

DPO vs PPO: How To Align LLM
Direct Preference Optimization (DPO) and Proximal Policy Optimization (PPO) are two approaches to align Large Language Models with human preferences. DPO focuses on human feedback to optimize models directly, while PPO uses reinforcement learning for iterative improvements.


Large Language Models (LLMs) are transforming how we interact with and leverage technology across a wide range of applications.
From crafting compelling content to providing real-time customer support and advancing natural language processing (NLP) capabilities, these models are reshaping entire industries.
However, as their capabilities grow, so do the challenges associated with aligning them to meet ethical standards, safety requirements, and specific user needs.
In this blog, we’ll explore the importance of LLM alignment, delve into the workings of DPO and PPO, and discuss their ideal use cases. We’ll also examine the limitations of PPO that led to the development of DPO.
Table of Contents
- The Importance of LLM Alignment
- Understanding DPO and PPO
- Scenarios Where DPO is a Better Choice
- Scenarios Where PPO is a Better Choice
- Limitations of PPO Leading to the Development of DPO
- Conclusion
- FAQs
The Importance of LLM Alignment
LLM alignment refers to the process of ensuring that a language model's behavior aligns with human values and intentions.
LLMs can generate harmful, biased, or misleading content without proper alignment. Consider the potential consequences of an LLM spreading misinformation or perpetuating stereotypes.
Developing methods that steer LLMs toward producing safe, helpful, and unbiased outputs is imperative.
DPO and PPO: Two Paths to Alignment
Two prominent approaches have emerged for aligning LLMs: Direct Preference Optimization (DPO) and Proximal Policy Optimization (PPO). These methods represent distinct strategies for training language models to adhere to human preferences.
- Direct Preference Optimization (DPO): This method directly optimizes the model's parameters based on human feedback on generated outputs. It aims to learn a policy that maximizes human satisfaction.
- Proximal Policy Optimization (PPO): PPO, a reinforcement learning algorithm, trains the model to maximize a reward signal provided by human evaluators. It focuses on improving the model's policy iteratively while maintaining stability.
Understanding DPO and PPO
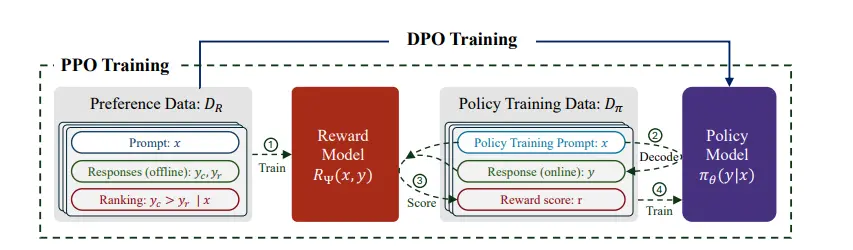
Direct Preference Optimization (DPO)
DPO is a relatively new approach to LLM alignment that directly optimizes the model's parameters based on human preferences. This method bypasses the traditional two-step process of training a reward model and then using reinforcement learning to optimize the LLM.
How DPO Works-
- Data Collection: Gather a dataset of model outputs and corresponding human preferences. These preferences can be of rankings, ratings, or binary comparisons.
- Model Initialization: Initialize the model with random parameters.
- Preference Modeling: Develop a loss function that measures the discrepancy between the model's outputs and human preferences.
- Parameter Update: To minimize the loss function, update the model's parameters using gradient descent or similar optimization algorithms.
- Iteration: Repeat steps 3 and 4 until the model converges satisfactorily.
Advantages of DPO:
- Direct Optimization: DPO directly targets human preferences, potentially leading to faster and more effective alignment.
- Reduced Bias: By eliminating the intermediate reward model, DPO can mitigate the risk of inheriting biases from the training data.
- Efficiency: DPO can be more efficient regarding data and computational resources than traditional methods.
Proximal Policy Optimization (PPO)
PPO is a reinforcement learning algorithm widely used for training complex policies, including those for LLMs. It focuses on improving the model's policy iteratively while maintaining stability.
How PPO Works:
- Policy Initialization: Initialize a policy (a function that maps states to actions).
- Data Collection: Collect data by interacting with the environment using the current policy.
- Estimate Advantage: Calculate the advantage function, which measures how much better an action is compared to the average action.
- Update Policy: Update the policy using gradient ascent, ensuring that the new policy is not too different from the old one (using a clipping function).
- Iteration: Repeat steps 2-4 until the policy converges to an optimal solution.
Strengths of PPO:
- Stability: PPO's careful policy updates help prevent drastic changes, ensuring the model's behavior remains controlled.
- Efficiency: It is computationally efficient and can handle complex reward landscapes.
- Flexibility: PPO can be applied to reinforcement learning problems, including LLM alignment.
Scenarios Where DPO is a Better Choice
1. Well-Aligned Preference Data:
- Scenario: When the training data and user preferences are closely aligned.
- Example: Fine-tuning a customer support chatbot where user feedback can directly inform and improve response quality.
2. Simpler, Narrow Tasks:
- Scenario: For tasks that are relatively simple and well-defined, the complexity of reinforcement learning is unnecessary.
- Example: Text classification tasks where user preferences on correct classifications can be easily gathered and applied.
