

Chronic Kidney Disease Detection Using Machine Learning


Table of Contents
Introduction
Kidney disease is a critical health issue affecting millions of individuals worldwide. The kidneys play a vital role in filtering waste and excess fluids from the blood, regulating blood pressure, and maintaining electrolyte balance.
However, various factors, such as hypertension and diabetes, can lead to chronic kidney disease (CKD) or even kidney failure if left untreated.
Early detection of kidney disease is important for timely intervention and effective management to prevent its progression to more severe stages.
Machine learning (ML) is a promising tool in healthcare for its ability to analyze large datasets, identify complex patterns, and make predictions based on input data.
Traditionally, diagnosis has relied on clinical markers such as serum, creatinine levels, and glomerular filtration rate (GFR). However, these methods may not always provide timely detection, and there is a growing need for efficient and accurate diagnostic approaches.
In this blog, we will be predicting whether a person has kidney disease or not using the Kaggle Dataset.
We will be using a random forest classifier algorithm for building our machine learning model.
Steps for model building
- We will first import the required libraries.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns2. Next, we will be reading the dataset (CSV file) using the Pandas library and checking the dataframe.
df_kidney = pd.read_csv('kidney_disease.csv')
df_kidney.head()
3. Now, we will be checking the features and the data type for each feature present in the dataset.
df_heart.info()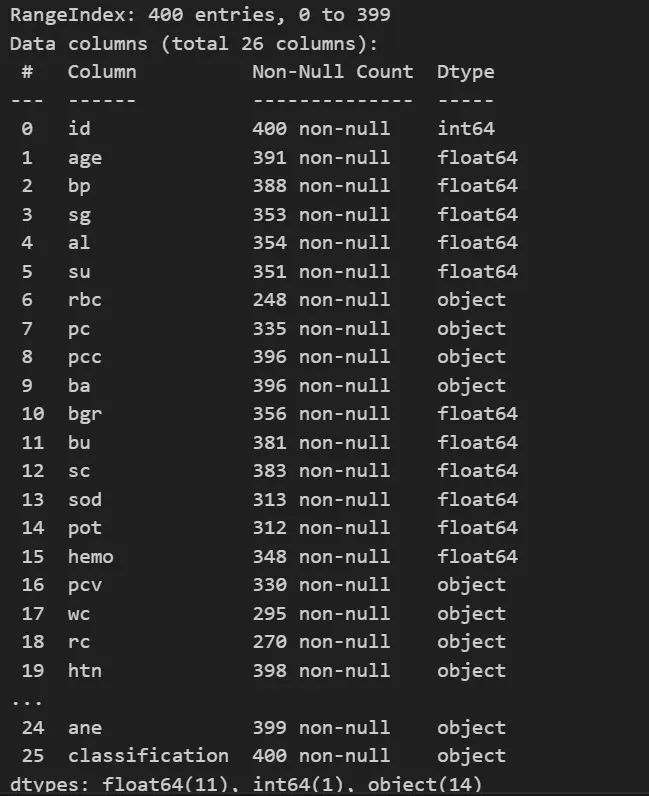
We can see from the above output that some of the features are also of the type object. For building the machine learning model, we need all the features to be in numerical format.
4. Next, we will convert all the object type to numerical format using the label encoder.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
for col in data.columns:
if data[col].dtype == object:
data[col] = le.fit_transform(data[col])
data.info()5. Now Let’s check our target variable, i.e classification column.
df_kidney['classification'].value_counts()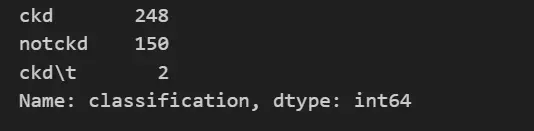
We can see from the above output that there are three categories out of which ‘ckd\t’ is wrongly mentioned, so we will be dropping its value count, which is very low.
6. Let’s drop the ckd\t category which is not required.
df_kidney = df_kidney[df_kidney['classification'] != 'ckd\t']
df_kidney['classification'].value_counts()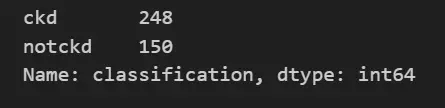
7. Now we will drop the id column as it is not required, and we will also be removing any duplicate values from our dataset.
