

Object Detection in Camouflaged Videos with Endow SAM


TSP-SAM, short for Temporal-spatial Prompt Learning for Video Camouflaged Object Detection also known as EndowSAM, represents an innovative enhancement of the Segment Anything Model (SAM).
This model addresses the specific challenges posed by detecting camouflaged objects in dynamic video environments.

Unlike conventional SAM, which relies heavily on static image features, TSP-SAM integrates temporal and spatial data to improve the detection of objects that blend seamlessly with their backgrounds.
By leveraging motion-driven self-prompt learning and robust prompt learning based on long-range temporal-spatial dependencies, TSP-SAM significantly enhances SAM's capabilities, making it a powerful tool for video camouflaged object detection (VCOD).
Table of Contents
- Conceptual Framework of TSP-SAM
- Motion-driven Self-prompt Learning
- Robust Prompt Learning Based on Long-range Consistency
- Temporal-spatial Injection for Representation Enhancement
- Using TSP-SAM to Fine-tune SAM Model in Data Annotation Workflow
- Step-by-step Workflow for Fine-tuning SAM Model
- Applications of Fine-tuned TSP-SAM Model
- Conclusion
- FAQ
Conceptual Framework of TSP-SAM
The conceptual framework of TSP-SAM is built upon three primary components: motion-driven self-prompt learning, robust prompt learning based on long-range consistency, and temporal-spatial injection for representation enhancement.

These components work synergistically to address the limitations of traditional segmentation models in VCOD tasks.
The core idea is to leverage both temporal and spatial cues to create more accurate and robust prompts that guide the segmentation process, enabling the detection of camouflaged objects that exhibit subtle motion patterns and low visual contrast with their surroundings.
Motion-driven Self-prompt Learning
Frequency-based Motion Perception
Motion-driven self-prompt learning is a key innovation in TSP-SAM, allowing the model to detect camouflaged objects by analyzing motion cues in video frames.
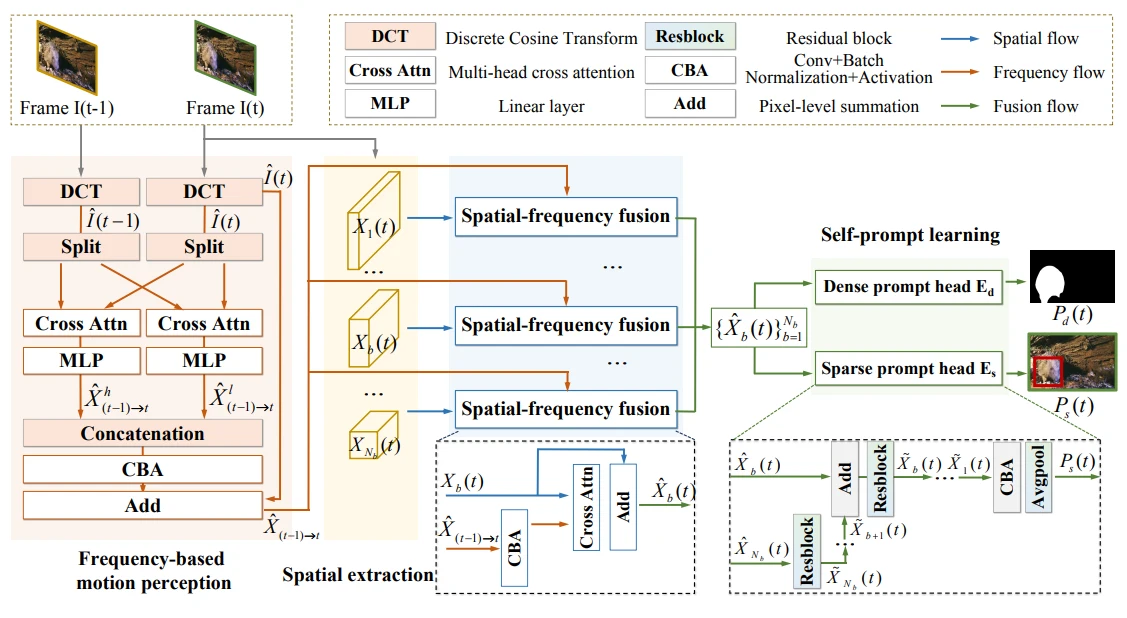
The process begins with frequency-based motion perception, which involves transforming video frames into the frequency domain to identify subtle inter-frame motion.
This transformation highlights areas with slight changes over time, which are often indicative of camouflaged objects.
By focusing on these frequency-based variations, TSP-SAM can generate initial prompts that guide the segmentation process towards potential camouflaged regions.
