

Computer vision model for road damage detection, explained!


Road damage is an inconvenience and a safety hazard, severely affecting vehicle condition, driving comfort, and traffic safety. The traditional manual visual road inspection process is pricey, dangerous, exhausting, and cumbersome. Also, manual road inspection results are qualitative and subjective, as they depend entirely on the inspector’s personal experience. Therefore, there is an ever-increasing need for automated road inspection systems.
Brief Overview
- The condition assessment of concrete and asphalt civil infrastructures (e.g., tunnels, bridges, and pavements) is essential to ensure their serviceability while still providing maximum safety for the users. It also allows the government to allocate limited resources for infrastructure, maintenance and appraise long-term investment schemes.
- The detection and reparation of road damages (e.g., potholes, and cracks) is a crucial civil infrastructure maintenance task because they are not only an inconvenience but also a safety hazard, severely affecting vehicle condition, driving comfort, and traffic safety.
- Traditionally, road damages are regularly inspected (i.e., detected and localized) by certified inspectors or structural engineers. However, this manual visual inspection process is time-consuming, costly, exhausting, and dangerous. Moreover, manual visual inspection results are qualitative and subjective, as they depend entirely on the individual’s personal experience. Therefore, there is an ever increasing need for automated road inspection systems, developed based on cutting-edge computer vision and intelligence techniques. A computer-aided road inspection system typically consists of two major procedures : road data acquisition and road damage detection (i.e., recognition/segmentation and localization). The former typically employs active or passive sensors (e.g., laser scanners, infrared cameras and digital cameras to acquire road texture and/or spatial geometry, while the latter commonly uses 2-D image analysis/understanding algorithms such as image classification, semantic segmentation, object detection and/or 3-D road surface modeling algorithms to detect the damaged road areas.
Types of Road Damages
The five common types of road damages are :-
1. Crack : Road crack has a much larger depth when compared to its dimensions on the road surface, presenting a unique challenge to the imaging systems.
2. Spalling : Road spalling has similar lateral and depth magnitudes, and thus, the imaging systems designed specifically to measure this type of road damages should perform similarly in both lateral and depth directions.
3. Pothole : Road pothole is a considerably large structural road surface failure, measurable by an imaging setup with a large field of view.
4. Rutting : Road rutting is extremely shallow along its depth requiring a measurement system with high accuracy in the depth direction.
5. Shoving : Road shoving refers to a small bump on the road surface, which makes its profiling with some imaging systems difficult.
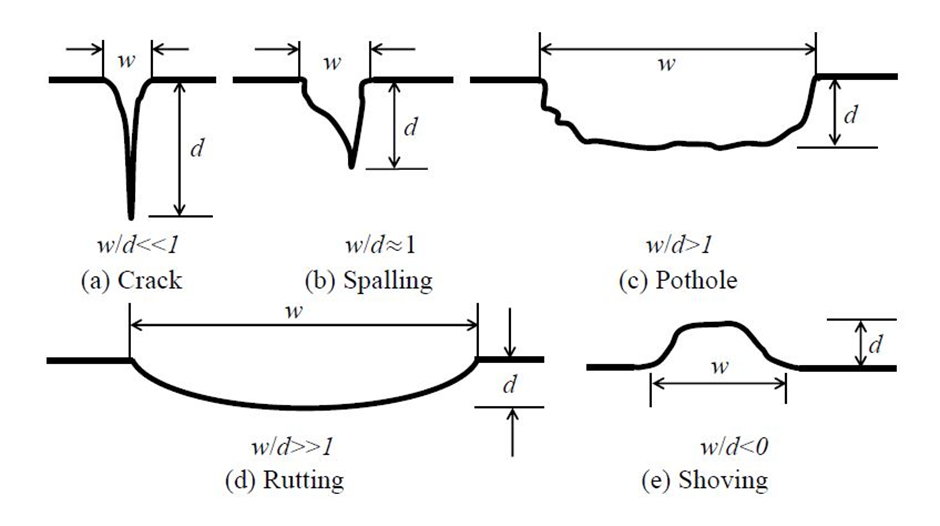
Img: Five common types of road damages. Note: 𝑤 and 𝑑 represent the lateral and depth magnitudes respectively.
Src: https://arxiv.org/pdf/2203.02355.pdf
Collection of Road Data
Earlier, 2-D imaging technologies (i.e., digital imaging or digital image acquisition) were used for road data collection. However, the spatial structure cannot always be explicitly illustrated in 2-D road images. Moreover, the image segmentation algorithms performing on either gray-scale or color road images can be severely affected by various factors, most notably by poor illumination conditions. Therefore, many researchers have resorted to 3-D imaging technologies, which are more feasible to overcome the disadvantages mentioned above and simultaneously provide an enhancement of road damage detection accuracy.
Laser scanning is a well-established imaging technology for accurate 3-D road geometry information acquisition. Laser scanners are developed based on trigonometric triangulation. The sensor is located at a known distance from the laser’s source, and therefore, accurate point measurements can be made by calculating the reflection angle of the laser light.
