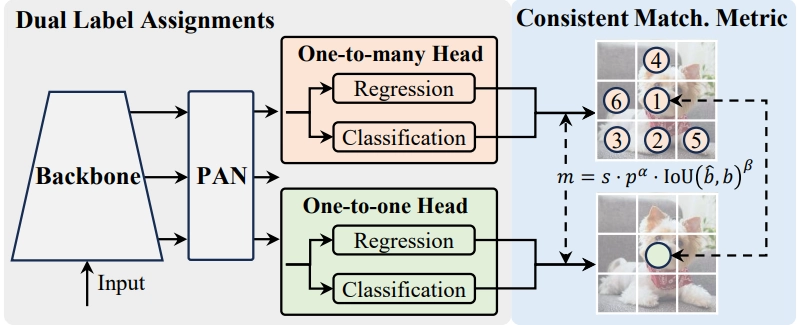
2. Consistent Dual Assignments for NMS-free Training
A groundbreaking innovation in YOLOv10 is the implementation of consistent dual assignments, which eliminates the need for Non-Maximum Suppression (NMS) during inference. This method combines the strengths of one-to-many and one-to-one label assignments:
- One-to-Many Assignment: Traditionally used in YOLO models, this approach assigns multiple positive samples for each instance, providing rich supervisory signals. However, it necessitates NMS post-processing to filter out redundant predictions.
- One-to-One Assignment: This method assigns only one prediction to each ground truth, thereby eliminating the need for NMS. However, it typically results in weaker supervision and suboptimal accuracy.
YOLOv10 harmonizes these two strategies through dual-label assignments. During training, both heads (one-to-many and one-to-one) are optimized simultaneously. The backbone and neck benefit from the robust supervision provided by the one-to-many head.
During inference, only the one-to-one head is used, which simplifies deployment and enhances inference speed without sacrificing performance.
3. Consistent Matching Metric
To ensure that the dual assignments are optimized harmoniously, YOLOv10 employs a consistent matching metric. This metric quantitatively assesses the concordance between predictions and instances.
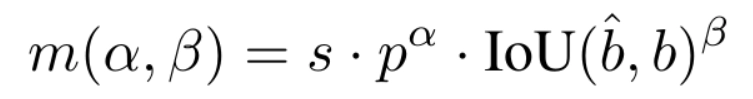
It combines the classification score and the Intersection over Union (IoU) of the bounding boxes to balance semantic prediction and location regression tasks. The consistent matching metric ensures that both heads (one-to-many and one-to-one) are optimized towards the same goal, improving the quality of predictions during inference.
4. Holistic Efficiency-Accuracy Driven Model Design
YOLOv10’s design philosophy focuses on achieving a balance between efficiency and accuracy through several key innovations:
- Lightweight Classification Head: The model uses a lightweight classification head to reduce computational overhead without significantly affecting performance. This head consists of two depth-wise separable convolutions followed by a pointwise convolution, optimizing the trade-off between computational cost and accuracy.
- Spatial-Channel Decoupled Down-sampling: YOLOv10 decouples spatial reduction and channel increase operations to achieve more efficient down-sampling. This approach reduces computational cost and parameter count, maximizing information retention and enhancing performance with reduced latency.
- Rank-Guided Block Design: By analyzing the intrinsic redundancy in each stage of the model, YOLOv10 employs a rank-guided block design to adaptively allocate compact blocks across different stages. This strategy improves efficiency without compromising the model's capacity.
5. Accuracy Driven Enhancements
YOLOv10 incorporates several accuracy-driven enhancements to boost performance:
- Large-Kernel Convolution: To enlarge the receptive field and improve feature extraction, YOLOv10 employs large-kernel convolutions in deeper stages. This approach enhances the model's ability to detect objects accurately, particularly in high-resolution images.
- Partial Self-Attention (PSA): To incorporate global representation learning while minimizing computational overhead, YOLOv10 uses a partial self-attention module. This module partition features across channels, applying self-attention to one part and then fusing the results. This design enhances the model's capability with low computational costs, improving overall performance.
Benchmarking of YOLOv10
YOLOv10 represents a significant advancement in object detection models, offering improvements over its predecessors and other contemporary models in terms of performance and efficiency.