Spatial Identification of Camouflaged Objects
Once frequency-based motion perception identifies areas of interest, TSP-SAM proceeds with the spatial identification of camouflaged objects. This involves refining the initial prompts by analyzing the spatial relationships within the identified regions.
The model looks for consistent patterns and boundaries that may indicate the presence of an object. This step enhances the precision of the prompts, ensuring that they accurately represent the camouflaged objects within the video frames.
Robust Prompt Learning Based on Long-range Consistency
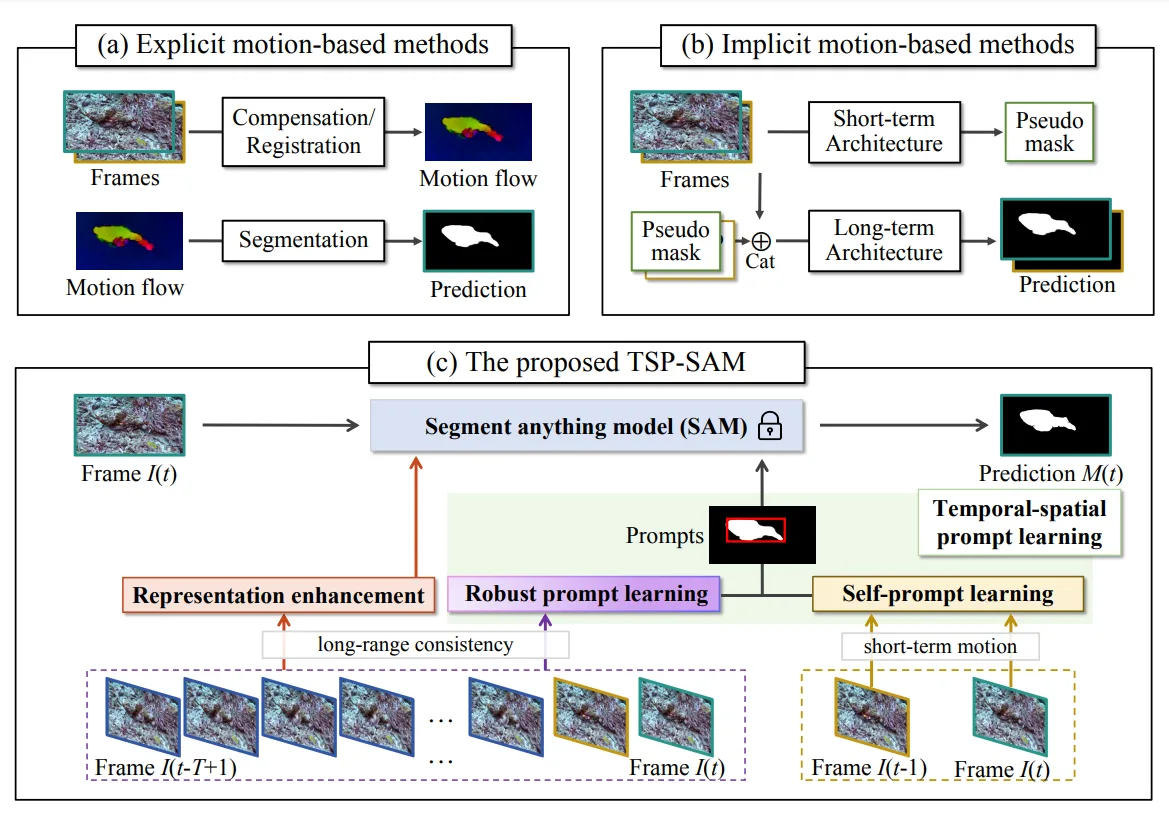
Modeling Long-range Temporal-spatial Dependencies
To further improve the robustness of the prompts, TSP-SAM incorporates robust prompt learning based on long-range temporal-spatial dependencies. This involves modeling the relationships between video frames over extended sequences, capturing both short-term and long-term changes.
By analyzing these dependencies, TSP-SAM can refine the prompts to maintain consistency across the entire video, reducing the likelihood of false positives and enhancing the detection of camouflaged objects that move or change slowly over time.
Enhancing Prompt Robustness
Enhancing prompt robustness is crucial for effective VCOD, as camouflaged objects often exhibit minimal visual cues. TSP-SAM achieves this by continuously updating and refining the prompts based on new data from subsequent frames.
This dynamic approach ensures that the prompts remain accurate and relevant throughout the video, enabling the model to adapt to changing conditions and maintain high detection performance.