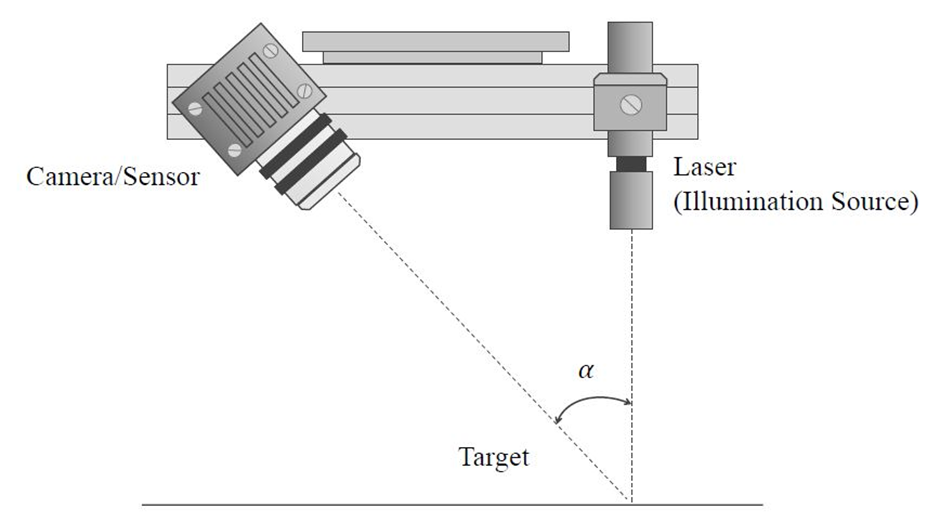
Img: Laser triangulation. The camera/sensor is located at a known distance from the laser’s illumination source. Therefore, accurate point measurements can be made by calculating the reflection angle of the laser light.
Src: https://arxiv.org/pdf/2203.02355.pdf
Auto-synchronized triangulation is a popular variation of classic trigonometric triangulation and has been widely utilized in laser scanners to capture the 3-D geometry information of near-flat road surfaces. However, laser scanners have to be mounted on dedicated road inspection vehicles for 3-D road data collection and such vehicles are not widely used because they involve high-end equipment and their long-term maintenance can be costly as well. An example of such vehicle is the Georgia Institute of Technology Sensing Vehicle.
Microsoft Kinect sensors were initially designed for the Xbox-360 motion sensing games and are typically equipped with an RGB camera, an infrared (IR) sensor/camera, an IR emitter, microphones, accelerometers and a tilt motor for motion tracking facility. But the working range of Microsoft Kinect sensors (800-4000 mm) makes them suitable for road imaging when mounted on a vehicle. However, it is also reported that these sensors greatly suffer from IR saturation in direct sunlight.
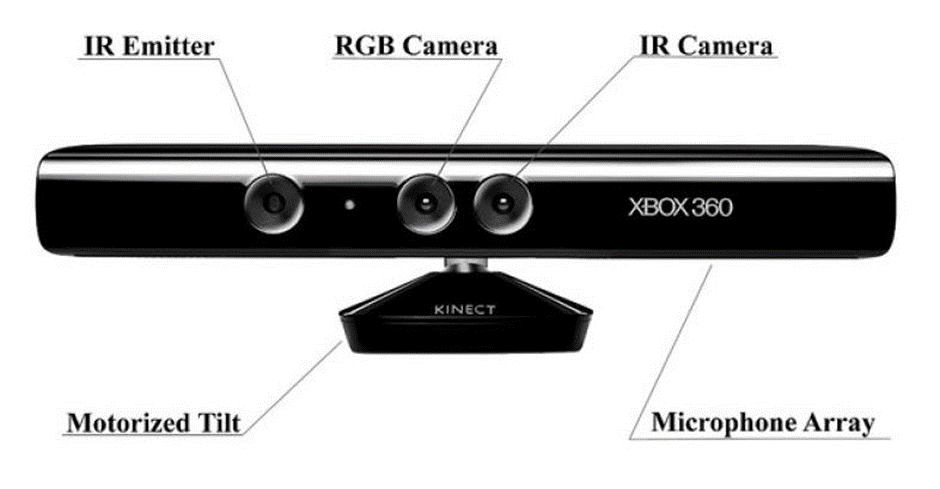
Img: Microsoft Kinect sensor
The 3-D geometry of a road surface can also be reconstructed using multiple images captured from different views. The theory behind this 3-D imaging technique is typically known as multi-view geometry. These images can be captured using a single movable camera or an array of synchronized cameras. In both cases, dense correspondence matching (DCM) between two consecutive road video frames or between two synchronized stereo road images is the key problem to be solved.
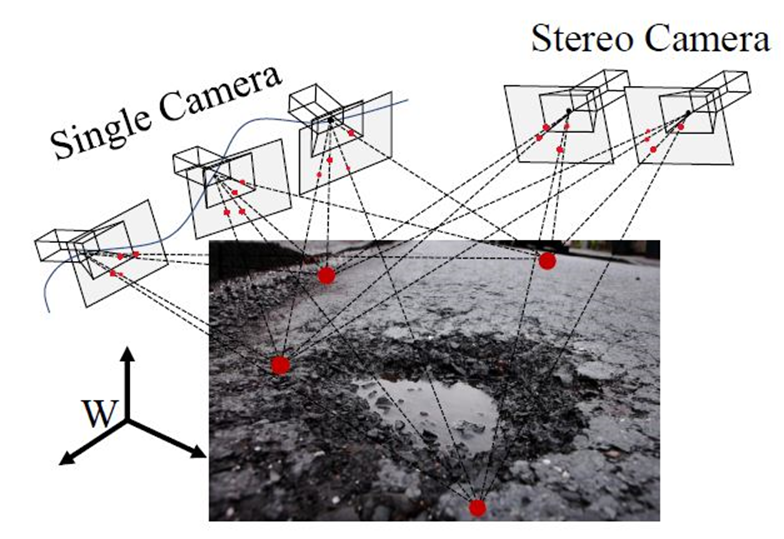
Img: 3-D road imaging with camera(s)
Structure from motion (SfM) and optical flow (OF) estimation are the two most commonly used techniques for monocular DCM, while stereo vision (also known as binocular vision, stereo matching, or disparity estimation) is typically employed for binocular DCM.
SfM methods estimate both camera poses and the 3-D points of interest from road images captured from multiple views, linked by a collection of visual features. They also leverage bundle adjustment algorithm to refine the estimated camera poses and 3-D point locations by minimizing a cost function known as total re-projection error.
OF describes the motion of pixels between consecutive frames of a video sequence.
