

Efficient Tuning LLMS: Optimize Performance with Fewer Parameters


Table of Contents
- Introduction
- Parameter-Efficient Fine-Tuning Methods
- Adapter Tuning
- Prefix Tuning
- Prompt Tuning
- Low-Rank Adaptation (LoRA)
- Conclusion
Introduction
Tuning plays a crucial role in the development and effectiveness of Language Models (LLMs). LLMs are pre-trained on vast amounts of text data to acquire language comprehension and generation abilities.
However, fine-tuning or tuning is necessary to adapt them to specific tasks or improve their performance. Till now, we have seen that Tuning in LLMs causes:
- Task-specific Adaptation: LLMs undergo pre-training to learn general language patterns and knowledge. However, they may not possess task-specific capabilities initially. Tuning allows LLMs to be adapted to specific tasks by fine-tuning them on task-specific datasets.
- Enhanced Generalization: Tuning enhances the generalization abilities of LLMs. While pre-training provides a solid foundation, fine-tuning LLMs on task-specific data improves their ability to handle diverse inputs and generate accurate outputs.
In the previous blogs, we highlighted the instruction tuning and alignment tuning methods for adapting LLMs to specific objectives.
However, given the large number of parameters in LLMs, performing complete parameter tuning can be costly.
In this blog, we focus on efficient tuning techniques for LLMs. It begins by examining various parameter-efficient fine-tuning methods for Transformer language models and then provides an overview of existing research on parameter-efficient fine-tuned LLMs.
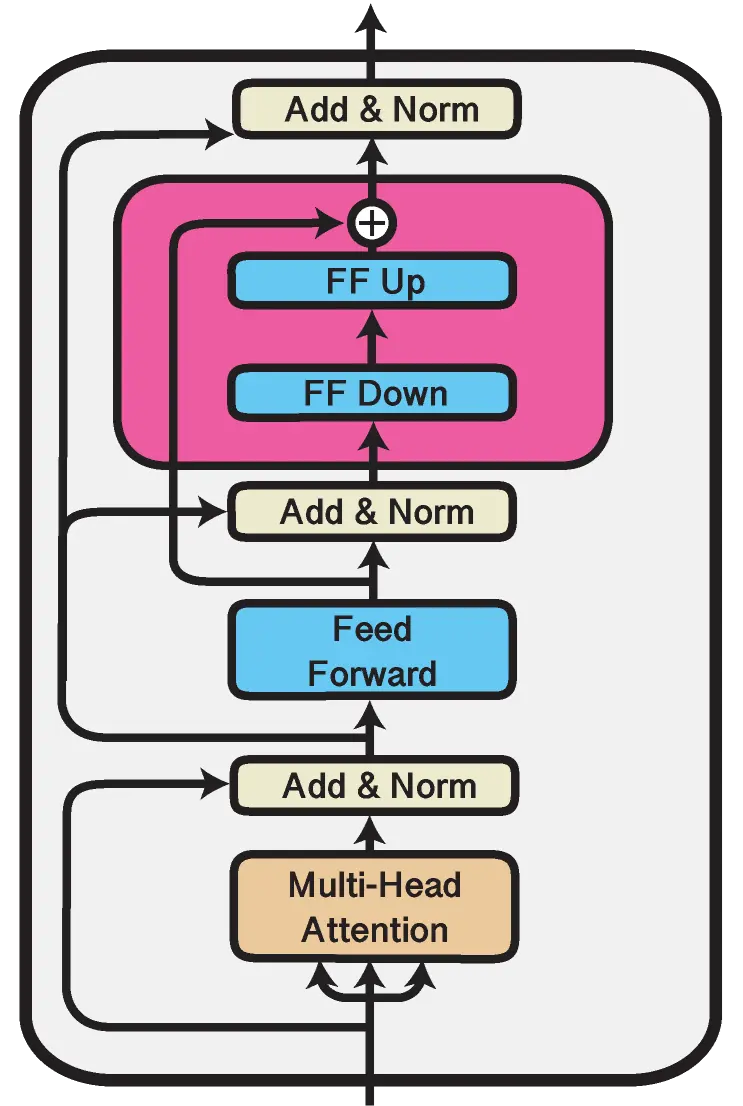
Figure: Adapter Transformer v3 Architecture
Parameter-Efficient Fine-Tuning Methods
Parameter-efficient fine-tuning methods are a significant area of research in developing Language Models (LLMs).
These methods aim to reduce the number of trainable parameters in LLMs while maintaining their performance.
In the existing literature, several parameter-efficient fine-tuning methods have been proposed for Transformer language models: adapter tuning, prefix tuning, prompt tuning, and LoRA.
Adapter Tuning
Adapter tuning is a technique that involves incorporating small neural network modules called adapters into Transformer models. These adapter modules serve as additional components within each Transformer layer.
One common implementation is a bottleneck architecture, where the original feature vector is compressed into a lower-dimensional representation using a nonlinear transformation and then expanded back to the original dimension.
These adapter modules can be inserted serially after each Transformer layer's attention and feed-forward layers or in parallel with them.
During the fine-tuning process, the adapter modules are optimized specifically for the task at hand, while the parameters of the original language model remain frozen.
This reduces the number of trainable parameters during fine-tuning, making the process more efficient.
By integrating adapter modules into the Transformer architecture, the model can be adapted to different tasks without requiring extensive modifications to the core parameters of the language model.
Prefix Tuning
Prefix tuning is a technique used in language models where a sequence of trainable continuous vectors, known as prefixes, is added to each Transformer layer.
These prefixes are task-specific and can be considered as virtual token embeddings. The optimization of prefix vectors is achieved using a reparameterization trick.