Temporal-spatial Injection for Representation Enhancement
Incorporating Long-range Consistency into SAM
The final component of TSP-SAM is temporal-spatial injection, which involves incorporating long-range consistency into SAM's representation. This step integrates the refined prompts into SAM's encoder, enhancing the model's ability to represent complex temporal-spatial relationships.
By doing so, TSP-SAM leverages the comprehensive temporal and spatial information captured during the prompt learning process, enabling SAM to generate more accurate segmentation masks for camouflaged objects.
Improving Detection Precision
The integration of long-range consistency into SAM significantly improves the model's detection precision. By combining motion-driven self-prompt learning and robust prompt learning with temporal-spatial injection, TSP-SAM enhances SAM's ability to detect camouflaged objects that exhibit subtle and complex motion patterns.
This results in a more accurate and reliable VCOD model that can effectively identify camouflaged objects in various real-world scenarios, from surveillance and wildlife monitoring to autonomous driving and medical imaging.
Using TSP-SAM to Fine-tune SAM Model in Data Annotation Workflow
Introduction to Labellerr an workflow
Labellerr is a leading data annotation company that specializes in providing high-quality labeled datasets for various machine learning and computer vision applications.
The company employs a robust workflow to ensure accurate and efficient data annotation, which is crucial for training and fine-tuning advanced models like SAM.
With the introduction of TSP-SAM, Labellerr can further enhance its workflow to address the challenges of video camouflaged object detection (VCOD), leveraging the model's advanced capabilities to improve the accuracy and reliability of their annotated datasets.
Step-by-step Workflow for Fine-tuning SAM Model
Initializing the SAM Model
The first step in the workflow is to initialize the SAM model. This involves setting up the model architecture and loading any pre-trained weights that provide a good starting point for further fine-tuning.
By leveraging a pre-trained SAM model, Labellerr can benefit from the existing knowledge embedded within the model, which serves as a foundation for more specialized training with TSP-SAM.
Preparing Data for Training
Once the SAM model is initialized, the next step is data preprocessing. This involves collecting and preparing the video data that will be used for training.
The preprocessing step includes tasks such as frame extraction, resizing, normalization, and augmentation to ensure that the data is in the optimal format for training the model. Preprocessing is critical to ensure that the model can effectively learn from the data and generalize well to new, unseen video sequences.
Applying TSP-SAM Enhancements
With the data preprocessed, Labellerr can proceed with the fine-tuning process. This step involves applying the TSP-SAM enhancements to the SAM model.
TSP-SAM's advanced techniques, such as motion-driven self-prompt learning and robust prompt learning based on long-range temporal-spatial dependencies, are integrated into the training process.
These enhancements allow the model to capture and utilize temporal and spatial cues effectively, improving its ability to detect camouflaged objects in videos.
Evaluating and Optimizing the Model
After fine-tuning, the model undergoes a rigorous evaluation and optimization phase. Labellerr assesses the performance of the fine-tuned TSP-SAM model using a set of validation videos.
Metrics such as accuracy, precision, recall, and F1-score are computed to evaluate the model's effectiveness in detecting camouflaged objects. Based on the evaluation results, the model is further optimized by adjusting hyperparameters, refining prompts, and incorporating additional training data as needed.
Deploying the Fine-tuned Model
Once the model has been thoroughly evaluated and optimized, the final step is deploying the fine-tuned TSP-SAM model. The fine-tuned model is integrated into Labellerr's data annotation workflow, where it assists human annotators by providing accurate initial segmentations and identifying camouflaged objects in video sequences.
This integration not only improves the efficiency and accuracy of the annotation process but also enhances the quality of the annotated datasets, which are crucial for training other machine learning models.
Applications of Fine-tuned TSP-SAM Model
Improved Detection in Surveillance Systems
The fine-tuned TSP-SAM model significantly enhances the capabilities of surveillance systems, particularly in environments where objects may be camouflaged or hard to detect.
Traditional surveillance systems often struggle with identifying intruders or objects that blend into their surroundings, leading to missed detections and potential security breaches. TSP-SAM's advanced temporal-spatial analysis allows it to detect subtle movements and changes over time, making it adept at identifying camouflaged objects.
This improved detection capability is crucial for applications such as perimeter security, urban monitoring, and military surveillance, where precise and reliable object detection is paramount.
Precision Agriculture
In precision agriculture, the ability to detect and monitor various elements within the agricultural environment is crucial for optimizing crop production and managing resources efficiently.
The fine-tuned TSP-SAM model can be utilized to identify camouflaged pests, diseases, and even crop health issues that may not be visible to the naked eye or traditional imaging techniques. By providing accurate and timely information on these factors, TSP-SAM enables farmers to take proactive measures to protect their crops, reduce losses, and increase yield.