3. Quick Adaptation to User Feedback:
- Scenario: When rapid adaptation to user feedback is required, the system must be updated frequently based on user interactions.
- Example: E-commerce recommendation systems that need to quickly adjust to changing user preferences and trends.
4. Limited Computational Resources:
- Scenario: In environments with constrained computational resources, efficient and less resource-intensive methods are preferred.
- Example: Startups or small enterprises developing domain-specific LLMs with limited access to large-scale computing infrastructure.
Scenarios Where PPO is a Better Choice
1. Complex Tasks Requiring Iterative Learning:
- Scenario: For tasks involving significant complexity and requiring iterative refinement through learning from diverse and dynamic interactions.
- Example: Code generation tasks where the model must learn from complex patterns and extensive feedback.
2. Structured Reward Signals:
- Scenario: When a well-defined reward structure is available, the task benefits from the exploration-exploitation balance inherent in reinforcement learning.
- Example: Game development where clear and structured reward signals guide the learning process effectively.
3. Stability and Robustness Requirements:
- Scenario: When stability and robustness are critical, the model must maintain performance across varied and unexpected conditions.
- Example: Autonomous driving systems where safety and reliability are paramount.
4. Long-Term Strategic Planning:
- Scenario: In scenarios requiring long-term planning and strategic decision-making the model must learn from the long-term consequences of actions.
- Example: Financial trading systems where the model must decide based on long-term trends and outcomes.
5. Large-Scale Deployments:
- Scenario: For large-scale deployments where the need for high performance and robustness justifies the computational cost.
- Example: General-purpose language models like GPT-3 and GPT-4 are used in diverse applications and environments.
Limitations of PPO Leading to the Development of DPO
Despite its widespread use and effectiveness, Proximal Policy Optimization (PPO), despite its widespread use and effectiveness, has several limitations that have motivated the exploration of alternative techniques like Direct Preference Optimization (DPO).
Here are the key limitations of PPO that have led to the development and adoption of DPO:
Complexity and Computational Cost
PPO involves complex policy and value networks, requiring significant computational resources for training. This complexity can lead to longer training times and higher operational costs.
Hyperparameter Sensitivity
PPO relies on several hyperparameters (e.g., clipping range, learning rate, discount factor), which need careful tuning to achieve optimal performance. Incorrect hyperparameter settings can lead to suboptimal policies or instability in learning.
Stability and Convergence Issues
While PPO aims to improve stability compared to earlier methods, it can still experience convergence issues, especially in highly dynamic or complex environments. Ensuring stable policy updates remains a challenge.
Reward Signal Dependence
PPO depends heavily on a well-defined reward signal to guide learning. When designing a suitable reward function is difficult or infeasible, PPO may need help to achieve desired outcomes.
Motivations for DPO
Direct Preference Optimization (DPO) addresses some of these limitations by offering a more straightforward approach to fine-tuning models based on user preferences:
Simplicity
DPO bypasses the complexity of policy and value networks, providing a more straighforward optimization process that directly adjusts model parameters based on user preferences.
Efficiency
DPO can be more computationally efficient and faster to train by directly leveraging user feedback, especially in tasks where preference data is readily available and well-aligned with the model’s outputs.
Alignment with Human Preferences
DPO focuses on aligning models with human values and preferences without requiring intricate reward modeling, making it suitable for tasks where user satisfaction is paramount.
Reduced Hyperparameter Dependence
DPO reduces the need for extensive hyperparameter tuning, simplifying the fine-tuning process and improving robustness across different tasks.
Conclusion
To harness the full potential of LLMs, careful alignment is key.
By understanding and leveraging the strengths of DPO and PPO, we can tailor these models to meet specific needs, whether it’s achieving rapid adaptation with DPO or tackling complex tasks with PPO.
As we’ve explored, each approach serves unique scenarios, but they both drive toward the same goal: creating safe, reliable, and user-centered AI solutions.
Which approach do you think best fits your needs for LLM alignment? For more on this topic, explore our related content or subscribe for updates on the latest in AI alignment techniques.
FAQS
Q1) What are DPO and PPO in the context of LLM alignment?
DPO (Direct Preference Optimization) and PPO (Proximal Policy Optimization) are two methods used to align Large Language Models (LLMs) with human preferences. DPO directly optimizes the model based on human feedback, while PPO is a reinforcement learning approach that iteratively improves the model's behavior.
Q2) What is the primary goal of both DPO and PPO?
The primary goal of both DPO and PPO is to align LLMs with human values and preferences, ensuring that they generate safe, helpful, and unbiased outputs.
Q3) Which is generally considered better, DPO or PPO?
Research suggests that PPO generally outperforms DPO in terms of overall alignment performance. However, the best choice depends on specific use cases and available resources.
Q4) What are the main differences between PPO and DPO?
- Complexity: PPO involves policy and value networks, iterative learning, and handling distribution shifts. DPO is simpler, focusing on direct updates based on user preferences.
- Robustness: PPO is robust to distribution shifts and performs well in complex tasks. DPO is sensitive to distribution shifts and is best suited for tasks where training and preference data are well-aligned.
- Efficiency: DPO is more computationally efficient and quicker to train than compared to PPO.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