df_kidney = df_kidney.drop(['id'], axis=1)
df_kidney = df_kidney.drop_duplicates()
df_kidney.info()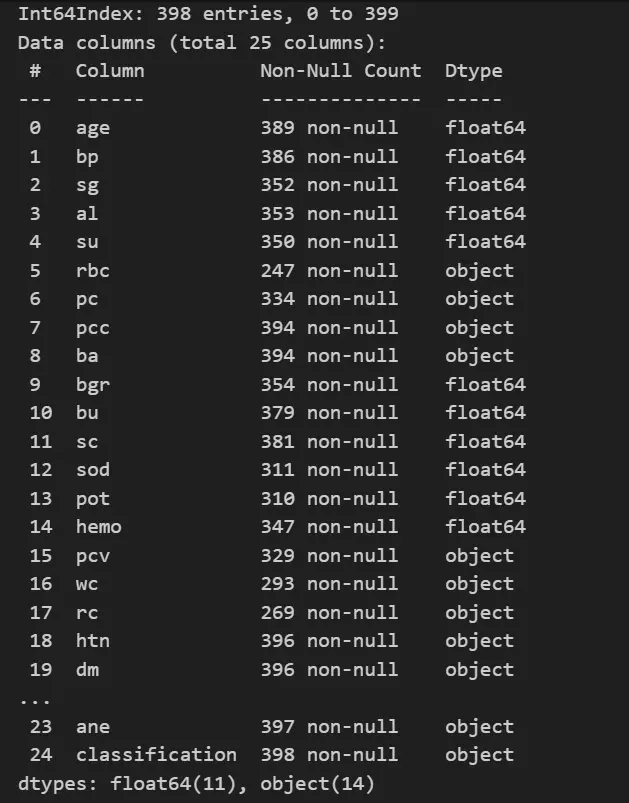
8. Now we will be checking for any NULL values present in our dataset.
df_kidney.isnull().sum()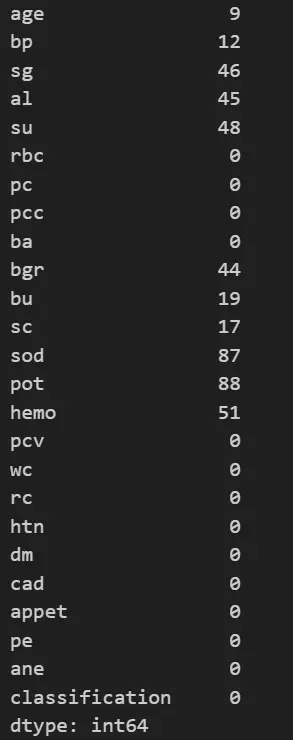
As we can see, our dataset contains many null values, so we will not be dropping them; instead, we will be imputing them using the KNNImputer method.
9. We will impute all the null values using the KNNImputer.
from sklearn.impute import KNNImputer
imp = KNNImputer(n_neighbors=5) )
K_data = imp.fit_transform(df_kidney)
K_data = pd.DataFrame(K_data, columns=df_kidney.columns)
10. Now Let’s plot a heatmap to see the relationship between the variables.
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 20))
sns.heatmap(K_data.corr(), annot=True, cmap='YlOrRd')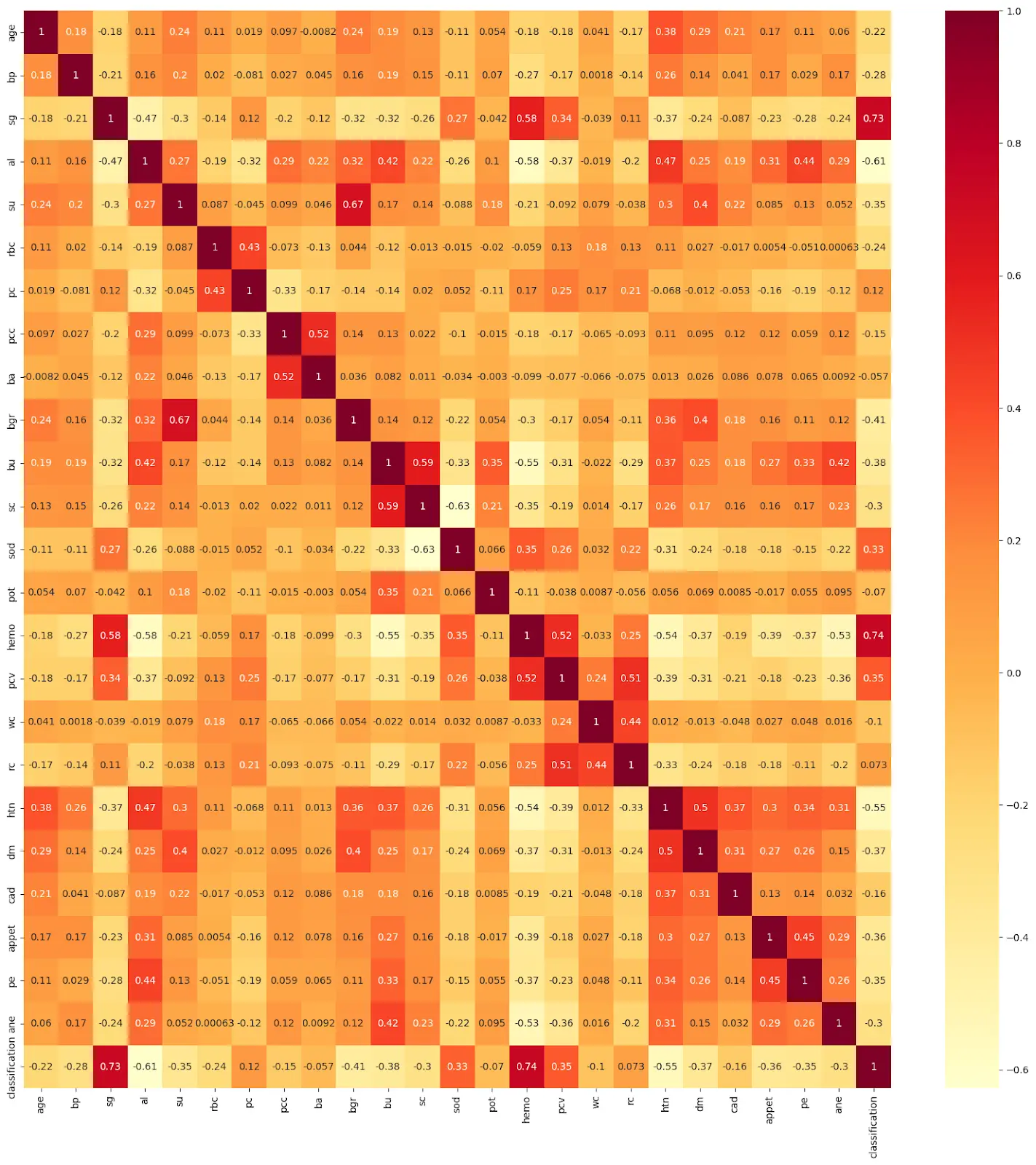
11. Now let’s assign all the features to the X variable and the target variable to 'Y'. We will further use StandardScaler to scale the features so that they have the same scale and avoid any bias.
from sklearn.preprocessing import StandardScaler
X = K_data.drop(['classification'], axis=1)
Y = K_data['classification']
x = StandardScaler().fit_transform(X)12. Now Let’s split the dataset in the ratio of 70:30 train and test.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,Y,test_size=0.3)13. We will be using random forest classifier to build our machine learning model.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
model = RandomForestClassifier()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Classification Report:")