Stereo vision acquires depth information by finding the horizontal positional differences (disparities) of the visual feature correspondence pairs between two synchronously captured road images. The traditional stereo vision algorithms formulate disparity estimation as either a local block matching problem or a global/semi-global energy minimization problem (solvable with various Markov random field-based optimization techniques), while data-driven algorithms typically solve stereo matching with convolutional neural networks (CNNs).
Despite the low cost of digital cameras, DCM accuracy is always affected by various factors, most notably by poor illumination conditions. Furthermore, it is always tricky for monocular DCM algorithms to recover the absolute scale of a 3-D road geometry model without considering the complicated environmental hypotheses. On the other hand, the feasibility of binocular DCM algorithms relies on the well-conducted stereo rig calibration and therefore, some systems incorporated stereo rig self-calibration functionalities to ensure that their captured stereo road images are always well-rectified.
In addition to the mentioned three common types of 3-D imaging technologies, shape from focus (SFF), shape from defocus (SFDF), shape from shading (SFS), photometric stereo, interferometry, structured light imaging and time-of-flight (ToF) are other alternatives for 3-D geometry reconstruction. However, they are not widely used for 3-D road data acquisition.
There are several road damage detection public datasets also available which are mainly created for crack or pothole detection.
Damage Detection in Roads
The SOTA road damage detection approaches are developed based on either 2-D image analysis/understanding or 3-D road surface modeling. The former methods typically utilize traditional image processing algorithms or modern CNNs to detect road damage, by performing either pixel-level image segmentation or instance-level object recognition on RGB or depth/disparity images. The latter approaches typically formulate the 3-D road point cloud as a planar/quadratic surface, whose coefficients can be obtained by performing robust surface modeling. The damaged road areas can be detected by comparing the difference between the actual and modeled road surfaces.
2-D Image Analysis/Understanding-Based Approaches
# Traditional image analysis-based approaches
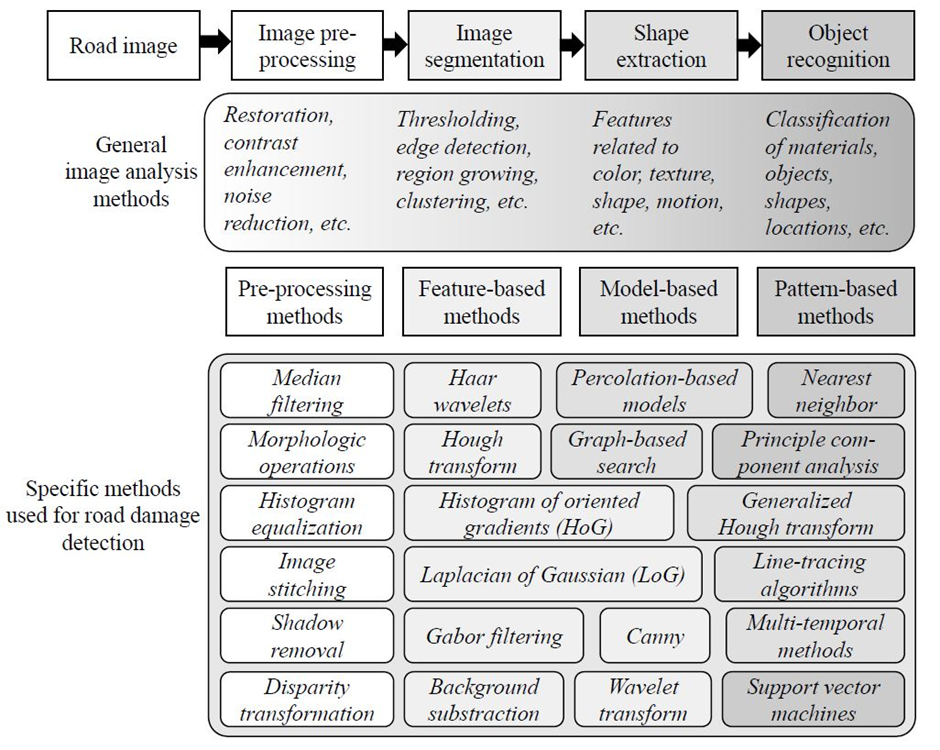
Img: An overview of the traditional image analysis-based road damage detection approaches.
Src: https://arxiv.org/pdf/2203.02355.pdf
· These approaches typically consist of four main procedures:
1. Image pre-processing
2. Image segmentation
3. Shape extraction
4. Object recognition
· “Image-based pothole detection system for its service and road management system” by S.-K. Ryu, T. Kim, and Y.-R. Kim is a classic example of this algorithm type. It first uses a histogram-based thresholding algorithm to segment (binarize) the input gray-scale road images. The segmented road images are then processed with a median filter and a morphology operation to further reduce the redundant noise. Finally, the damaged road areas are extracted by analyzing a pixel intensity histogram.
· Additionally, C. Koch and I. Brilakis, solved road pothole detection with similar techniques in their research paper “Pothole detection in asphalt pavement images”. It first applies the triangle algorithm to segment gray-scale road images. An ellipse then models the boundary of an extracted potential road pothole area. Finally, the image texture within the ellipse is compared with the undamaged road area texture. If the former is coarser than the latter, the ellipse is considered to be a pothole.
· However, both color and gray-scale image segmentation techniques are severely affected by various factors, most notably by poor illumination conditions. Therefore, some researchers performed segmentation on depth/disparity images, which has shown to achieve better performance in terms of separating damaged and undamaged road areas. For instance, in “Unsupervised approach for autonomous pavement defect detection and quantification using an inexpensive depth sensor”, M. R. Jahanshahi acquires the depth images of pavements using a Microsoft Kinect sensor. The depth images are then segmented using wavelet transform algorithm. For effective operation, the Microsoft Kinect sensor has to be mounted perpendicularly to the pavements.