Figure: Prefix Tuning
Instead of directly optimizing the prefixes, an MLP function is learned, which maps a smaller matrix to the parameter matrix of prefixes.
This reparameterization trick helps in achieving stable training. Once the optimization is complete, the mapping function is discarded, and only the derived prefix vectors are retained to enhance task-specific performance.
This approach focuses on training only the prefix parameters, making it a parameter-efficient model optimization method.
Prompt Tuning
Prompt tuning is a technique that differs from prefix tuning and focuses on incorporating trainable prompt vectors at the input layer of language models.
It builds upon discrete prompting methods and expands the input text by including soft prompt tokens in either a free or prefixed form. These prompt-augmented inputs are then used to solve specific downstream tasks.
In the implementation, task-specific prompt embeddings are combined with the input text embeddings and fed into the language models.
It is important to note that prompt tuning refers to a category of efficient tuning methods exemplified by various works, including prefix-based tuning methods.
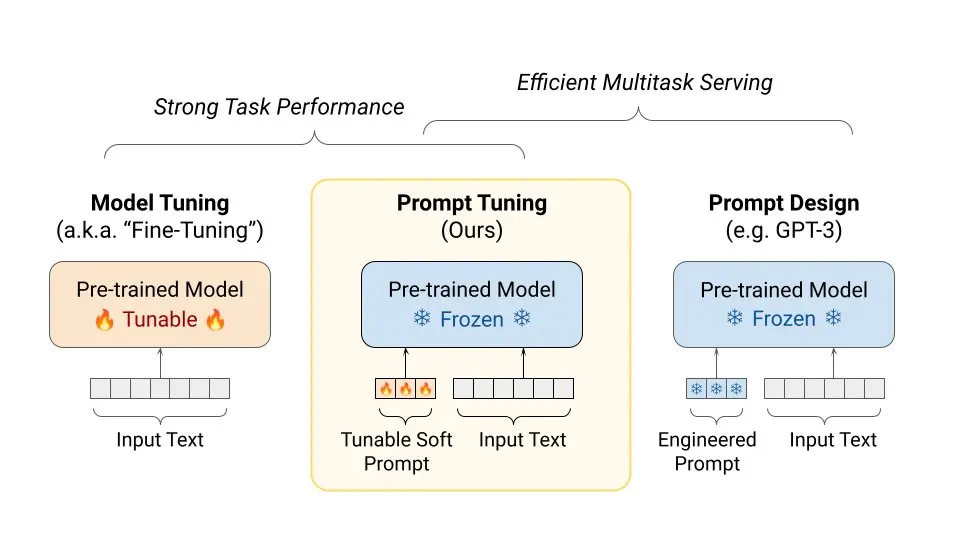
Figure: Prompt Tuning
The distinction lies in including prompt tokens, specifically at the input layer of language models. The effectiveness of prompt tuning is closely tied to the model capacity of the underlying language models.
Low-Rank Adaptation (LoRA)
LoRA is a parameter-efficient fine-tuning method that imposes a low-rank constraint on the update matrix at each dense layer of a language model.
By approximating the update matrix with low-rank decomposition matrices, LoRA reduces the number of trainable parameters for adapting to downstream tasks.
The original parameter matrix is frozen while the update ∆W is expressed as the product of two trainable matrices, A and B, with a reduced rank, r.
This approach significantly reduces memory and storage usage, allowing for a single large model copy and multiple task-specific low-rank decomposition matrices for different tasks.
Various studies have proposed methods to determine the rank in a more principled manner, such as importance score-based allocation and search-free optimal rank selection.
.webp) Low-Rank Adaption for Large Language Models
Low-Rank Adaption for Large Language Models
Figure: Low-Rank Adaption for Large Language Models
Conclusion
In conclusion, tuning is vital to developing Language Models (LLMs) to enhance their task-specific adaptation and generalization abilities. Efficient tuning techniques have been explored to reduce the number of trainable parameters in LLMs while maintaining performance.
Parameter-efficient fine-tuning methods, such as adapter tuning, prefix tuning, prompt tuning, and LoRA, have been proposed for Transformer language models.
Adapter tuning incorporates small neural network modules called adapters into the Transformer architecture, allowing task-specific optimization while keeping the original language model parameters fixed.
Prefix tuning involves adding trainable prefix vectors to each Transformer layer and optimizing them through a reparameterization trick.
Prompt tuning incorporates trainable prompt vectors at the input layer of language models, augmenting the input text to solve specific tasks.
LoRA imposes a low-rank constraint on the update matrix, approximating it with low-rank decomposition matrices to reduce trainable parameters.
Further research and development in efficient tuning techniques for LLMs continue to expand, providing a broader understanding of optimizing these models with fewer parameters.
These advancements contribute to LLMs' overall efficiency and effectiveness in various natural language processing tasks.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
