

How to Build an End-to-End ML Pipeline
This guide covers building an end-to-end ML pipeline in Python, from data preprocessing to model deployment, using Scikit-learn. It emphasizes automation, efficiency, and scalability with hands-on steps for data exploration, model selection, and prediction generation.


Introduction
Machine learning (ML) pipelines are essential for automating the workflow of training and deploying machine learning models.
These pipelines enable data engineers and data scientists to seamlessly process raw data, train models, evaluate them, and deploy them into production, making the entire process efficient and repeatable.
Building an end-to-end ML pipeline involves various stages, including data ingestion, data preprocessing, model training, evaluation, and deployment.
According to a survey by Algorithmia, 55% of companies surveyed have not deployed an ML model., largely due to the complexity of managing data workflows and deployment processes.
The goal of an ML pipeline is to automate these processes, ensuring that models are robust, scalable, and ready for production.
Whether you're handling a small dataset or deploying a machine learning model on a large scale, creating a well-structured pipeline helps streamline operations and enables faster iteration on model improvements.
Building a scalable and reproducible machine learning model can be overwhelming.
In this article, we’ll guide you through the steps of building an end-to-end machine learning pipeline using Python and scikit-learn to simplify your workflow, ensure accuracy, and accelerate deployment."
What is Machine Learning Pipeline?
Machine learning pipeline refers to the complete workflow and processes of building and deploying a machine learning model.
It automates and standardizes the workflow involved in creating a machine-learning model.
A machine learning pipeline consists of sequential steps, which include data extraction and preprocessing to model training and deployment.
It is a central product for data science teams, incorporating best practices and enabling scalable execution.
Whether managing multiple models or frequently updating a single model, an end-to-end machine learning pipeline is essential for effective and efficient implementation.
Benefits of an End-to-End ML Pipeline
The benefits of having an end-to-end machine-learning pipeline are many, some of which include the following:
- Ensure reproducibility: By executing the pipeline multiple times with the same inputs, we achieve consistent outputs, which enhances the reproducibility and reliability of machine learning models.
- Simplify workflow: The pipeline automates multiple steps in the machine learning workflow. This reduces the need for manual intervention from the data science team, making the process more efficient and streamlined.
- Accelerate deployment: The pipeline helps reduce the time data and models take to the production phase. This enables faster deployment of machine learning solutions and quicker integration into real-world applications.
- Enable focus on innovation: With modular components and automation in place, the pipeline frees the data science team to focus more on developing new solutions rather than spending excessive time maintaining existing ones.
- Facilitate reusability: Specific steps can be reused to develop and deploy end-to-end solutions, allowing for seamless integration with existing systems without the need to start from scratch each time.
Table of Contents
- Introduction
- Developing a Primary End-to-End Machine Learning Pipeline
- Custom Machine Learning Pipeline
- Data Exploration and Preprocessing
- Model Selection and Training
- Creating an ML Pipeline for Prediction
- Conclusion
- Frequently Asked Questions (FAQ)
Developing a primary end-to-end machine learning Pipeline
Sklearn offers a range of powerful methods for various machine learning steps, including Column Transformer, Standard Scaler, One-Hot Encoder, Simple Imputer, and more.
These methods provide convenient solutions for data scientists, simplifying their work processes.
While this article doesn't delve into a detailed explanation of each method to keep the reading time short, it highlights the usage of several models in building ML pipelines, as demonstrated in the example below.
1. Custom Machine Learning Pipeline
While Sklearn offers a wide range of models for building machine learning pipelines, such as Iterative Imputer, Normalizer, and Label Encoder, this article focuses explicitly on custom models.
The Sklearn website provides comprehensive documentation for these models, allowing users to explore their functionalities in detail.
To understand how to build a custom machine-learning pipeline, we take an example of the Bike sharing dataset, which is accessible for download here.