· In 2018, Y.-C. Tsai and A. Chatterjee proposed to detect road potholes from depth images acquired by a highly accurate laser scanner mounted on a Georgia Institute of Technology sensing vehicle in their research paper “Pothole detection and classification using 3d technology and watershed method”. The depth images are first processed with a high-pass filter so that the depth values of the undamaged road pixels become similar. The processed depth image is then segmented using watershed method for road pothole detection.
· Ever since the concept of “v-disparity map” was presented in the research paper “Real time obstacle detection in stereovision on non flat road geometry through v-disparity representation” by R. Labayrade, D. Aubert, and J.-P. Tarel, disparity image segmentation has become a common algorithm used for object detection.
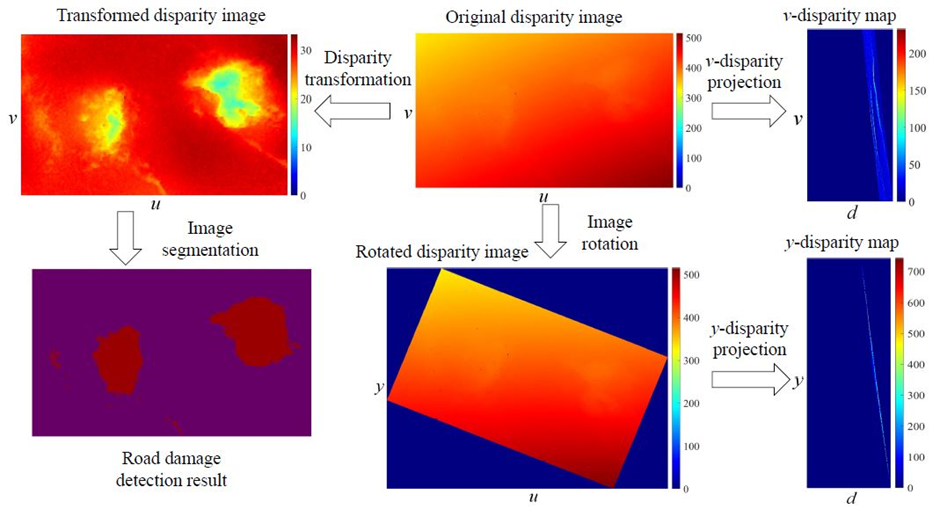
Img: Disparity transformation - The stereo rig roll angle (Φ) is non-zero, and therefore, the disparity values in the original disparity image change gradually in the horizontal direction. By rotating the original disparity image by Φ, the disparity values on each row become more uniform. Using Φ and K (which stores two road disparity projection model coefficients (𝜅; 𝜘)), the original disparity image can be transformed, where the damaged road areas become highly distinguishable. Finally, the transformed disparity image can be segmented using common image segmentation algorithms for pixel-level road damage detection.
Src: https://arxiv.org/pdf/2203.02355.pdf
· The road damages become highly distinguishable after disparity transformation, and they can be detected with common image segmentation techniques. For instance, in his research paper “Real-time dense stereo embedded in a uav for road inspection”, R. Fan applies superpixel clustering to group the transformed disparities into a set of perceptually meaningful regions, which are then utilized to replace the rigid pixel grid structure. The damaged road areas can then be segmented by selecting the superpixels whose transformed disparity values are lower than those of the healthy road areas.
# CNN-based approaches
On the other hand, the (Convolutional Neural Network) CNN-based approaches typically address road damage detection in an end-to-end manner with image classification, semantic segmentation, or object detection networks.
1. Image Classification based approaches :-
· Since 2012, various CNNs have been proposed to solve image classification problems. AlexNet is one of the modern CNNs that pushed image classification accuracy significantly. VGG architectures improved over AlexNet by increasing the network depth, which enabled them to learn more complicated image features. However, VGG architectures consist of hundreds of millions of parameters, making them very memory-consuming.
· GoogLeNet (also known as Inception-v1) and Inception-v3 go deeper in parallel paths with different receptive field sizes, so that the Inception module can act as a multi-level image feature extractor. Compared to VGG architectures, GoogLeNet and Inception-v3 have lower computational complexity.
· However, with the increase of network depth, accuracy gets saturated and then degrades rapidly, due to vanishing gradients. To tackle this problem, K. He, X. Zhang, S. Ren and J. Sun introduces residual neural network (ResNet) in their research paper, “Deep residual learning for image recognition”. It is comprised of a stack of building blocks, each of which utilizes identity mapping (skip connection) to add the output from the previous layer to the layer ahead. This helps gradients propagate.
· In recent years, researchers have turned their focus to light-weight CNNs, which can be embedded in mobile devices to perform real-time image classification. MobileNet-v2, ShuffleNet-v2, and MNASNet are three of the most popular CNNs of this kind.
· MobileNet-v2 mainly introduces the inverted residual and linear bottleneck layer, which allows high accuracy and efficiency in mobile vision applications.
· The above-mentioned image classification networks have been widely used to detect, i.e., recognize and localize road cracks as the visual features learned by CNNs can replace the traditional hand-crafted features. For example, in 2016, L. Zhang proposed a robust road crack detection network in his research paper “Road crack detection using deep convolutional neural network”. An RGB road image is fed into a CNN consisting of a collection of convolutional layers. The learned visual feature is then connected with a fully connected (FC) layer to produce a scalar indicating the probability that the image contains road cracks. Similarly, in 2019, R. Fan, M. J. Bocus, Y. Zhu, J. Jiao, L. Wang, F. Ma, S. Cheng, and M. Liu proposed a deep CNN in their research paper “Road crack detection using deep convolutional neural network and adaptive thresholding”, which is capable of classifying road images as either positive or negative. The road images are also segmented using an image thresholding method for pixel-level road crack detection.