print(classification_report(y_test, y_pred))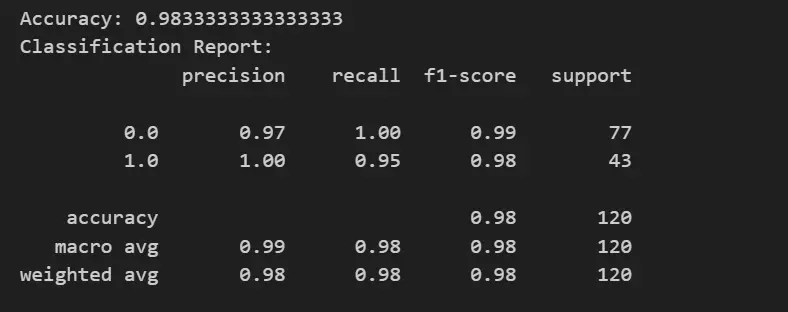
Our Model has achieved an accuracy of 98.33%
Conclusion
In conclusion, the application of machine learning techniques in the detection of kidney disease holds significant promise for improving patient care and outcomes. By harnessing the capabilities of ML algorithms to analyze vast amounts of data, identify patterns, and make accurate predictions. It would allow doctors to diagnose kidney disease at an early stage and start treatment as soon as possible.
Frequently Asked Questions
Q1) What is the role of machine learning in kidney disease detection?
Machine learning algorithms can analyze large datasets to identify patterns and make predictions based on various factors related to kidney function. They can assist in early detection, risk assessment, and personalized treatment strategies for individuals with kidney disease.
Q2) What machine learning techniques are used to predict chronic kidney disease risk?
Some of the main machine learning algorithms used to predict the occurrence of CKD are Naïve Bayes, decision trees, K-nearest neighbor, random forests, and support vector machines.
Q3) Why is predicting kidney disease important?
Predicting kidney disease is crucial for several reasons. Early detection allows for timely intervention and treatment, which can significantly slow down the progression of the disease, reduce complications, and improve patient outcomes.

Simplify Your Data Annotation Workflow With Proven Strategies
Download the Free Guide