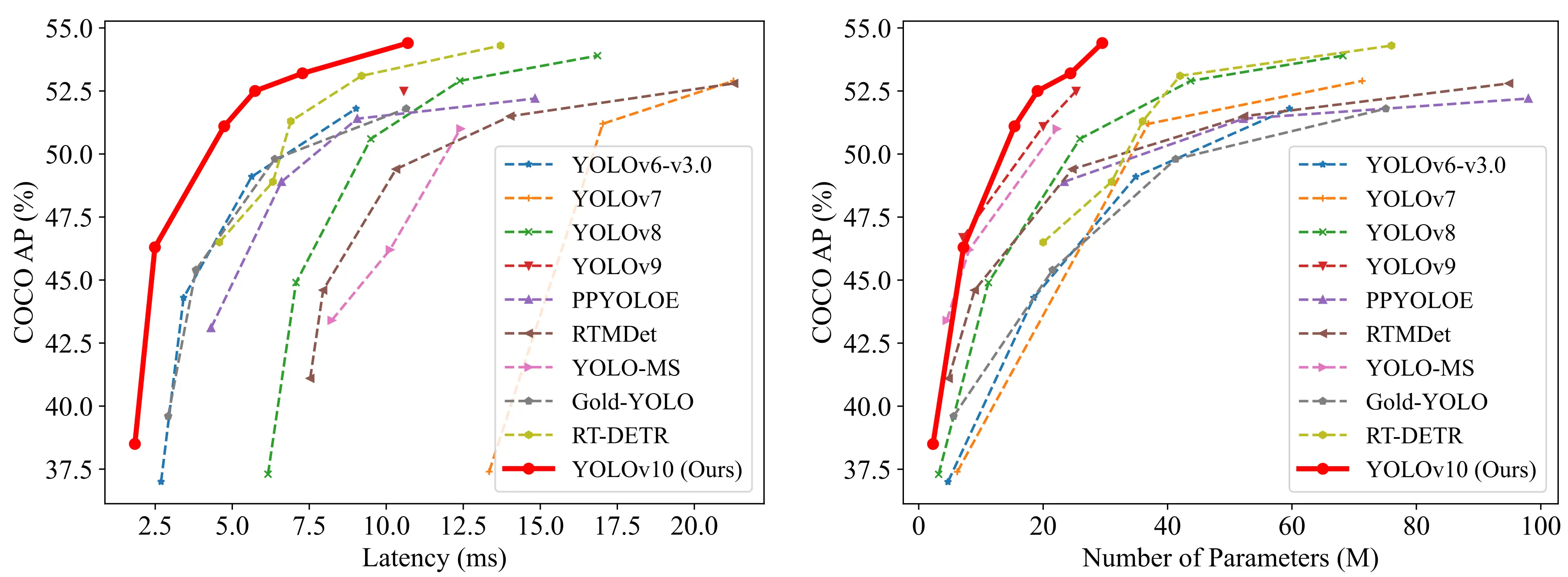
When comparing YOLOv10 with YOLOv8, several notable enhancements are evident. YOLOv10 demonstrates superior Average Precision (AP) across all model sizes, with increments of up to 1.4% in the "S" variant and 0.5% in the "M" and "X" variants. Moreover, YOLOv10 achieves substantial reductions in latency, ranging from 37% to 70%, making it much faster for real-time applications.
YOLOv10's architecture also shows advancements over YOLOv9. For example, YOLOv10-B has 46% less latency and 25% fewer parameters than YOLOv9-C while maintaining similar performance levels.
This is achieved through an NMS-free training strategy that eliminates the need for non-maximum suppression during inference, thus reducing latency and computational overhead.