· In 2019, Y. Hu and T. Furukawa proposed a self-supervised monocular road damage detection algorithm in their research paper “A self-supervised learning technique for road defects detection based on monocular three-dimensional reconstruction”, which can not only reconstruct the 3-D road geometry models with multi-view images captured by a single movable camera (based on the hypothesis that the road surface is nearly planar) but also classify RGB road images as either damaged or undamaged with a classification CNN (the images used for training was automatically annotated via a 3-D road point cloud thresholding algorithm).
· Recently, J. Fan conducted a comprehensive comparison among 30 SOTA image classification CNNs for road crack detection. The qualitative and quantitative experimental results suggest that road crack detection is not a challenging image classification task. The performances achieved by these deep CNNs are very similar. Furthermore, learning road crack detection does not require a large amount of training data. It is demonstrated that 10,000 images are sufficient to train a well-performing CNN. The findings can be found in detail his research paper “Deep convolutional neural networks for road crack detection: Qualitative and quantitative comparisons”.
· However, the pre-trained CNNs typically perform unsatisfactorily on additional test sets. Therefore, unsupervised domain adaptation capable of mapping two different domains becomes a hot research topic that requires more attention
· Finally, explainable AI algorithms, such as Grad-CAM++, become essential for image classification applications in terms of understanding CNN’s decision-making.
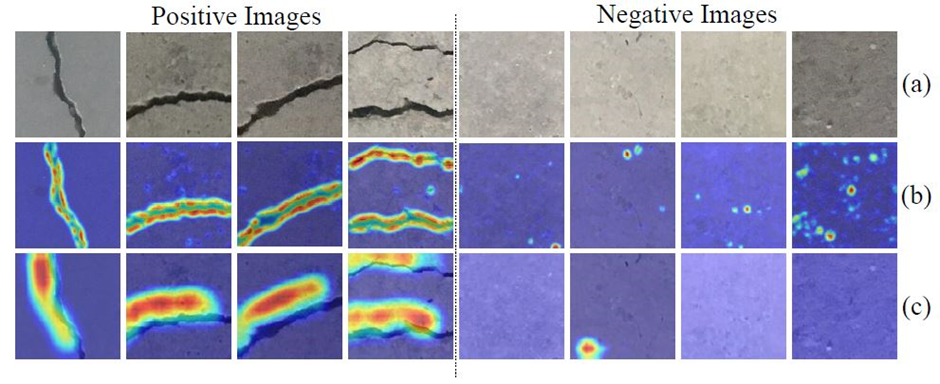
Img: Examples of Grad-CAM++ results: (a) road crack images (b) the class activation maps of ResNet-50 (c) the class activation maps of SENet. The warmer the color is, the more attention the CNN pays.
Src: https://arxiv.org/pdf/2203.02355.pdf
2. Object detection based approaches :-
· Region-based CNN (R-CNN) and you only look once (YOLO) are two representative groups of modern deep learning-based object detection algorithms.
· The SOTA image classification CNNs can classify an input image into a specific category. However, we sometimes hope to know the exact location of a particular object in the image, which requires the CNNs to learn bounding boxes around the objects of interest. A naive but straightforward way to achieve this objective is to classify a collection of patches (split from the original image) as positive (the object present in the patch) or negative (the object absent from the patch). However, the problem with this approach is that the objects of interest can have different spatial locations within the image and different aspect ratios. Therefore, it is usually necessary but costly for this approach to select many regions of interest (RoIs).
· To solve this dilemma, R-CNN utilizes a selective search algorithm to extract only 2000 RoIs (referred to as region proposals). Such RoIs are then fed into a classification CNN to extract visual features connected by a support vector machine (SVM) to produce their categories.

Img: R-CNN Architecture
Src: https://arxiv.org/pdf/2203.02355.pdf
· In 2015, Fast R-CNN was introduced as a faster object detection algorithm and is based on R-CNN. Instead of feeding region proposals to the classification CNN, Fast RCNN directly feeds the original image to the CNN and outputs a convolutional feature map (CFM). The region proposals are identified from the CFM using selective search, which are then reshaped into a fixed size with an RoI pooling layer before being fed into a fully connected layer. A softmax layer is subsequently used to predict the region proposals’ classes.
· However, both R-CNN and Fast R-CNN utilize a selective search algorithm to determine region proposals, which is slow and time-consuming. To overcome this disadvantage, Faster R-CNN is proposed, which employs a network to learn the region proposals. Faster R-CNN is ~250 times faster than R-CNN and ~11 times faster than Fast R-CNN.
· On the other hand, the YOLO series are very different from the R-CNN series.
· YOLOv1 formulates object detection as a regression problem. It first splits an image into an 𝑆x𝑆 grid, from which 𝐵 bounding boxes are selected. The network then outputs class probabilities and offset values for these bounding boxes.
· Since YOLOv1 makes a significant number of localization errors and its achieved recall is relatively low, YOLOv2 was proposed to bring various improvements on YOLOv1 like:-
a. It adds batch normalization on all the convolutional layers.
b. It fine-tunes the classification network at the full 448x448 resolution.
c. It removes the fully connected layers from YOLOv1 and uses anchor boxes to predict bounding boxes.
· In 2018, several tweaks were made to further improve YOLOv2 and YOLOv3 was introduced.
· As for the application of the mentioned object detectors in road damage detection:
a. In 2018, L. K. Suong and J. Kwon trained a YOLOv2 object detector to recognize road potholes. The findings are mentioned in detail in their research paper “Detection of potholes using a deep convolutional neural network”.
b. W. Wang, B. Wu, S. Yang, and Z. Wang utilized a Faster R-CNN to achieve the same objective. It is discussed in detail in the research paper “Road damage detection and classification with faster r-cnn”.
c. In 2019, E. N. Ukhwah, E. M. Yuniarno, and Y. K. Suprapto utilized three different YOLOv3 architectures to detect road potholes. You can read in detail about it in the research paper “Asphalt pavement pothole detection using deep learning method based on yolo neural network”.
d. In 2020, N. Camilleri and T. Gatt leveraged YOLOv3 to detect road potholes from RGB images captured by a smartphone mounted in a car. The algorithm was successfully implemented on a Raspberry Pi 2 Model B in TensorFlow. The reported best mean average precision (mAP) was 68.83% and inference time was 10 ms. It is discussed in detail in the research paper “Detecting road potholes using computer vision techniques”.
e. Recently, A. Dhiman and R. Klette compared the performances of YOLOv2 and Faster R-CNN for road damage detection in their research paper “Pothole detection using computer vision and learning”.