This dataset comprises information on the number of bikes rented during specific hours and other relevant features. Our objective is to construct a model that can forecast the number of bikes that will be rented using these features.
2. Data exploration and preprocessing
The consensus among most machine learning practitioners is that data exploration and preprocessing constitute a significant portion of their work.
This is because the available data often comes with challenges, such as incompleteness or an unsuitable format for direct usage.
First, we will import the necessary libraries and load the data into our notebook. This will enable us to perform the required data exploration and preprocessing tasks.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
import math
import sklearn.metrics
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline
data = pd.read_csv('./Data/hour.csv')
data.head()

We can obtain a summary of the dataset by using the DataFrame.info() method from Pandas.
This method provides information about the column names, the number of non-null rows, and the data types of each column. This summary helps us understand the structure and characteristics of the dataset used.
data.info()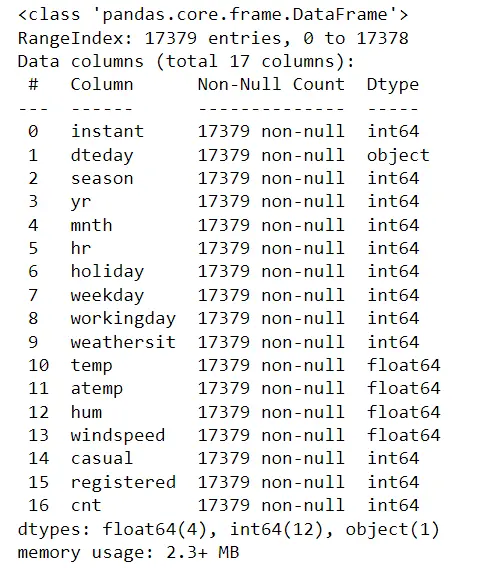
data.columns

There are no missing values in the data. However, the column names could be more descriptive and readable. Let's rename the columns to make them more informative and easier to understand.
data.rename(columns = {'instant':'index', 'dteday':'datetime',
'yr':'year', 'mnth':'month', 'holiday':'is_holiday',
'workingday':'is_workingday','weathersit':'weather_conditions','hum':'humidity',
'hr':'hour', 'cnt':'count'}, inplace = True)
data.head()
We excluded the 'record_id' column as it provided no valuable information regarding bike rentals.
Additionally, we combined the 'casual' and 'registered' columns into a single column called 'count' to avoid data leakage.
This precaution prevents the model from learning from information in the training data that may not be present in the test set. This ensures better performance when the model is deployed in production.
data.drop(['index','casual','registered'], axis = 1, inplace = True)
The columns in the dataset have different data types, and we need to convert them to the most suitable data type for each column. This ensures that the data is represented accurately and efficiently.
data['datetime'] = pd.to_datetime(data.datetime)
# categorical variables
data['season'] = data.season.astype('category')
data['is_holiday'] = data.is_holiday.astype('category')
data['weekday'] = data.weekday.astype('category')
data['weather_conditions'] = data.weather_conditions.astype('category')
data['is_workingday'] = data.is_workingday.astype('category')
data['month'] = data.month.astype('category')
data['year'] = data.year.astype('category')
data['hour'] = data.hour.astype('category')plt.figure(figsize = (8,6))
sns.heatmap(data.corr(),annot = True, cmap = 'BrBG')
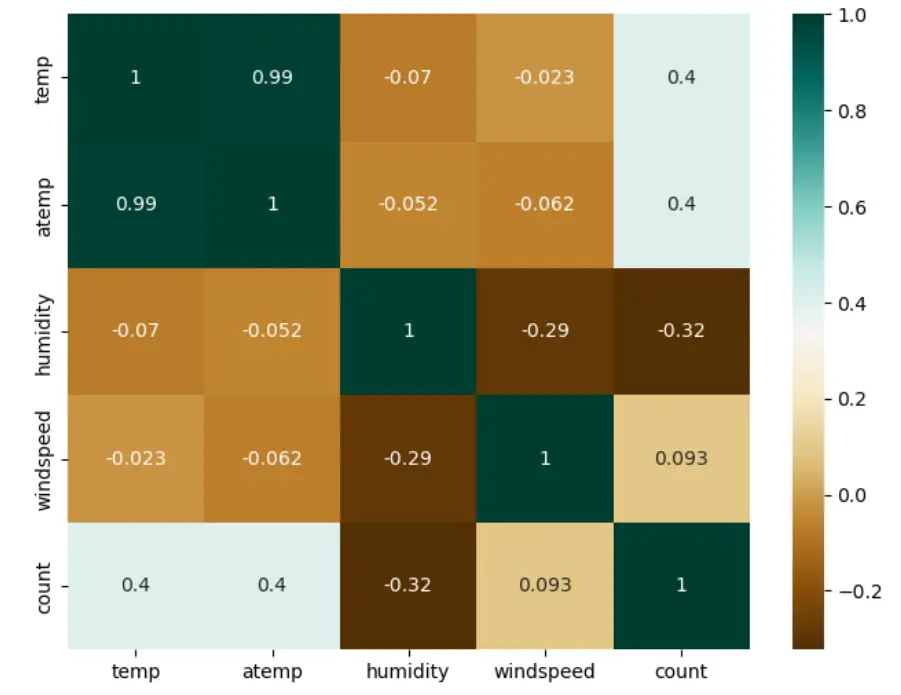
Figure: Heatmap for feature correlation