This application not only improves agricultural productivity but also supports sustainable farming practices by enabling targeted interventions and minimizing the use of chemicals.
Medical Imaging Analysis
Medical imaging is another domain where the fine-tuned TSP-SAM model can make a significant impact. In many cases, medical professionals need to detect and analyze features within imaging data that may be camouflaged or difficult to discern.
TSP-SAM's ability to identify subtle variations and changes over time can enhance the accuracy of diagnoses and the monitoring of disease progression. For instance, in radiology, TSP-SAM can assist in detecting tumors or lesions that blend into surrounding tissues.
In endoscopy, it can help identify abnormalities within complex anatomical structures. By improving the precision and reliability of medical imaging analysis, TSP-SAM contributes to better patient outcomes and more effective treatments.
Autonomous Driving
Autonomous driving systems rely on advanced object detection and segmentation to navigate safely and make informed decisions in real-time. The fine-tuned TSP-SAM model enhances the capabilities of these systems by accurately detecting camouflaged objects that might be missed by conventional sensors and algorithms.
For example, TSP-SAM can identify pedestrians wearing clothing that blends with the background or vehicles that are partially obscured by environmental elements. This improved detection capability ensures that autonomous vehicles can operate safely and effectively in a variety of conditions, including urban environments, rural areas, and complex traffic scenarios.
By integrating TSP-SAM into autonomous driving systems, manufacturers can enhance the safety and reliability of their vehicles, bringing us closer to the widespread adoption of autonomous transportation.
Conclusion
The introduction and application of the TSP-SAM model mark a significant advancement in the field of video camouflaged object detection (VCOD).
By leveraging innovative techniques such as motion-driven self-prompt learning, frequency-based motion perception, and robust prompt learning based on long-range temporal-spatial dependencies, TSP-SAM enhances the capabilities of the Segment Anything Model (SAM) to effectively detect camouflaged objects in dynamic video environments.
This enhancement addresses the limitations of traditional segmentation models, which often struggle with detecting objects that blend seamlessly into their surroundings.
Through a detailed workflow, we have demonstrated how a data annotation company like Labellerr can fine-tune the SAM model using TSP-SAM.
The step-by-step process involves initializing the SAM model, preparing data for training, applying TSP-SAM enhancements, and evaluating and optimizing the model.
This workflow ensures that the fine-tuned TSP-SAM model can be effectively integrated into Labellerr's annotation process, significantly improving the accuracy and efficiency of video annotations.
The applications of the fine-tuned TSP-SAM model are vast and impactful. From improved detection in surveillance systems and enhanced wildlife monitoring to precision agriculture, medical imaging analysis, and autonomous driving, TSP-SAM's advanced capabilities provide significant benefits across multiple domains.
Its ability to detect camouflaged objects with high accuracy and reliability makes it an invaluable tool for various real-world applications, contributing to greater safety, efficiency, and effectiveness.
FAQ
1. How does camouflaged object detection differ from traditional object detection?
Camouflaged object detection (COD) involves identifying objects that are designed to blend into their surroundings, making them much harder to detect than regular objects.
Traditional object detection methods often rely on clear visual contrasts between objects and their backgrounds, while COD requires specialized techniques to detect subtle differences in texture, motion, and other features that distinguish camouflaged objects from their environments.
This often involves advanced algorithms and models that can analyze temporal-spatial data to spot these elusive objects.
2. What are the main challenges in camouflaged object segmentation?
The primary challenges in camouflaged object segmentation include:
- Low Contrast: Camouflaged objects have minimal visual contrast with their backgrounds, making them hard to distinguish.
- Complex Backgrounds: Natural environments often have complex and variable backgrounds, increasing the difficulty of segmentation.
- Motion Blur: In videos, motion blur can obscure the subtle movements that indicate the presence of camouflaged objects.
- Scale Variation: Objects can appear at different scales and orientations, requiring models to be adaptable and robust.
- Data Scarcity: There is a lack of large, annotated datasets specifically for camouflaged object detection, which can hinder model training and evaluation.
3. Can camouflaged object detection models be generalized across different environments?
Generalizing camouflaged object detection models across different environments is challenging but possible with advanced techniques.
Models need to be trained on diverse datasets that include various types of camouflage and background environments. Techniques like transfer learning and domain adaptation can help models generalize better by leveraging knowledge from similar tasks or domains.
However, continual retraining and fine-tuning with environment-specific data are often necessary to maintain high detection accuracy across different settings.
References
Arxiv Paper (Link)

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