· However, these approaches typically employ a well-developed object detection network to detect road damages, without modifications designed specifically for this task. Furthermore, these object detectors can only provide instance-level predictions instead of pixel-level predictions. Therefore, in recent years, semantic image segmentation has become a more desirable technique for road damage detection.
3. Semantic segmentation-based approaches :-
· Semantic image segmentation aims at assigning each image pixel with a category. It has been widely used for road damage detection in recent years. According to the number of input vision data types, the SOTA semantic image segmentation networks can be grouped into two categories:
a. Single-modal : Inputs only one type of vision data, such as RGB images or depth images.
b. Data-fusion : Typically learns visual features from different types of vision data, such as RGB images and transformed disparity images or RGB images and surface normal information.
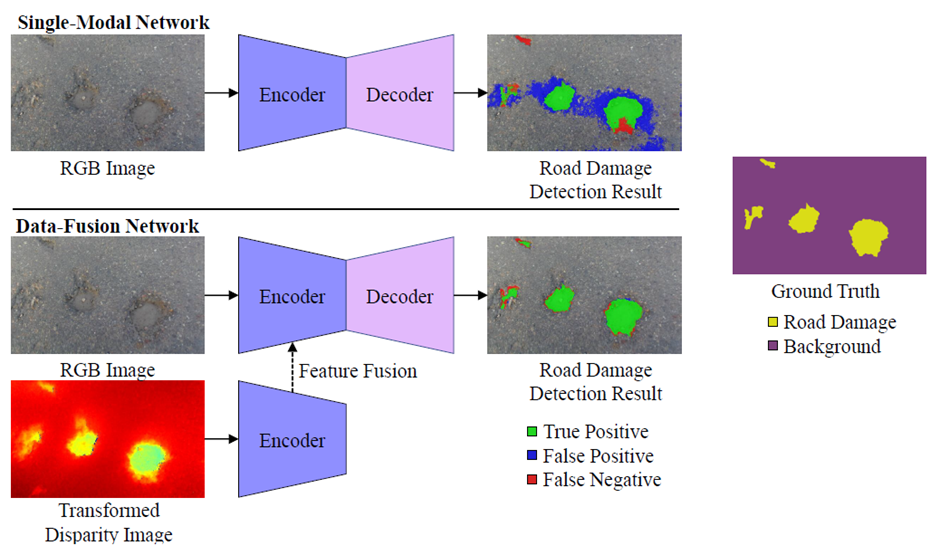
Img: Single-modal semantic image segmentation v.s. data-fusion semantic image segmentation for road pothole detection.
Src: https://arxiv.org/pdf/2203.02355.pdf
· Fully convolutional network (FCN) was the first end-to-end single-modal CNN designed for semantic image segmentation.
· Seg- Net was the first to use the encoder-decoder architecture, which is widely used in current networks. It consists of an encoder network, a corresponding decoder network, and a final pixel-wise classification layer.
· U-Net also employs an encoder-decoder architecture. It adds skip connections between the encoder and decoder to smoothen the gradient flow and restore the object locations.
· Furthermore, PSPNet, DeepLabv3+ and DenseASPP leverage a pyramid pooling module to extract context information for better segmentation performance.
· Additionally, GSCNN employs a two-branch framework consisting of:
a. A shape branch
b. A regular branch,
which can effectively improve the semantic predictions on the boundaries.
· On the other hand, data-fusion networks improve semantic segmentation accuracy by extracting and fusing the features from multimodalities of visual information. For instance, FuseNet and depth-aware CNN adopt the popular encoder-decoder architecture, but employ different operations to fuse the feature maps obtained from the RGB and depth branches. SNE-RoadSeg and SNERoadSeg+ extract and fuse the visual features from RGB images and surface normal information (translated from depth/disparity images in an end-to-end manner) for road segmentation.
· Back to the road inspection applications, researchers have already employed both single-modal and data-fusion semantic image segmentation networks to detect road damages/anomalies (the approaches designed to detect road damages can also be utilized to detect road anomalies, as these two types of objects are below and above the road, respectively).
· In 2020, R. Fan with his team proposed a novel attention aggregation (AA) framework3 in his research paper “We learn better road pothole detection: from attention aggregation to adversarial domain adaptation”, making the most of three different attention modules:
a. Channel attention module (CAM).
b. Position attention module (PAM).
c. Dual attention module (DAM).
Furthermore, R. Fan introduced an effective training set augmentation technique based on adversarial domain adaptation (developed based on CycleGAN, where the synthetic road RGB images and transformed road disparity (or inverse depth) images are generated to enhance the training of semantic segmentation networks.