To mitigate the issue of multicollinearity, we have decided to remove the 'atemp' column from our dataset.
This is due to the strong correlation between the 'temp' and 'atemp' features. By eliminating one of these variables, we can avoid the potential problem of multicollinearity, which arises when independent variables are highly interrelated and can be predicted from one another.
This step allows us to maintain the integrity of our model and accurately assess the individual effects of the remaining variables.
data.drop(['atemp'], inplace = True, axis = 1)
data.head()

In addition, we will exclude the 'datetime' column from our dataset. With the data cleaning process now finished, we can train our model.
First, we define our features (X) and target variable (Y). The dataset is then split into training and test sets using the train_test_split() function from scikit-learn.
The split is performed in a ratio of 80% for training data and 20% for testing data. This division effectively allows us to evaluate our model's performance on unseen data.
data.drop(['datetime'], axis = 1, inplace = True)
Y = data['count']
X = data.drop('count', axis = 1)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.20)3. Model Selection and Training
For the model selection part, we try 2 different models, which include:
We train the model of our dataset and then select one based on models performance. The metric used in our case is root mean squared error.
- Linear Regression
Linear regression is a statistical model fitting a linear equation to a dataset to minimize the difference between the observed and predicted values.
The goal is to find the best coefficients (w1, ..., wp) that minimize the sum of squared differences between the actual and predicted values.
The linear regression model approximates the relationship between the input and target variables by finding the line that best fits the data points.
Below attached is the code for using Linear regression on our dataset. As we have performed the regression task, we have used root mean squared error as the loss function.
model = LinearRegression()
model.fit(X_train, Y_train)
pred = model.predict(X_test)
mse = sklearn.metrics.mean_squared_error(Y_test, pred)
rmse = math.sqrt(mse)
print(rmse)137.39450694606478
- Random Forest Regressor
The random forest algorithm is a powerful method for classification tasks. It involves creating multiple decision trees on different subsets of the dataset and combining their predictions to improve accuracy and prevent overfitting.
The size of each subset can be controlled using the max_samples parameter. By default, the algorithm uses bootstrap sampling, which means each subset is created by randomly selecting data points with replacements from the original dataset.
model_2 = RandomForestRegressor(n_estimators = 200, max_depth = 15)
model_2.fit(X_train, Y_train)
pred = model_2.predict(X_test)
mse = sklearn.metrics.mean_squared_error(Y_test, pred)
rmse = math.sqrt(mse)
rmse43.7065261288683
Since the random forest regression model exhibits a lower root mean squared error (RMSE) value, it can be considered a superior model to linear regression.