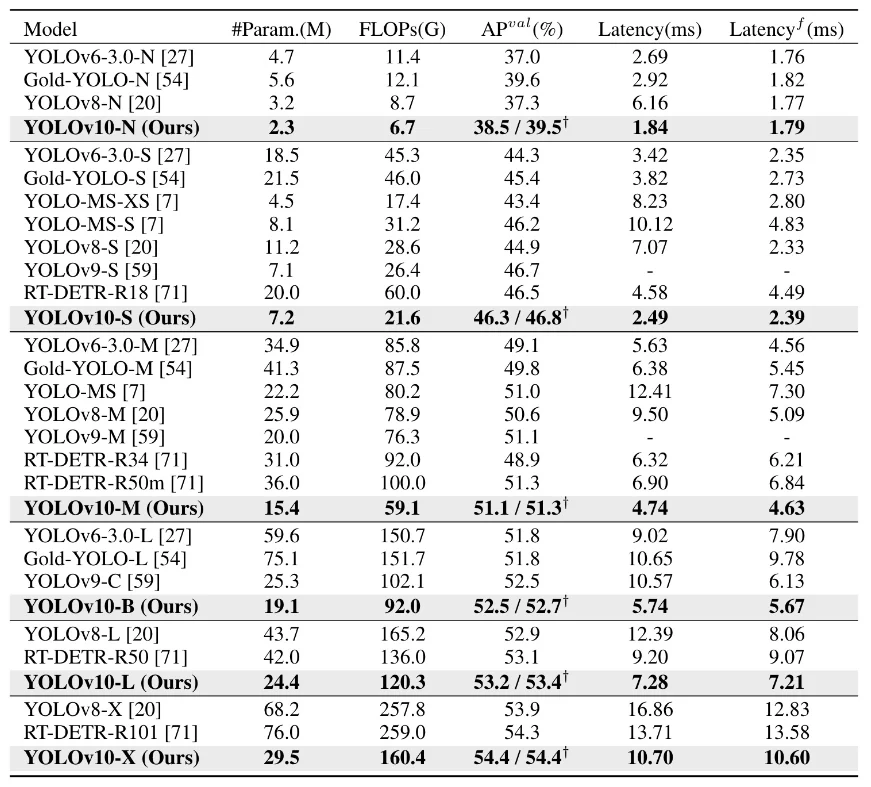
The table provided further illustrates these improvements. For instance, YOLOv10-N (Nano) has significantly lower parameters (2.3 million) and FLOPs (6.7 billion) compared to YOLOv8-N (3.2 million parameters and 8.7 billion FLOPs), while still achieving a similar if not better AP (39.5% vs. 37.3%).
This trend is consistent across other model sizes, such as YOLOv10-S and YOLOv10-M, which also show lower latency and computational requirements compared to their YOLOv8 counterparts, with improved or comparable AP values.
Real-World Applications of YOLOv10
YOLOv10, with its advanced speed and accuracy enhancements, is well-suited for a variety of real-world applications, particularly in areas where real-time object detection and low latency are critical.
1. Autonomous Driving
In the field of autonomous driving, YOLOv10 can significantly enhance the performance of self-driving cars. The ability to quickly and accurately detect objects such as pedestrians, other vehicles, traffic signs, and obstacles is crucial for the safe and efficient operation of autonomous vehicles.

The model's improvements in latency and accuracy make it ideal for:
- Pedestrian Detection: Rapid and precise identification of pedestrians helps in preventing accidents.
- Traffic Sign Recognition: Accurate detection and interpretation of traffic signs ensure compliance with road regulations and enhance safety.
- Obstacle Avoidance: Timely detection of obstacles allows for quick maneuvers to avoid collisions, improving the vehicle's responsiveness.
These capabilities are vital for creating safer and more reliable autonomous driving systems.
2. Robot Navigation
Robots used in various industries, such as logistics, manufacturing, and healthcare, benefit from YOLOv10's advancements in several ways:
- Warehouse Automation: In logistics, robots equipped with YOLOv10 can efficiently navigate warehouses, identify and pick items, and avoid obstacles. This leads to faster and more accurate order fulfillment.
- Manufacturing: In manufacturing environments, robots can detect defects on production lines, manage inventories, and perform quality control tasks with greater precision.
- Healthcare: Service robots in healthcare settings can navigate through hospitals, deliver medications, and assist with patient care, all while avoiding collisions and identifying objects of interest.
The model’s real-time detection capabilities ensure that robots can operate smoothly and effectively in dynamic environments.
3. Object Tracking
YOLOv10’s enhancements also make it highly suitable for various object-tracking applications:
- Surveillance Systems: In security and surveillance, the model can be used to track individuals or vehicles across multiple camera feeds, providing real-time alerts for any suspicious activities.

- Sports Analytics: In sports, YOLOv10 can track players and the ball, providing detailed analytics and insights for performance improvement and strategic planning.