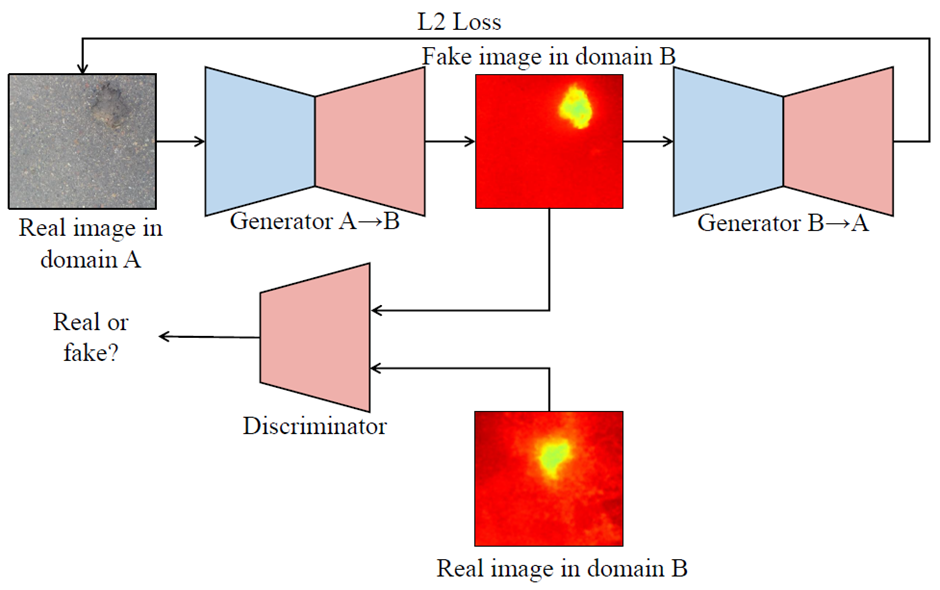
Img: CycleGAN architecture.
Src: https://arxiv.org/pdf/2203.02355.pdf
· Similar to R. Fan, J. Fan also introduced a road pothole detection approach based on single-modal semantic image segmentation in his research paper “Multi-scale feature fusion: Learning better semantic segmentation for road pothole detection” in 2021. Its network architecture is developed based on DeepLabv3.
· Recently, H. Wang, R. Fan, Y. Sun, and M. Liu developed a data-fusion semantic segmentation CNN for road anomaly detection and also conducted a comprehensive comparison of data fusion performance with respect to six different modalities of visual features, including:
a. RGB images.
b. Disparity images.
d. Elevation images.
e. HHA images (having three channels):
i. Disparity.
ii. Height of the pixels.
iii. Angle between the normals and gravity vector based on the estimated ground.
f. Transformed disparity images.
The experimental results demonstrated that the transformed disparity image is the most informative visual feature. The findings are discussed in detail in their research paper “Dynamic fusion module evolves drivable area and road anomaly detection: A benchmark and algorithms”.
3-D Road Surface Modeling-Based Approaches
· In 2020, R. Ravi, D. Bullock, and A. Habib proposed a LiDAR-based road inspection system in their research paper “Highway and airport runway pavement inspection using mobile lidar”, where the 3-D road points are classified as damaged and undamaged by comparing their distances to the best-fitting planar 3-D road surface.

Img: An example of 3-D road pothole cloud acquired using the stereo vision technique presented in research paper “Road surface 3d reconstruction based on dense subpixel disparity map estimation” by R. Fan. The accuracy of the 3-D road point cloud is 3 mm.
Src: https://arxiv.org/pdf/2203.02355.pdf
· Nevertheless, 3-D road surface modeling is very sensitive to noise. Hence, U. Ozgunalp and R. Fan incorporates the surface normal information into the road surface modeling process to eliminate outliers in their research papers “Vision based lane detection for intelligent vehicles” and “Real-time computer stereo vision for automotive applications” respectively.
· Furthermore, R. Fan also employs random sample consensus (RANSAC) to further improve its robustness.
Blended Approaches
• In 2012, G. Jog, C. Koch, M. Golparvar-Fard, and I. Brilakis introduced a hybrid road pothole detection approach based on 2-D object recognition and 3-D road geometry reconstruction. The road video frames acquired by a high definition (HD) camera were first utilized to detect (recognize) road potholes. Simultaneously, the same video was also employed for sparse 3-D road geometry reconstruction. By analyzing such multi-modal road inspection results, the potholes were accurately detected. Such a hybrid method dramatically reduces the incorrectly detected road potholes. It is discussed in detail in their research paper “Pothole properties measurement through visual 2d recognition and 3d reconstruction”.
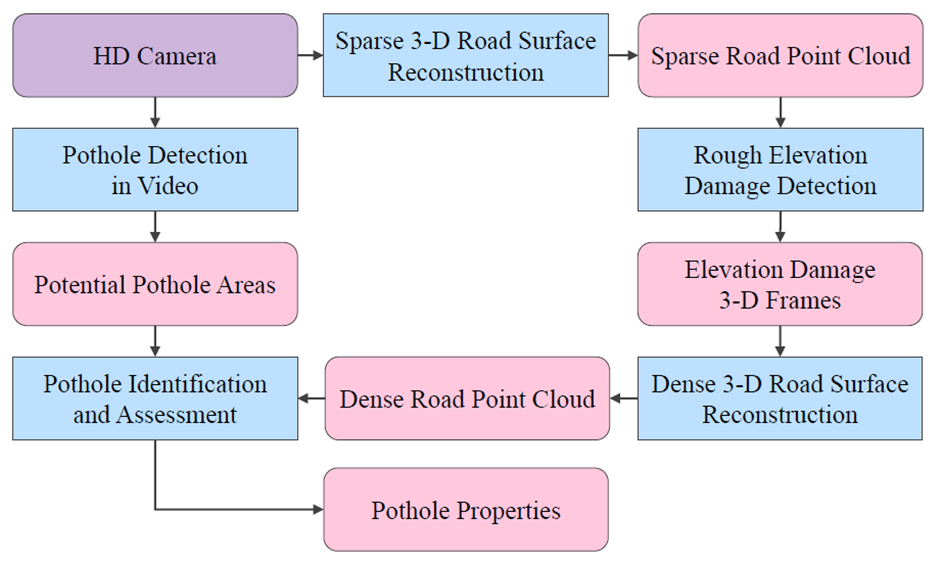
Img: The block diagram of the method proposed by G. Jog, C. Koch, M. Golparvar-Fard, and I. Brilakis
Src: https://arxiv.org/pdf/2203.02355.pdf
• In 2014, C. Yuan and H. Cai also introduced a hybrid road damage detection approach which can effectively recognize and measure road damages. As discussed in their research paper “Automatic detection of pavement surface defects using consumer depth camera”, this algorithm requires two modalities of road data:
1. 2-D gray-scale/RGB road images
2. 3-D road point clouds.