Hence, we will employ the random forest regression model to construct the machine learning pipeline.
Creating an ML Scikit-learn Pipeline for Prediction
Scikit-learn offers convenient pipeline creation functions, namely sklearn.pipeline and sklearn.make_pipeline. These functions simplify the construction of pipelines by providing streamlined implementations.
You can refer to the documentation to learn more about make_pipeline and explore all the parameters of the sklearn.pipeline.
In the following code, we construct a pipeline based on the data and steps we previously worked on:
- Load the data.
- Perform data preprocessing.
- Split the data.
- Apply transformations to the data using the fit() method.
- Finally, predict the output on the test set and evaluate the performance of the model.
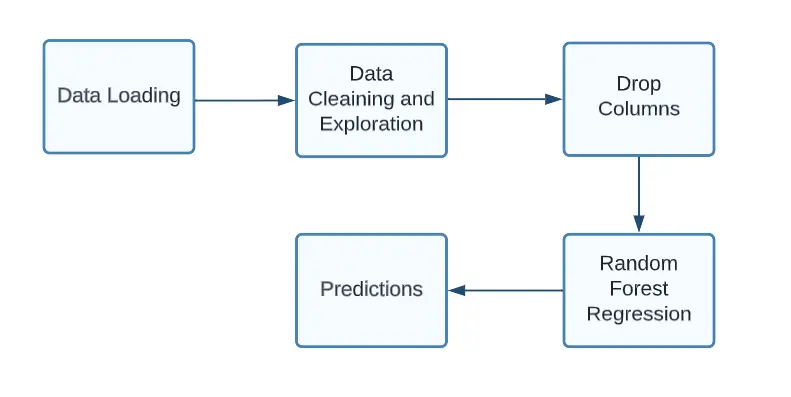
Figure: Flowchart Pipeline for our model (Image by author)
To create an end-to-end pipeline, we import Pipeline, which is provided via the scikit-learn package.
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.pipeline import Pipeline
pipeline = Pipeline(steps = [
('model',model_2)
])
model = pipeline.fit(X_train, y_train)
predictions = pipeline.predict(X_test)
print(math.sqrt(sklearn.metrics.mean_squared_error(Y_test, predictions)))43.7065261288683
Conclusion
Creating an end-to-end machine learning pipeline is crucial for automating and streamlining the model development process.
This guide demonstrated how to build a robust pipeline using Python and scikit-learn, covering essential steps like data preprocessing, model training, and evaluation.
We compared a linear regression model and a random forest regressor, ultimately selecting the latter for its superior performance. By integrating these components into a cohesive pipeline, we ensured reproducibility and facilitated quicker deployment.
Ultimately, leveraging machine learning pipelines enables data scientists to focus on innovation, enhance model performance, and efficiently manage complex workflows, making them essential for successful data science projects.
Frequently Asked Questions (FAQ)
What is an End-to-End Machine Learning Pipeline?
An end-to-end machine learning pipeline automates machine learning workflow by handling data processing, integration, model creation, evaluation, and delivery. It streamlines the implementation of the model and enhances its flexibility.
What are the fundamental stages in an ML pipeline?
Stages of a Machine Learning Pipeline
- Data Preprocessing. The initial stage of any pipeline involves data preprocessing. ...
- Data Cleaning. Following data preprocessing, the data proceeds to the cleaning stage.
- Feature Engineering.
- Model Selection.
- Prediction Generation.
What are the various categories of ML pipelines?
ML pipelines can be categorized into two main types: Transformer and Estimator. A Transformer operates on a dataset and generates an enhanced version of the dataset as output. For example, a tokenizer is a Transformer that converts a text dataset into a dataset with tokenized words.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