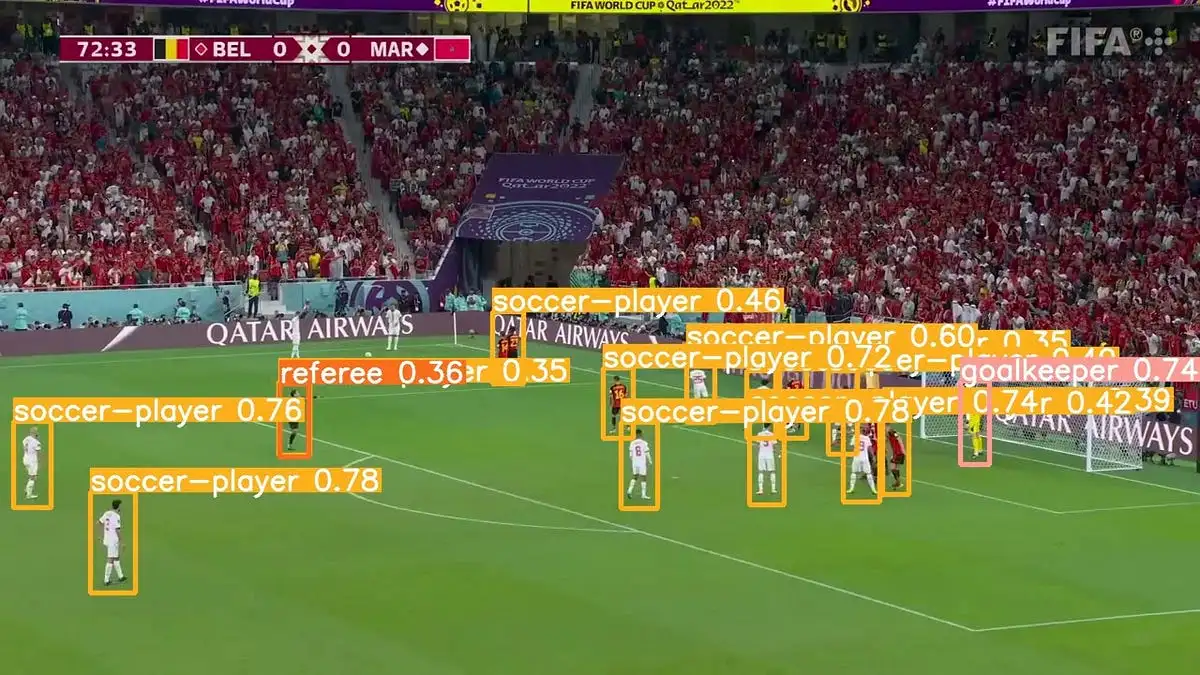
- Wildlife Monitoring: For environmental conservation efforts, YOLOv10 can be employed to track animals in their natural habitats, helping researchers gather data on movement patterns and behavior without intrusive methods.

These applications benefit from the model's ability to maintain high accuracy and low latency, ensuring reliable and timely detection and tracking.
FAQ
1. How does YOLOv10 improve the annotation process compared to previous YOLO versions?
YOLOv10 offers significant improvements over its predecessors, such as YOLOv8 and YOLOv9, in terms of efficiency and accuracy. With fewer parameters and lower FLOPs (Floating Point Operations), YOLOv10 can process images faster and with higher precision.
YOLOv10-N has an APval (Average Precision validation) of 39.5% and a latency of 1.84 ms, which is better than YOLOv8-N and Gold-YOLO-N. These improvements mean faster initial object detection, reducing the time needed for human annotators to verify and refine labels.
2. How can LabelGPT refine the annotations provided by YOLOv10?
LabelGPT refines annotations by providing contextual understanding and additional criteria that might not be evident from image data alone. After YOLOv10 generates initial bounding boxes and labels, LabelGPT reviews these annotations, using its language model capabilities to ensure consistency and accuracy.
For instance, if YOLOv10 detects an object as a "car," LabelGPT can refine this by checking the surrounding context to ensure it's labeled correctly, considering factors like the presence of a road or parking lot.
3. What is the role of human annotators in this integrated workflow?
Human annotators play a crucial role in verifying and finalizing annotations. While YOLOv10 and LabelGPT provide a robust initial annotation, human oversight ensures that any errors or ambiguities are resolved.
Annotators review the output, make necessary adjustments, and confirm the final labels. This human-in-the-loop approach maintains high annotation quality and allows the models to learn from corrections, improving future performance.
4. How does the continuous feedback loop enhance the performance of the integrated system?
The continuous feedback loop involves regular quality checks on annotated data and using this feedback to update and improve the models. By identifying and correcting errors in the annotations, the system can retrain YOLOv10 and LabelGPT with this new data, enhancing their accuracy and efficiency over time.
This iterative process ensures that the system adapts to new data and evolving annotation requirements, maintaining high performance and reliability.
References

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