The road images are up-sampled by matching them with higher resolution images. The road pothole/crack edges are then extracted from the up-sampled images. On the other hand, the road point clouds are denoised through constrained convex optimization to measure rutting/pothole depth. Finally, the extracted pothole/crack edges and measured rutting/pothole depth are combined for road damage quantification.
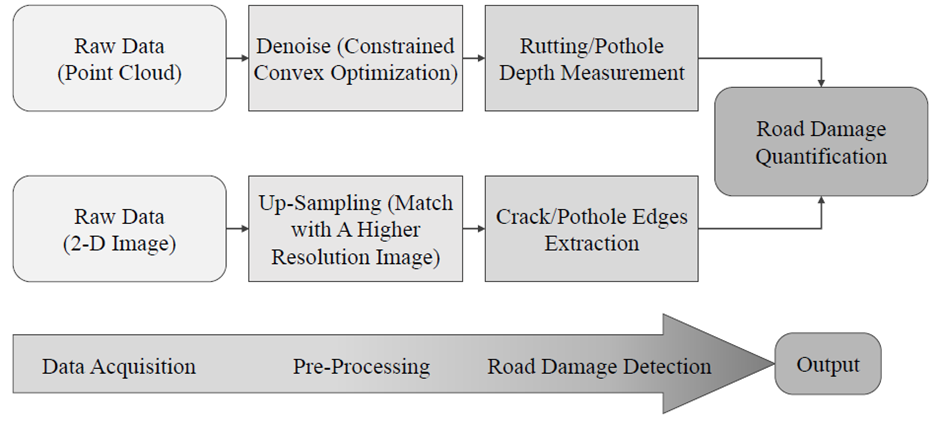
Img: The block diagram of the road damage detection method proposed by C. Yuan and H. Cai
Src: https://arxiv.org/pdf/2203.02355.pdf
• In 2017, B.-h. Kang and S.-i. Choi proposed an automated road pothole detection system based on the analysis of 2-D LiDAR data and RGB road images in their research paper “Pothole detection system using 2d lidar and camera”. This hybrid system has the advantage of not being affected by electromagnetic waves and poor road conditions. The 2-D LiDAR data provide road profile information, while the RGB road images provide road texture information. To obtain a highly accurate and large road area, this system uses two LiDARs. Such a hybrid system can combine the advantages of different sources of vision data to improve the overall road pothole detection accuracy.
• In 2019, R. Fan with his team also introduced a hybrid framework for road pothole detection in his research paper “Pothole detection based on disparity transformation and road surface modeling”. It first applies disparity transformation and Otsu’s thresholding methods to extract potential undamaged road areas. In the next step, a quadratic surface was fitted to the original disparity image, where the RANSAC algorithm was employed to enhance the surface fitting robustness. Potholes can be successfully detected by comparing the actual and fitted disparity images. This hybrid framework uses both 2-D image processing and 3-D road surface modeling algorithms, greatly improving the road pothole detection performance.
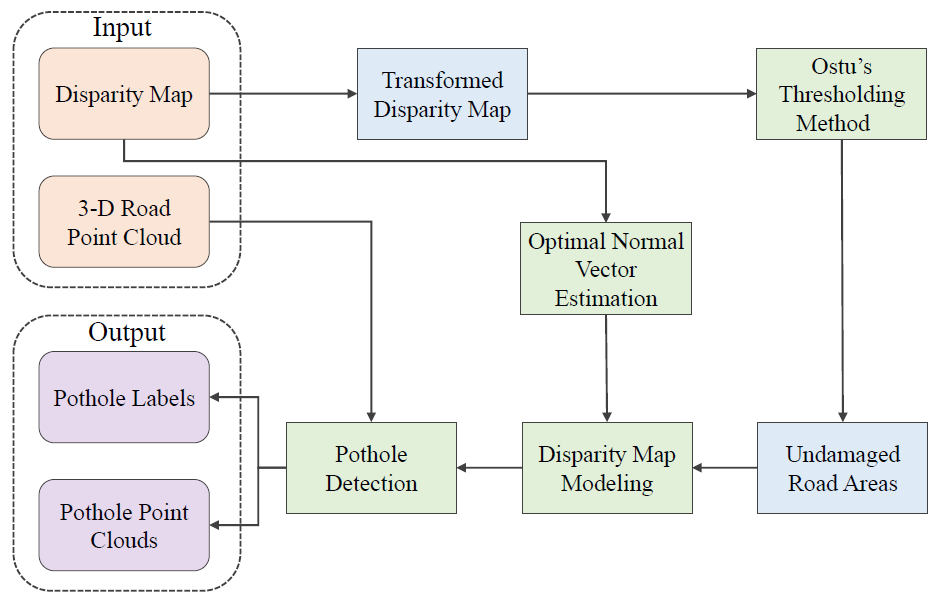
Img: The road pothole detection workflow proposed by R. Fan
Src: https://arxiv.org/pdf/2203.02355.pdf
Parallel Computing Architecture
• Graphics processing unit (GPU) was initially developed to accelerate graphics processing. It has now evolved as a specialized processing core, significantly speeding up computational processes. GPUs have unique parallel computing architectures and they can be used for a wide range of massively distributed computational processes, such as graphics rendering, supercomputing, weather forecasting, and autonomous driving.
• The main advantage of GPUs is its massively parallel architecture.
• Parallelism is the basis of high-performance computing. With the continuous improvement in computing power and parallelism programmability, GPUs have been employed in an increasing number of deep learning applications, such as road condition assessment with semantic segmentation networks, to accelerate model training and inference.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
